

Training method for multiple personalized acoustic models, and voice synthesis method and voice synthesis device
An acoustic model and speech synthesis technology, applied in the field of speech, can solve problems such as low accuracy of the acoustic model, unstable timbre, and unnatural speech, so as to meet the needs of personalized speech and improve user experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0039] Embodiments of the present invention are described in detail below, examples of which are shown in the drawings, wherein the same or similar reference numerals designate the same or similar elements or elements having the same or similar functions throughout. The embodiments described below by referring to the figures are exemplary and are intended to explain the present invention and should not be construed as limiting the present invention.
[0040] The following describes the personalized multi-acoustic model training method for speech synthesis, speech synthesis method and device according to the embodiments of the present invention with reference to the accompanying drawings.
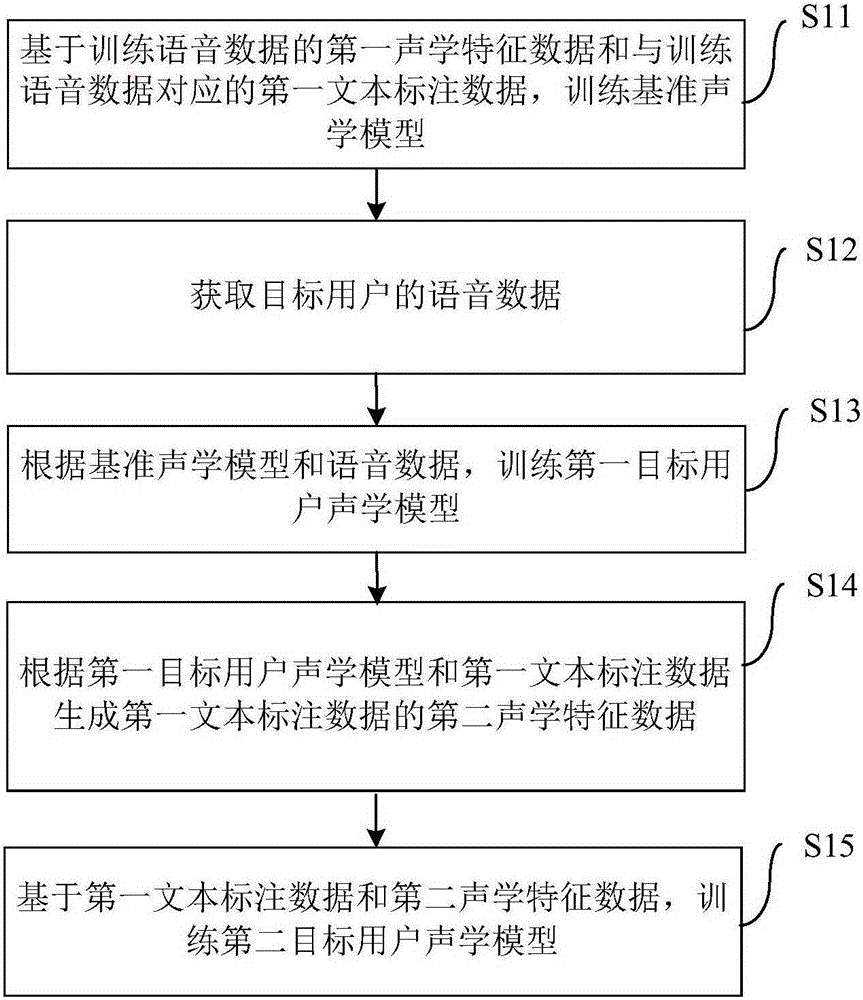
[0041] figure 1 It is a flowchart of a training method for a personalized multi-acoustic model for speech synthesis according to an embodiment of the present invention.
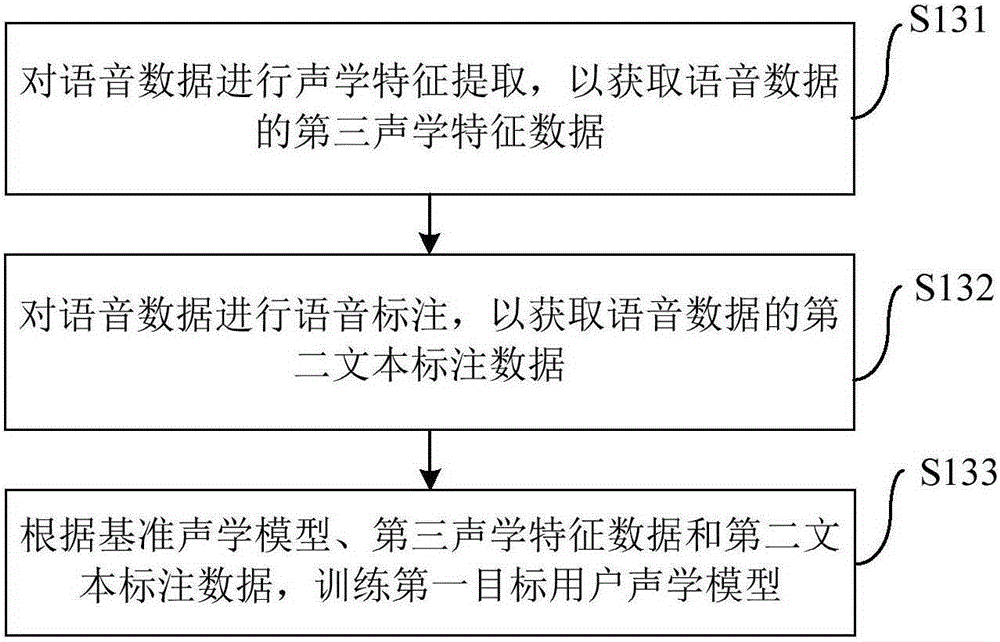
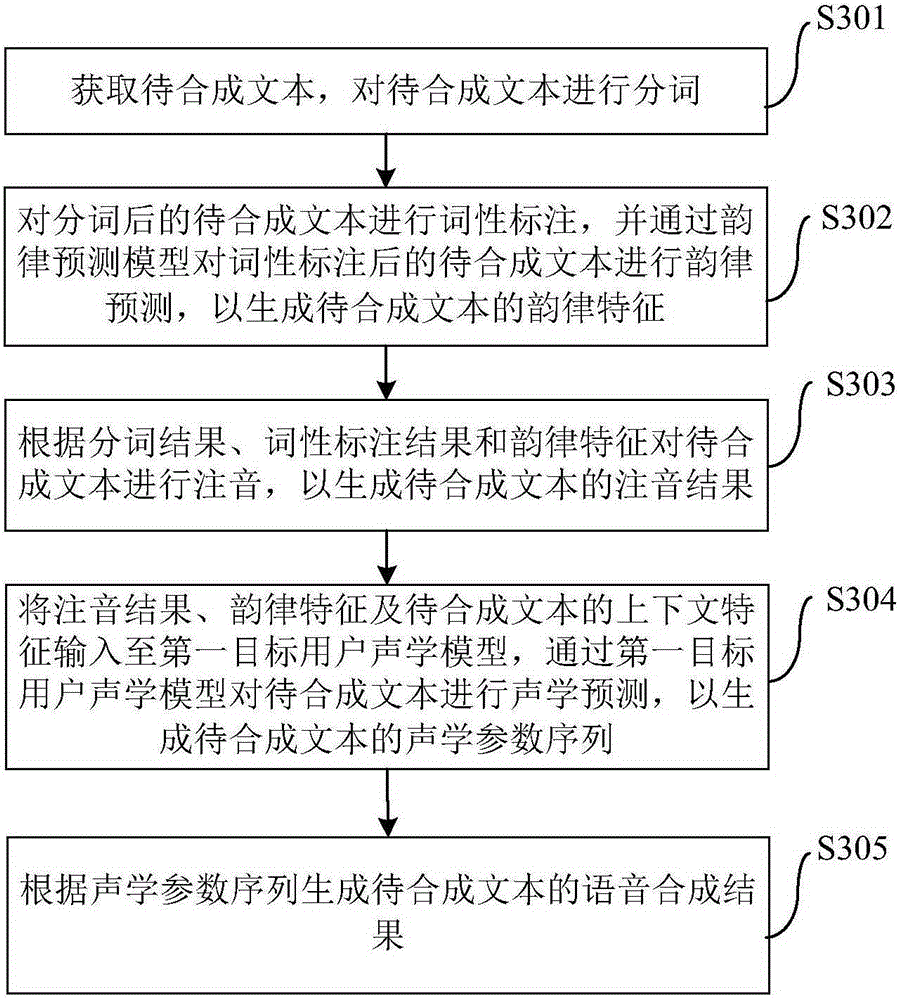
[0042] Such as figure 1 As shown, the training method of the personalized multi-acoustic model for speech synthesis inc...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More