

A distributed data anonymous processing method based on mapreduce
A technology of distributed data and processing methods, which is applied in the field of data processing to achieve efficient processing, improve efficiency, and solve the lack of server storage and computing power.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
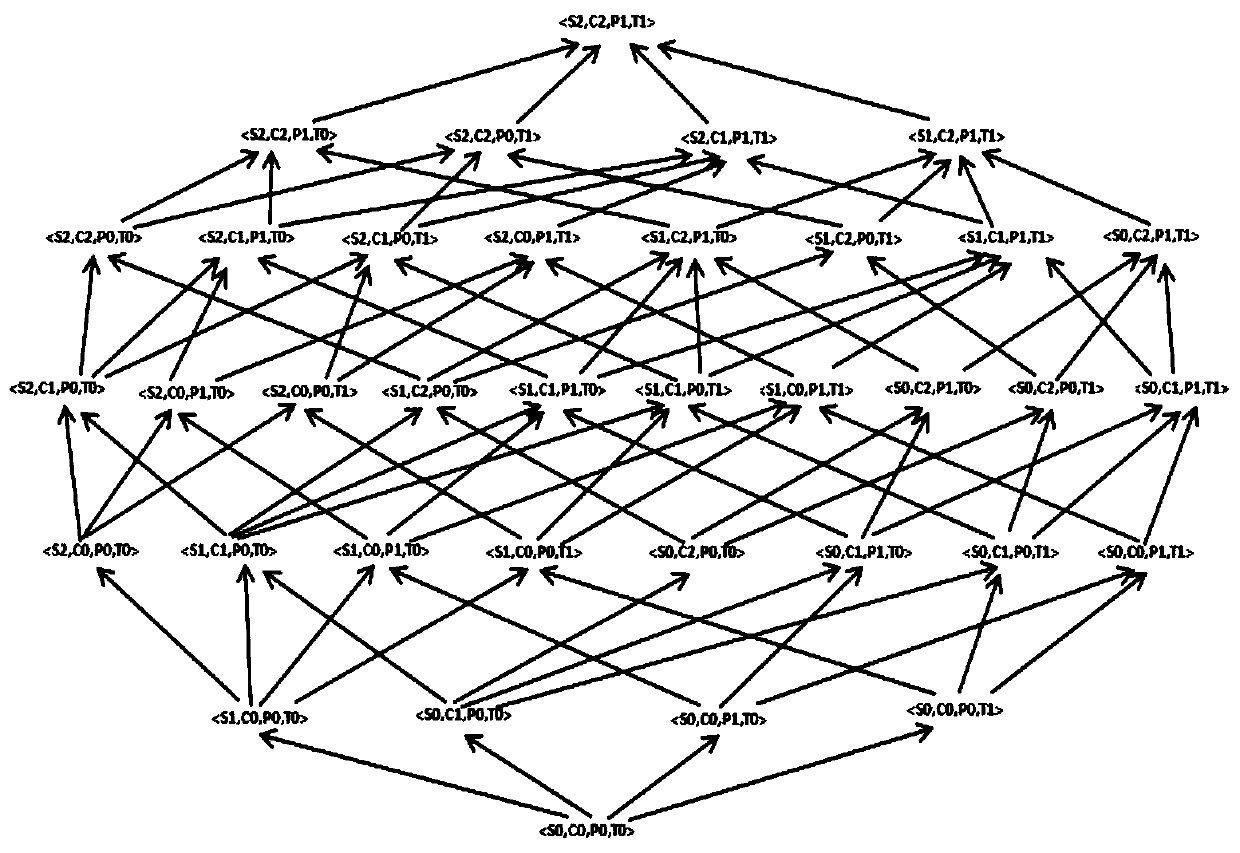
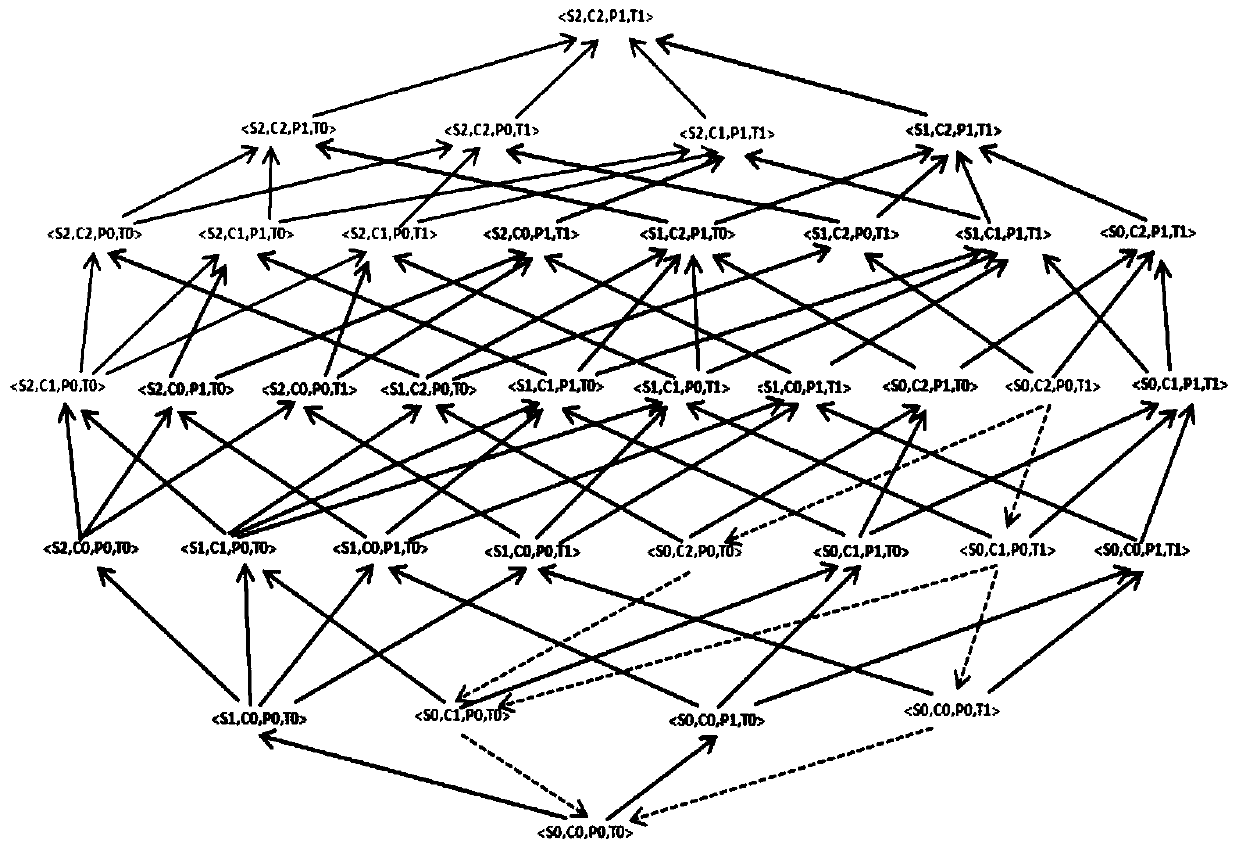
[0041] Taking a data table with four quasi-identifiers as an example, the specific implementation process is as follows:
[0042] Step 1, first choice, determine the quasi-identifier of the data table, take a data table with four quasi-identifiers (Supplier, Code, Price, Time) as an example for data processing, the generalization rules are as follows: S0 (supplier) , C0 (material code), P0 (material price), T0 (process time) are quasi-identifiers, which are used for generalized attributes. According to prior knowledge, formulate corresponding generalization rules for alignment identifiers:
[0043] For example, generalize {a certain limited company in Xuzhou City, a certain limited company in Beijing, a certain limited company in Hefei, a certain limited company in Suzhou,...} attribute from h=0 to h=1 layer and become gender {Jiangsu Province, Beijing, Anhui Province,...}, generalize from h=1 to h=2 to {China}; generalize the specific time (T) of the process to {≤30min, >30m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More