

Method for automatically building classification tree from semi-structured data of Wikipedia
A semi-structured data and Wikipedia technology, applied in the field of knowledge acquisition, can solve problems such as unrecognizable relationships
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0062] The present invention will be further described below in conjunction with accompanying drawings and examples.
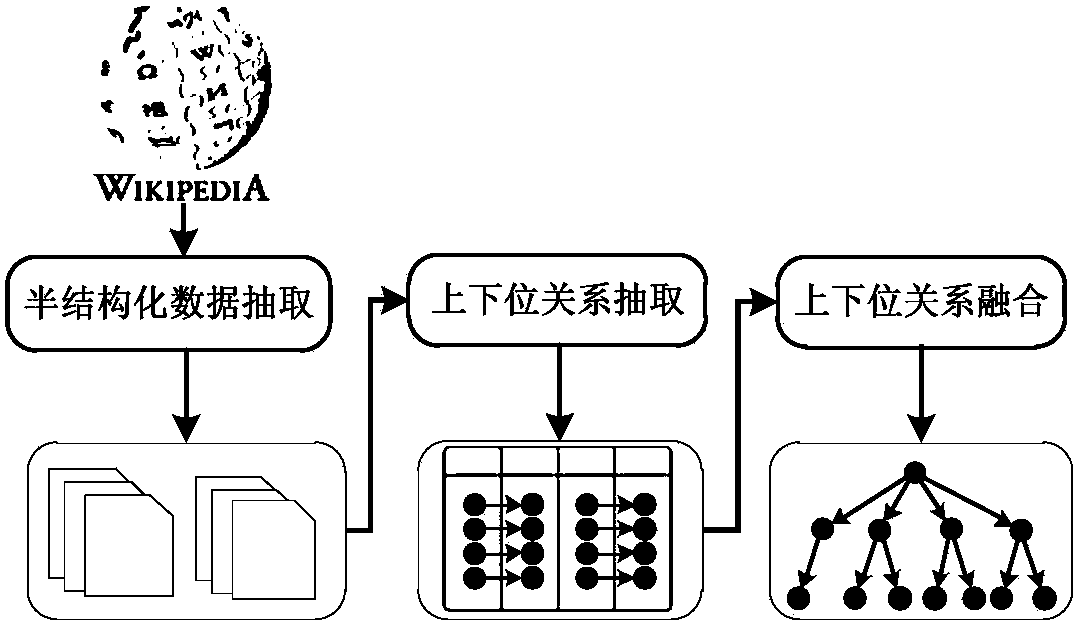
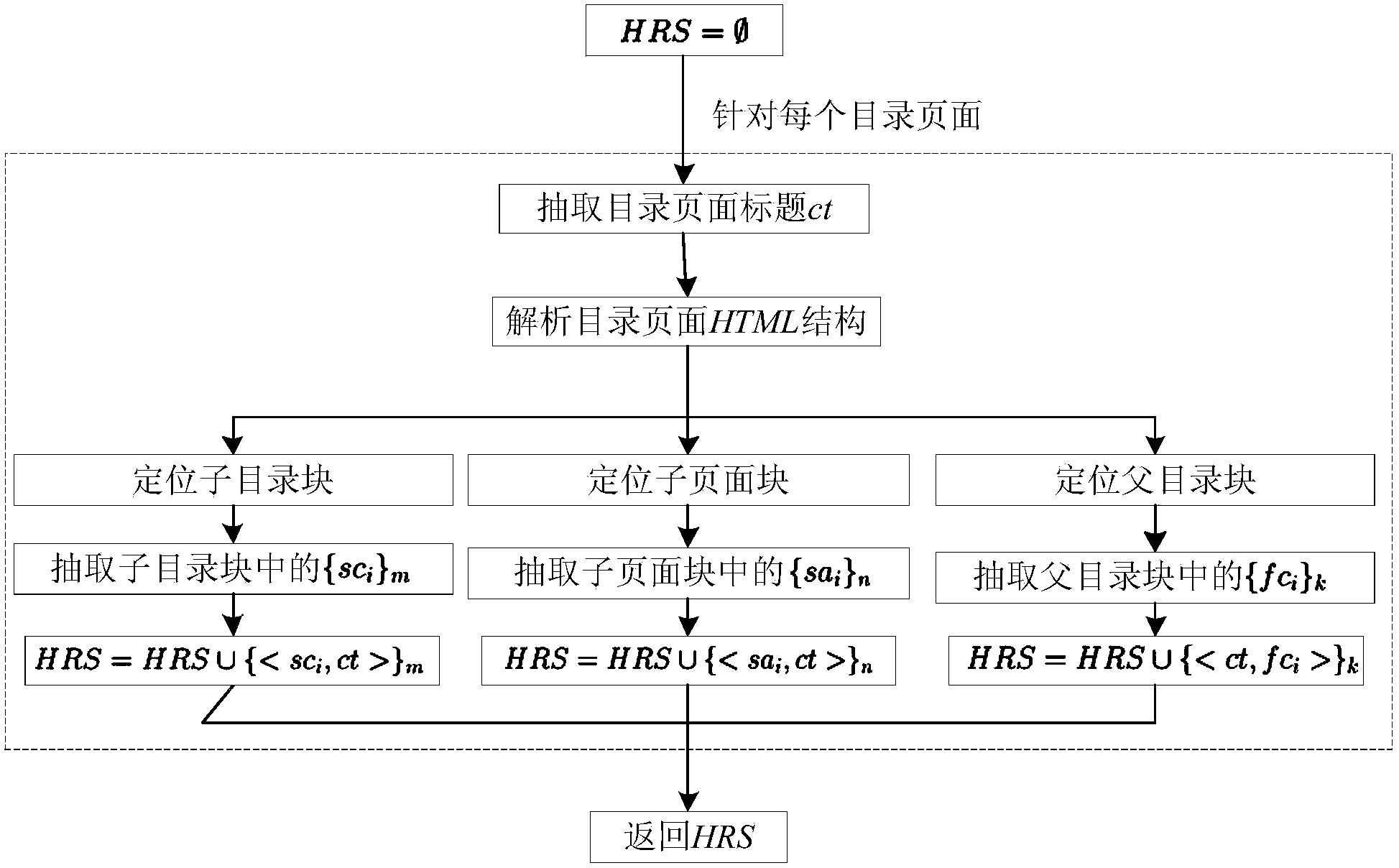
[0063] see figure 1 Shown, a kind of method of the present invention automatically constructs classification tree from Wikipedia semi-structured data, is divided into following 3 processes:
[0064] Step 1: Semi-structured data extraction, including 2 steps.
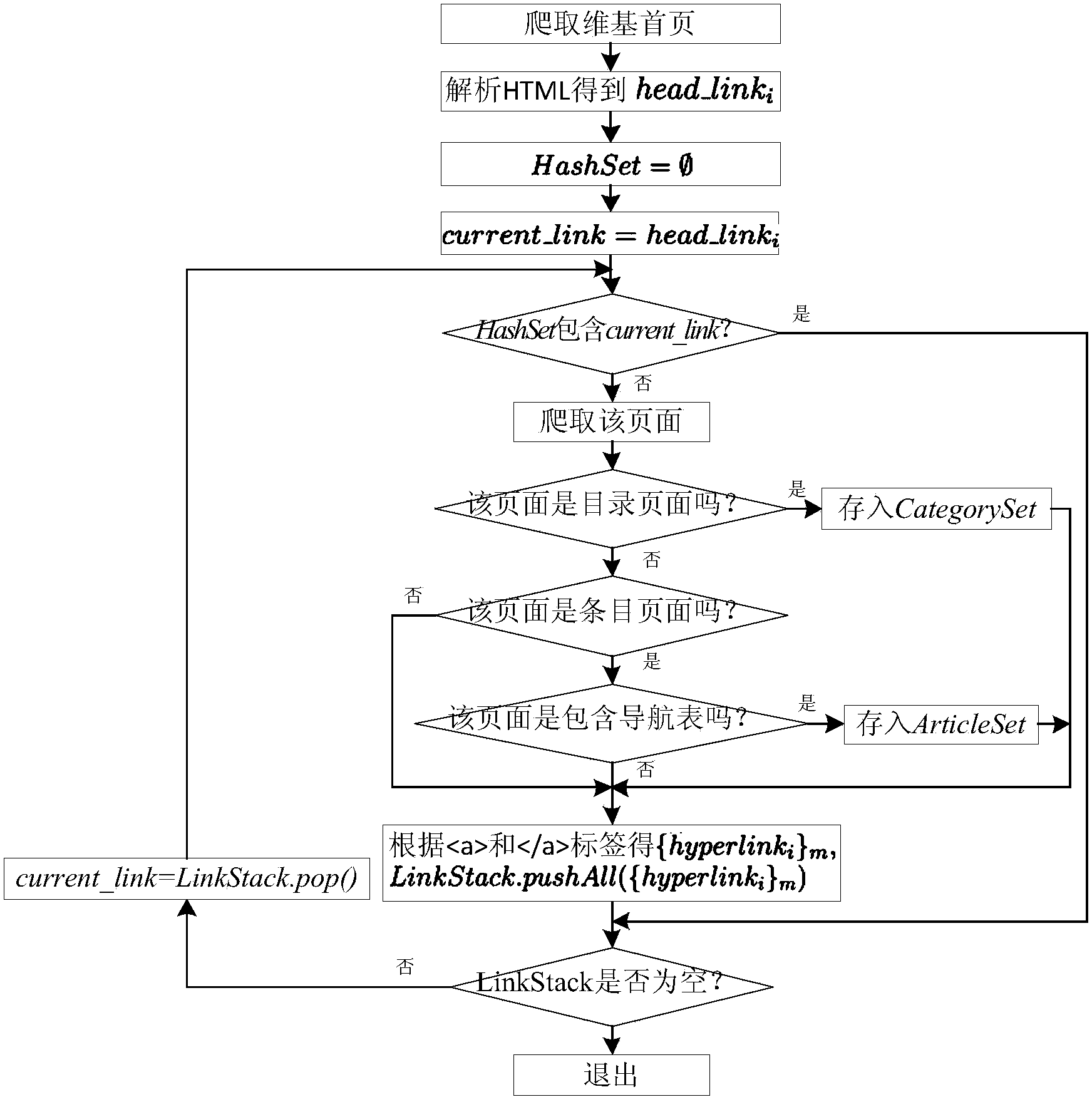
[0065] Step 1.1: Starting from the homepage of the Wikipedia website www.wikipedia.org, crawl all pages layer by layer by analyzing the hyperlinks of the page, and obtain the entry page according to the page URL prefix "http: / / en.wikipedia.org / wiki / " , get the catalog page according to the URL prefix "http: / / en.wikipedia.org / wiki / Category:", each page corresponds to an entity, and the page title is the name of the entity;
[0066] Step 1.2: According to whether the entry page contains the HTML tag , filter out the entry pages containing the navigation table.
[0067] The flow of these steps is as fol...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More