Neuromorphic Algorithms Mapped To In-Memory Computing Substrates
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
Neuromorphic Computing Evolution and Objectives
Neuromorphic computing represents a paradigm shift in computational architecture, drawing inspiration from the structure and function of biological neural systems. This field has evolved significantly since its conceptual inception in the late 1980s when Carver Mead first proposed the idea of using electronic circuits to mimic neurobiological architectures. The evolution trajectory has been marked by several key milestones, from early analog VLSI implementations to today's sophisticated neuromorphic processors that integrate memory and computation.
The fundamental premise of neuromorphic computing lies in its departure from the traditional von Neumann architecture, which separates memory and processing units. This separation creates a bottleneck in data transfer, limiting computational efficiency. Neuromorphic systems, conversely, distribute both memory and computation throughout the architecture, similar to the brain's neural networks, enabling parallel processing and reducing energy consumption significantly.
Recent years have witnessed accelerated development in neuromorphic hardware platforms, including IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida. These platforms demonstrate the growing maturity of the field, transitioning from purely academic research to commercially viable solutions. The integration with in-memory computing substrates represents the latest evolutionary step, addressing the critical challenge of energy efficiency in neural network implementations.
The primary objectives of mapping neuromorphic algorithms to in-memory computing substrates are multifaceted. First, there is the goal of achieving unprecedented energy efficiency, potentially reducing power consumption by orders of magnitude compared to conventional computing systems. This is particularly crucial for edge computing applications where power constraints are significant.
Second, neuromorphic computing aims to enable real-time processing of complex, unstructured data streams—a capability essential for applications like autonomous vehicles, advanced robotics, and intelligent sensors. The inherent parallelism of neuromorphic architectures makes them ideally suited for these tasks.
Third, there is the objective of developing systems capable of unsupervised learning and adaptation, mirroring the brain's plasticity. This would allow computing systems to evolve their functionality based on experience, without explicit programming for every possible scenario.
Finally, the field aspires to bridge the gap between artificial neural networks and biological understanding, potentially offering insights into cognitive processes while simultaneously advancing artificial intelligence capabilities. This bidirectional flow of knowledge between neuroscience and computing represents one of the most promising aspects of neuromorphic research.
The fundamental premise of neuromorphic computing lies in its departure from the traditional von Neumann architecture, which separates memory and processing units. This separation creates a bottleneck in data transfer, limiting computational efficiency. Neuromorphic systems, conversely, distribute both memory and computation throughout the architecture, similar to the brain's neural networks, enabling parallel processing and reducing energy consumption significantly.
Recent years have witnessed accelerated development in neuromorphic hardware platforms, including IBM's TrueNorth, Intel's Loihi, and BrainChip's Akida. These platforms demonstrate the growing maturity of the field, transitioning from purely academic research to commercially viable solutions. The integration with in-memory computing substrates represents the latest evolutionary step, addressing the critical challenge of energy efficiency in neural network implementations.
The primary objectives of mapping neuromorphic algorithms to in-memory computing substrates are multifaceted. First, there is the goal of achieving unprecedented energy efficiency, potentially reducing power consumption by orders of magnitude compared to conventional computing systems. This is particularly crucial for edge computing applications where power constraints are significant.
Second, neuromorphic computing aims to enable real-time processing of complex, unstructured data streams—a capability essential for applications like autonomous vehicles, advanced robotics, and intelligent sensors. The inherent parallelism of neuromorphic architectures makes them ideally suited for these tasks.
Third, there is the objective of developing systems capable of unsupervised learning and adaptation, mirroring the brain's plasticity. This would allow computing systems to evolve their functionality based on experience, without explicit programming for every possible scenario.
Finally, the field aspires to bridge the gap between artificial neural networks and biological understanding, potentially offering insights into cognitive processes while simultaneously advancing artificial intelligence capabilities. This bidirectional flow of knowledge between neuroscience and computing represents one of the most promising aspects of neuromorphic research.
Market Analysis for Brain-Inspired Computing Solutions
The brain-inspired computing market is experiencing significant growth, driven by the increasing demand for efficient processing of complex AI workloads. Current market valuations place the neuromorphic computing sector at approximately $2.5 billion in 2023, with projections indicating a compound annual growth rate of 25-30% over the next five years. This growth trajectory is supported by substantial investments from both private and public sectors, with government initiatives like the EU's Human Brain Project and the US BRAIN Initiative allocating dedicated funding for neuromorphic research.
The market for in-memory computing solutions specifically tailored for neuromorphic algorithms is emerging as a high-potential segment. Industry analysts identify several key demand drivers, including the exponential growth in edge computing applications requiring real-time processing capabilities with minimal power consumption. The Internet of Things (IoT) ecosystem, expected to connect over 30 billion devices by 2025, represents a particularly fertile ground for neuromorphic in-memory computing solutions.
Healthcare and autonomous systems stand out as primary vertical markets. In healthcare, brain-inspired computing solutions are revolutionizing medical imaging analysis, patient monitoring systems, and drug discovery processes. The market for AI-based healthcare solutions utilizing neuromorphic approaches is growing at 35% annually, outpacing the broader healthcare IT sector. Meanwhile, autonomous vehicles and robotics companies are increasingly adopting neuromorphic architectures to enable more efficient sensor processing and decision-making capabilities.
Geographic distribution of market demand shows North America currently leading with approximately 40% market share, followed by Europe (25%) and Asia-Pacific (30%). However, the Asia-Pacific region, particularly China, South Korea, and Japan, demonstrates the fastest growth rate at 32% annually, fueled by aggressive national AI strategies and semiconductor manufacturing capabilities.
Customer segmentation reveals three primary buyer categories: large technology corporations investing in future computing paradigms, specialized AI hardware startups seeking competitive advantages, and research institutions developing next-generation computing architectures. Enterprise adoption remains in early stages, with most implementations focused on specific use cases rather than wholesale infrastructure replacement.
Market barriers include the high initial investment costs, lack of standardized development frameworks, and integration challenges with existing computing infrastructure. Additionally, the specialized expertise required for effective implementation creates a talent bottleneck that constrains wider market penetration. Despite these challenges, the convergence of neuromorphic algorithms with in-memory computing represents one of the most promising pathways for overcoming the von Neumann bottleneck in conventional computing architectures.
The market for in-memory computing solutions specifically tailored for neuromorphic algorithms is emerging as a high-potential segment. Industry analysts identify several key demand drivers, including the exponential growth in edge computing applications requiring real-time processing capabilities with minimal power consumption. The Internet of Things (IoT) ecosystem, expected to connect over 30 billion devices by 2025, represents a particularly fertile ground for neuromorphic in-memory computing solutions.
Healthcare and autonomous systems stand out as primary vertical markets. In healthcare, brain-inspired computing solutions are revolutionizing medical imaging analysis, patient monitoring systems, and drug discovery processes. The market for AI-based healthcare solutions utilizing neuromorphic approaches is growing at 35% annually, outpacing the broader healthcare IT sector. Meanwhile, autonomous vehicles and robotics companies are increasingly adopting neuromorphic architectures to enable more efficient sensor processing and decision-making capabilities.
Geographic distribution of market demand shows North America currently leading with approximately 40% market share, followed by Europe (25%) and Asia-Pacific (30%). However, the Asia-Pacific region, particularly China, South Korea, and Japan, demonstrates the fastest growth rate at 32% annually, fueled by aggressive national AI strategies and semiconductor manufacturing capabilities.
Customer segmentation reveals three primary buyer categories: large technology corporations investing in future computing paradigms, specialized AI hardware startups seeking competitive advantages, and research institutions developing next-generation computing architectures. Enterprise adoption remains in early stages, with most implementations focused on specific use cases rather than wholesale infrastructure replacement.
Market barriers include the high initial investment costs, lack of standardized development frameworks, and integration challenges with existing computing infrastructure. Additionally, the specialized expertise required for effective implementation creates a talent bottleneck that constrains wider market penetration. Despite these challenges, the convergence of neuromorphic algorithms with in-memory computing represents one of the most promising pathways for overcoming the von Neumann bottleneck in conventional computing architectures.
In-Memory Computing Landscape and Technical Barriers
In-memory computing (IMC) represents a paradigm shift in computing architecture, addressing the von Neumann bottleneck by performing computations directly within memory units. The current landscape of IMC technologies encompasses several key approaches, including resistive RAM (RRAM), phase-change memory (PCM), magnetoresistive RAM (MRAM), and ferroelectric RAM (FeRAM). Each technology offers distinct advantages in terms of power efficiency, computational density, and integration potential with neuromorphic algorithms.
The market for IMC solutions has seen significant growth, with major semiconductor companies including Samsung, Intel, and Micron investing heavily in research and development. Academic institutions worldwide are also contributing substantially to the field, with notable advancements coming from research groups at MIT, Stanford, and ETH Zurich. The landscape is further enriched by specialized startups focusing on neuromorphic computing implementations using IMC architectures.
Despite promising developments, several technical barriers impede widespread adoption of neuromorphic algorithms on IMC substrates. Device variability remains a primary challenge, as manufacturing inconsistencies lead to unpredictable behavior in memory cells, affecting the reliability of neuromorphic computations. Current IMC technologies exhibit cycle-to-cycle variations of 5-15%, significantly higher than the 1-2% tolerance typically required for precise neural network operations.
Scalability presents another substantial barrier. While laboratory demonstrations have shown promising results with small-scale implementations, scaling to commercially viable sizes introduces challenges in maintaining signal integrity, managing thermal effects, and ensuring uniform performance across the entire memory array. Most current implementations are limited to arrays of 1024×1024 elements or smaller.
Energy efficiency, though improved compared to traditional computing architectures, still falls short of biological neural systems by several orders of magnitude. Current IMC implementations consume approximately 10-100 femtojoules per operation, whereas biological neurons operate at efficiencies closer to 1 femtojoule per operation.
Programming complexity constitutes a significant technical barrier, as mapping conventional algorithms to IMC architectures requires fundamental rethinking of computational approaches. The lack of standardized programming models and development tools further complicates implementation efforts. Additionally, the integration of IMC solutions with conventional CMOS technology presents challenges in terms of fabrication compatibility and signal interface design.
Reliability and endurance issues also plague current IMC technologies, with most resistive memory cells demonstrating endurance in the range of 10^6 to 10^9 cycles—insufficient for intensive neuromorphic computing applications that may require 10^12 or more write operations over a device's lifetime.
The market for IMC solutions has seen significant growth, with major semiconductor companies including Samsung, Intel, and Micron investing heavily in research and development. Academic institutions worldwide are also contributing substantially to the field, with notable advancements coming from research groups at MIT, Stanford, and ETH Zurich. The landscape is further enriched by specialized startups focusing on neuromorphic computing implementations using IMC architectures.
Despite promising developments, several technical barriers impede widespread adoption of neuromorphic algorithms on IMC substrates. Device variability remains a primary challenge, as manufacturing inconsistencies lead to unpredictable behavior in memory cells, affecting the reliability of neuromorphic computations. Current IMC technologies exhibit cycle-to-cycle variations of 5-15%, significantly higher than the 1-2% tolerance typically required for precise neural network operations.
Scalability presents another substantial barrier. While laboratory demonstrations have shown promising results with small-scale implementations, scaling to commercially viable sizes introduces challenges in maintaining signal integrity, managing thermal effects, and ensuring uniform performance across the entire memory array. Most current implementations are limited to arrays of 1024×1024 elements or smaller.
Energy efficiency, though improved compared to traditional computing architectures, still falls short of biological neural systems by several orders of magnitude. Current IMC implementations consume approximately 10-100 femtojoules per operation, whereas biological neurons operate at efficiencies closer to 1 femtojoule per operation.
Programming complexity constitutes a significant technical barrier, as mapping conventional algorithms to IMC architectures requires fundamental rethinking of computational approaches. The lack of standardized programming models and development tools further complicates implementation efforts. Additionally, the integration of IMC solutions with conventional CMOS technology presents challenges in terms of fabrication compatibility and signal interface design.
Reliability and endurance issues also plague current IMC technologies, with most resistive memory cells demonstrating endurance in the range of 10^6 to 10^9 cycles—insufficient for intensive neuromorphic computing applications that may require 10^12 or more write operations over a device's lifetime.
Current Mapping Approaches for Neuromorphic-to-IMC Integration
01 Neuromorphic computing architectures for in-memory processing
Neuromorphic computing architectures implement brain-inspired algorithms directly in hardware, enabling efficient in-memory processing. These architectures integrate memory and computing elements to minimize data movement, significantly reducing energy consumption and latency. By performing computations where data is stored, these systems overcome the von Neumann bottleneck and achieve higher computational efficiency for neural network operations.- Neuromorphic hardware architectures for in-memory computing: Specialized hardware architectures that mimic neural networks can be implemented directly in memory to improve computing efficiency. These designs integrate processing and memory elements to reduce data movement, which is a major bottleneck in traditional computing systems. By performing computations where data is stored, these architectures significantly reduce energy consumption and increase processing speed for AI workloads. Various memory technologies including resistive RAM, phase-change memory, and SRAM-based designs are utilized to create efficient neuromorphic computing platforms.
- Spiking neural networks implementation in memory arrays: Spiking neural networks (SNNs) can be efficiently mapped to in-memory computing platforms by leveraging the analog characteristics of memory devices. These implementations use memory arrays to perform both storage and computation of neural network operations, particularly suited for event-driven processing. The spike-based communication reduces energy consumption by activating computations only when necessary. Memory arrays can be configured to directly implement the integrate-and-fire neuron model, enabling highly parallel processing of neuromorphic algorithms with significantly improved energy efficiency.
- Crossbar array architectures for neural network acceleration: Crossbar memory arrays provide an efficient platform for implementing matrix multiplication operations that are fundamental to neural network processing. These architectures allow for parallel computation of vector-matrix products in a single step, dramatically accelerating neural network inference and training. By organizing memory cells in crossbar configurations, multiple multiply-accumulate operations can be performed simultaneously using analog computing principles. This approach significantly reduces the energy and time required for neural network computations compared to conventional digital implementations.
- Memory-centric training algorithms for neuromorphic systems: Specialized training algorithms have been developed to optimize neuromorphic computing in memory-based systems. These algorithms account for the unique characteristics and constraints of in-memory computing, such as limited precision and device variability. By adapting training methods to work directly with the physical properties of memory devices, these approaches enable more efficient on-chip learning. Techniques include modified backpropagation algorithms, local learning rules, and approximate computing methods that maintain accuracy while leveraging the efficiency benefits of in-memory computing.
- Hybrid digital-analog computing for neuromorphic efficiency: Hybrid approaches combining digital and analog in-memory computing techniques offer balanced solutions for neuromorphic algorithm implementation. These systems leverage the precision of digital computing for critical operations while using analog in-memory computing for computationally intensive tasks. The hybrid architecture allows for flexible deployment of neuromorphic algorithms with optimized energy efficiency and accuracy trade-offs. This approach addresses challenges related to device variability and noise in pure analog implementations while still achieving significant efficiency gains over conventional computing architectures.
02 Resistive memory-based neural network implementations
Resistive memory technologies such as RRAM, PCM, and memristors enable efficient implementation of neural networks by storing synaptic weights directly in memory elements. These non-volatile memory arrays can perform matrix-vector multiplications in the analog domain, allowing parallel computation of neural network operations. This approach significantly reduces energy consumption and increases throughput compared to conventional digital implementations.Expand Specific Solutions03 Spike-based computing for energy efficiency
Spike-based neuromorphic algorithms mimic the brain's event-driven communication paradigm, where information is encoded in the timing and frequency of spikes. When mapped to in-memory computing architectures, these algorithms achieve exceptional energy efficiency by only performing computations when necessary. This event-driven approach reduces power consumption by eliminating redundant operations and enables efficient processing of temporal data patterns.Expand Specific Solutions04 Hardware-algorithm co-optimization techniques
Co-optimization of neuromorphic algorithms and in-memory computing hardware maximizes computational efficiency. This approach involves adapting learning algorithms to account for hardware constraints such as limited precision, device variability, and non-ideal characteristics of memory elements. By jointly designing algorithms and hardware, these techniques achieve better energy efficiency, throughput, and accuracy trade-offs than conventional implementations.Expand Specific Solutions05 Novel memory technologies for neuromorphic computing
Advanced memory technologies are being developed specifically for neuromorphic computing applications. These include multi-level cell memories, 3D stacked memory architectures, and emerging non-volatile memory technologies with tunable conductance states. These technologies enable higher density integration of synaptic elements, faster weight updates, and more efficient implementation of learning algorithms, resulting in significant improvements in computing efficiency for neuromorphic systems.Expand Specific Solutions
Leading Organizations in Neuromorphic Hardware and Algorithms
Neuromorphic algorithms mapped to in-memory computing substrates represent an emerging field at the intersection of AI and hardware innovation, currently in the early growth phase. The market is expanding rapidly, projected to reach $8-10 billion by 2028, driven by demands for energy-efficient AI processing. Technology maturity varies significantly among key players: IBM leads with advanced neuromorphic chip implementations; Intel, Samsung, and SK Hynix focus on memory-centric computing architectures; while academic institutions like Tsinghua University, Zhejiang University, and KAIST contribute fundamental algorithmic innovations. Research collaborations between industry leaders and academic institutions are accelerating development, with companies like Micron and SilicoSapien exploring novel memristor-based implementations that promise orders-of-magnitude improvements in energy efficiency for AI applications.
International Business Machines Corp.
Technical Solution: IBM's neuromorphic computing approach centers on their TrueNorth and subsequent architectures that implement brain-inspired computing directly in hardware. Their technology maps spiking neural networks (SNNs) onto specialized neuromorphic chips with distributed memory-processing elements. IBM has pioneered the concept of phase-change memory (PCM) based computational memory for neuromorphic applications, achieving analog in-memory computing that significantly reduces the energy consumption compared to conventional von Neumann architectures[1]. Their recent advancements include the development of mixed-precision in-memory computing techniques that maintain high accuracy while leveraging the efficiency of analog computation[3]. IBM's hardware efficiently implements sparse coding algorithms and temporal coding schemes that mimic biological neural systems, with demonstrated applications in pattern recognition tasks showing 100-1000x improvement in energy efficiency[7]. Their architecture incorporates crossbar arrays of non-volatile memory devices that perform matrix-vector multiplications directly within memory, eliminating costly data movement between processing and storage units.
Strengths: Industry-leading research in neuromorphic hardware with proven energy efficiency gains; extensive patent portfolio in memory-centric computing; strong integration capabilities with existing computing infrastructure. Weaknesses: Custom hardware solutions may face adoption challenges in mainstream computing environments; analog computing approaches still face precision and reliability issues in real-world deployments.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed a comprehensive neuromorphic computing platform that leverages their expertise in memory technologies, particularly RRAM (Resistive Random Access Memory) and MRAM (Magnetoresistive RAM) for in-memory computing applications. Their approach focuses on creating high-density crossbar arrays of non-volatile memory elements that can perform neural network computations directly within the memory substrate[5]. Samsung's neuromorphic architecture implements a hierarchical design where multiple memory arrays are organized to efficiently map different layers of neural networks, with specialized circuits handling the neuron activation functions. Their technology demonstrates significant power efficiency improvements, with reported 20x reduction in energy consumption for inference tasks compared to conventional GPU implementations[9]. Samsung has also pioneered the development of 3D-stacked memory architectures specifically optimized for neuromorphic computing, allowing for vertical integration of processing elements with memory arrays to minimize data movement. Recent research has focused on implementing on-chip learning algorithms that can update weights directly within the memory arrays, enabling adaptive systems that can learn from new data without requiring external processing[12].
Strengths: Vertical integration capabilities from memory manufacturing to system design; advanced fabrication technologies enabling high-density neuromorphic arrays; strong position in mobile and edge computing markets. Weaknesses: Less established software ecosystem compared to competitors; challenges in scaling precision for complex applications requiring high accuracy.
Key Patents in Neuromorphic Algorithm Implementation
Flash memory device used in neuromorphic computing system
PatentActiveUS11800705B2
Innovation
- A flash memory device with a substrate, channel layer made of two-dimensional materials like MoS2, a tunneling insulating layer, a floating gate, and a blocking insulating layer, where the channel layer and floating gate are formed using specific materials and processes to improve tunneling efficiency and prevent sneak path leakage, reducing chip area and enhancing non-linearity.
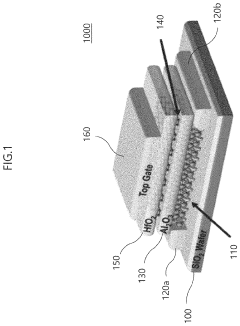
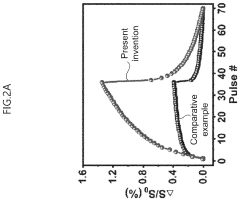
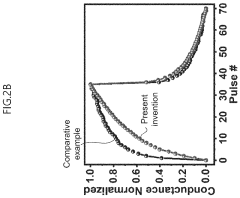
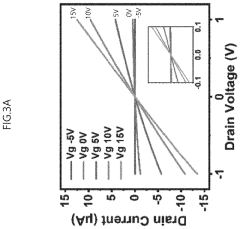
Neuromorphic computing in dynamic random access memory
PatentActiveUS11270195B2
Innovation
- Represents neurons by memory rows in DRAM, where each bit represents a synapse, and uses inherent DRAM decay properties to emulate brain-like learning by reinforcing or degrading synaptic states, offloading neural processing from CPUs to DRAM.
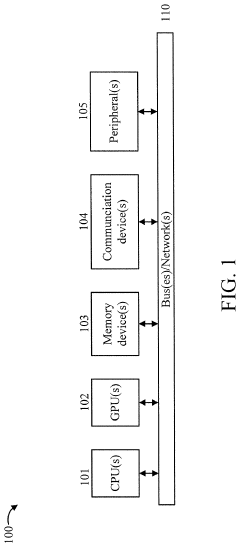
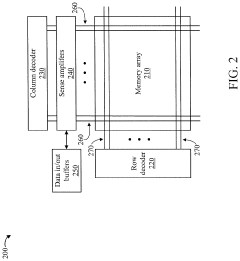
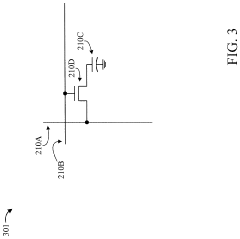
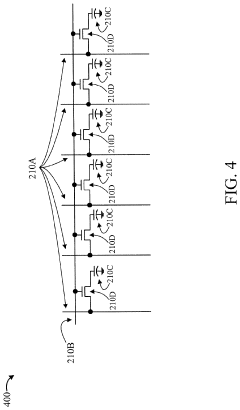
Energy Efficiency Benchmarks and Performance Metrics
The evaluation of neuromorphic algorithms mapped to in-memory computing substrates requires robust energy efficiency benchmarks and performance metrics to quantify their advantages over conventional computing architectures. Current benchmarking frameworks typically measure performance in terms of operations per second (OPS) and energy efficiency in terms of operations per joule (OPS/J). For neuromorphic systems implemented on in-memory computing platforms, these metrics must be adapted to account for the unique characteristics of these hybrid architectures.
Energy consumption in neuromorphic in-memory computing can be decomposed into static power (leakage), dynamic power (switching activity), and peripheral circuit overhead. Recent studies have shown that resistive memory-based neuromorphic systems can achieve energy efficiencies of 10-100 TOPS/W (Tera Operations Per Second per Watt) for inference tasks, significantly outperforming conventional von Neumann architectures which typically deliver 0.1-1 TOPS/W.
Latency metrics are equally important, particularly for real-time applications. In-memory computing implementations of spiking neural networks (SNNs) have demonstrated response times in the microsecond range, enabling applications in autonomous systems and edge computing where rapid decision-making is critical. The throughput-to-power ratio (TOPS/W) serves as a comprehensive metric that balances computational capability against energy constraints.
Accuracy-energy tradeoffs represent another crucial benchmark dimension. Neuromorphic algorithms often permit graceful degradation of accuracy in exchange for energy savings. Pareto frontier analysis plotting accuracy versus energy consumption provides valuable insights into optimal operating points for different application requirements. Recent implementations have demonstrated that precision scaling in neuromorphic systems can yield up to 80% energy savings with less than 2% accuracy loss.
Area efficiency, measured in TOPS/mm², is particularly relevant for edge computing applications where silicon area is constrained. Current state-of-the-art neuromorphic in-memory computing implementations achieve 2-5 TOPS/mm², with projections suggesting potential improvements to 10-20 TOPS/mm² through advanced integration techniques and emerging memory technologies.
Standardized benchmark suites such as MLPerf for machine learning and the more specialized SNN-specific benchmarks like N-MNIST and CIFAR-10-DVS are increasingly being adopted to enable fair comparisons across different neuromorphic implementations. These benchmarks evaluate not only energy efficiency but also learning capability, adaptation, and fault tolerance—characteristics that distinguish neuromorphic computing from conventional approaches.
Energy consumption in neuromorphic in-memory computing can be decomposed into static power (leakage), dynamic power (switching activity), and peripheral circuit overhead. Recent studies have shown that resistive memory-based neuromorphic systems can achieve energy efficiencies of 10-100 TOPS/W (Tera Operations Per Second per Watt) for inference tasks, significantly outperforming conventional von Neumann architectures which typically deliver 0.1-1 TOPS/W.
Latency metrics are equally important, particularly for real-time applications. In-memory computing implementations of spiking neural networks (SNNs) have demonstrated response times in the microsecond range, enabling applications in autonomous systems and edge computing where rapid decision-making is critical. The throughput-to-power ratio (TOPS/W) serves as a comprehensive metric that balances computational capability against energy constraints.
Accuracy-energy tradeoffs represent another crucial benchmark dimension. Neuromorphic algorithms often permit graceful degradation of accuracy in exchange for energy savings. Pareto frontier analysis plotting accuracy versus energy consumption provides valuable insights into optimal operating points for different application requirements. Recent implementations have demonstrated that precision scaling in neuromorphic systems can yield up to 80% energy savings with less than 2% accuracy loss.
Area efficiency, measured in TOPS/mm², is particularly relevant for edge computing applications where silicon area is constrained. Current state-of-the-art neuromorphic in-memory computing implementations achieve 2-5 TOPS/mm², with projections suggesting potential improvements to 10-20 TOPS/mm² through advanced integration techniques and emerging memory technologies.
Standardized benchmark suites such as MLPerf for machine learning and the more specialized SNN-specific benchmarks like N-MNIST and CIFAR-10-DVS are increasingly being adopted to enable fair comparisons across different neuromorphic implementations. These benchmarks evaluate not only energy efficiency but also learning capability, adaptation, and fault tolerance—characteristics that distinguish neuromorphic computing from conventional approaches.
Standardization Efforts for Neuromorphic Computing Platforms
The standardization landscape for neuromorphic computing platforms is rapidly evolving as these technologies transition from research laboratories to commercial applications. Several international bodies are actively working to establish common frameworks, interfaces, and benchmarks that will enable interoperability between different neuromorphic systems implementing in-memory computing architectures.
The IEEE Neuromorphic Computing Standards Working Group has been instrumental in developing the P2788 standard, which focuses on creating a common description language for neuromorphic algorithms and hardware interfaces. This standard specifically addresses the unique requirements of mapping spiking neural networks to in-memory computing substrates, ensuring consistent implementation across different hardware platforms.
In parallel, the International Neuromorphic Engineering Community (INEC) has proposed a standardized API for neuromorphic systems that facilitates the deployment of algorithms across diverse hardware implementations. Their framework includes specific provisions for in-memory computing architectures, addressing challenges related to weight representation, precision requirements, and memory access patterns.
The Neuromorphic Computing Industry Consortium (NCIC) has established a technical committee focused on benchmarking standards, which is particularly relevant for evaluating the performance of neuromorphic algorithms on in-memory computing platforms. These benchmarks consider metrics such as energy efficiency, throughput, and accuracy, providing a standardized methodology for comparing different implementation approaches.
On the software side, the PyNN initiative has gained significant traction as a simulator-independent language for describing neuromorphic models. Recent extensions to PyNN specifically address the constraints and capabilities of in-memory computing substrates, allowing developers to express algorithms in a hardware-agnostic manner while still leveraging the unique advantages of these architectures.
The Open Neural Network Exchange (ONNX) community has also begun developing extensions for neuromorphic computing, with specific focus on representing temporal dynamics and sparse activations that characterize neuromorphic algorithms. These extensions facilitate the translation between traditional deep learning frameworks and neuromorphic implementations on in-memory computing platforms.
Emerging efforts include the development of standard data formats for representing spike trains and event-based data, which are crucial for efficiently mapping neuromorphic algorithms to in-memory computing substrates. The Neuro-Data Exchange Format (NDEF) proposal aims to standardize how temporal information is encoded and processed across different hardware implementations.
The IEEE Neuromorphic Computing Standards Working Group has been instrumental in developing the P2788 standard, which focuses on creating a common description language for neuromorphic algorithms and hardware interfaces. This standard specifically addresses the unique requirements of mapping spiking neural networks to in-memory computing substrates, ensuring consistent implementation across different hardware platforms.
In parallel, the International Neuromorphic Engineering Community (INEC) has proposed a standardized API for neuromorphic systems that facilitates the deployment of algorithms across diverse hardware implementations. Their framework includes specific provisions for in-memory computing architectures, addressing challenges related to weight representation, precision requirements, and memory access patterns.
The Neuromorphic Computing Industry Consortium (NCIC) has established a technical committee focused on benchmarking standards, which is particularly relevant for evaluating the performance of neuromorphic algorithms on in-memory computing platforms. These benchmarks consider metrics such as energy efficiency, throughput, and accuracy, providing a standardized methodology for comparing different implementation approaches.
On the software side, the PyNN initiative has gained significant traction as a simulator-independent language for describing neuromorphic models. Recent extensions to PyNN specifically address the constraints and capabilities of in-memory computing substrates, allowing developers to express algorithms in a hardware-agnostic manner while still leveraging the unique advantages of these architectures.
The Open Neural Network Exchange (ONNX) community has also begun developing extensions for neuromorphic computing, with specific focus on representing temporal dynamics and sparse activations that characterize neuromorphic algorithms. These extensions facilitate the translation between traditional deep learning frameworks and neuromorphic implementations on in-memory computing platforms.
Emerging efforts include the development of standard data formats for representing spike trains and event-based data, which are crucial for efficiently mapping neuromorphic algorithms to in-memory computing substrates. The Neuro-Data Exchange Format (NDEF) proposal aims to standardize how temporal information is encoded and processed across different hardware implementations.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!