

Text conversion method and system for assisting blind in reading
A conversion method and a conversion system technology, which are applied in the field of text conversion methods and systems for assisting blind people to read, can solve problems such as low efficiency, large text size restrictions, logical errors, etc., and achieve the effects of high precision and fast detection and recognition speed.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
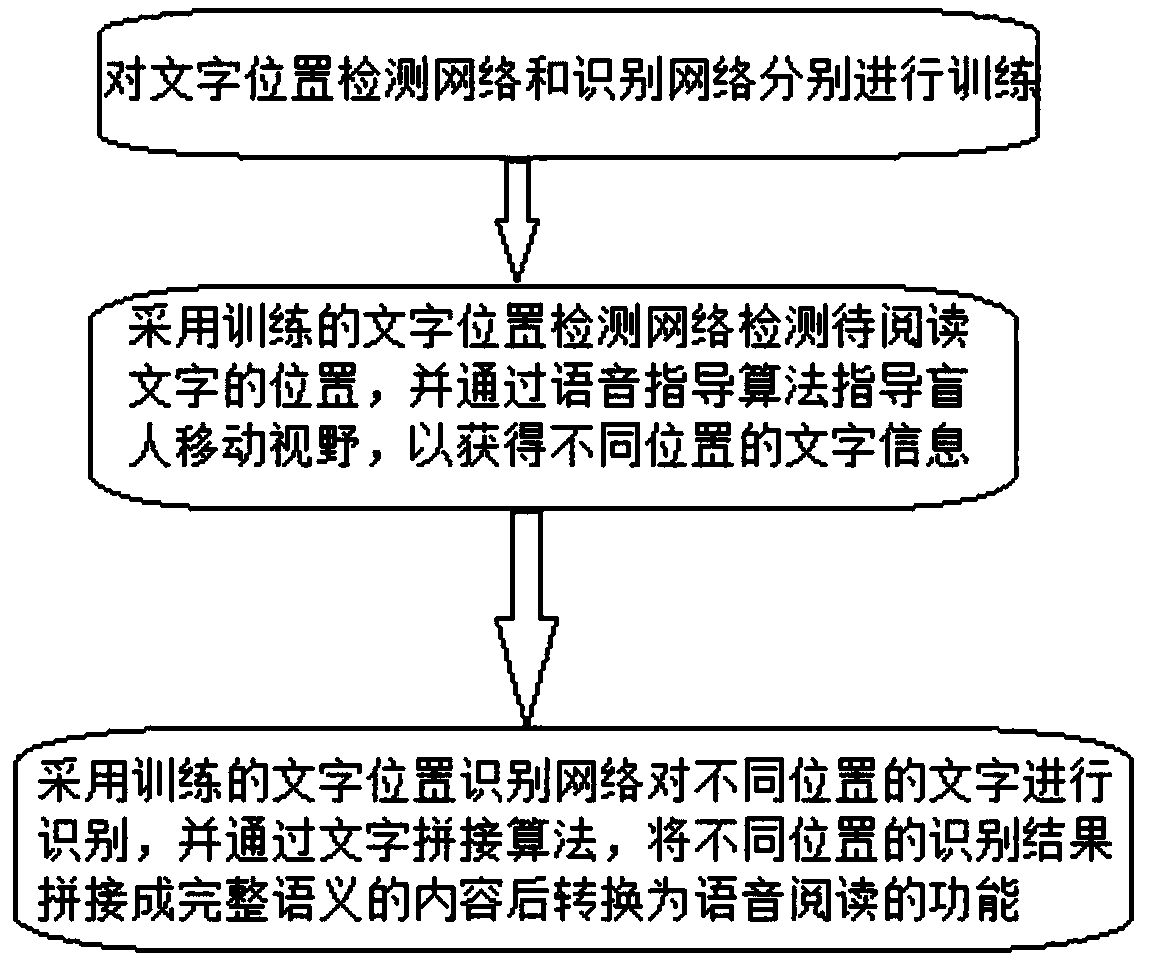
[0047] Such as figure 1 As shown, a text conversion method for assisting blind people to read, including the following process:
[0048] Step 1, train the text position detection network and the recognition network respectively;
[0049] Step 2, use the trained text position detection network to detect the position of the text to be read, and guide the blind person to move the field of vision through the voice guidance algorithm to obtain text information at different positions;
[0050] Step 3: Use the trained text position recognition network to recognize the text in different positions, and use the text splicing algorithm to splice the recognition results in different positions into complete semantic content and then convert it into voice reading.
[0051] The text conversion method for assisting the blind to read in Example 1 guides the blind to move their field of vision to obtain text information at different positions through voice interaction on the basis of detecting...
Embodiment 2
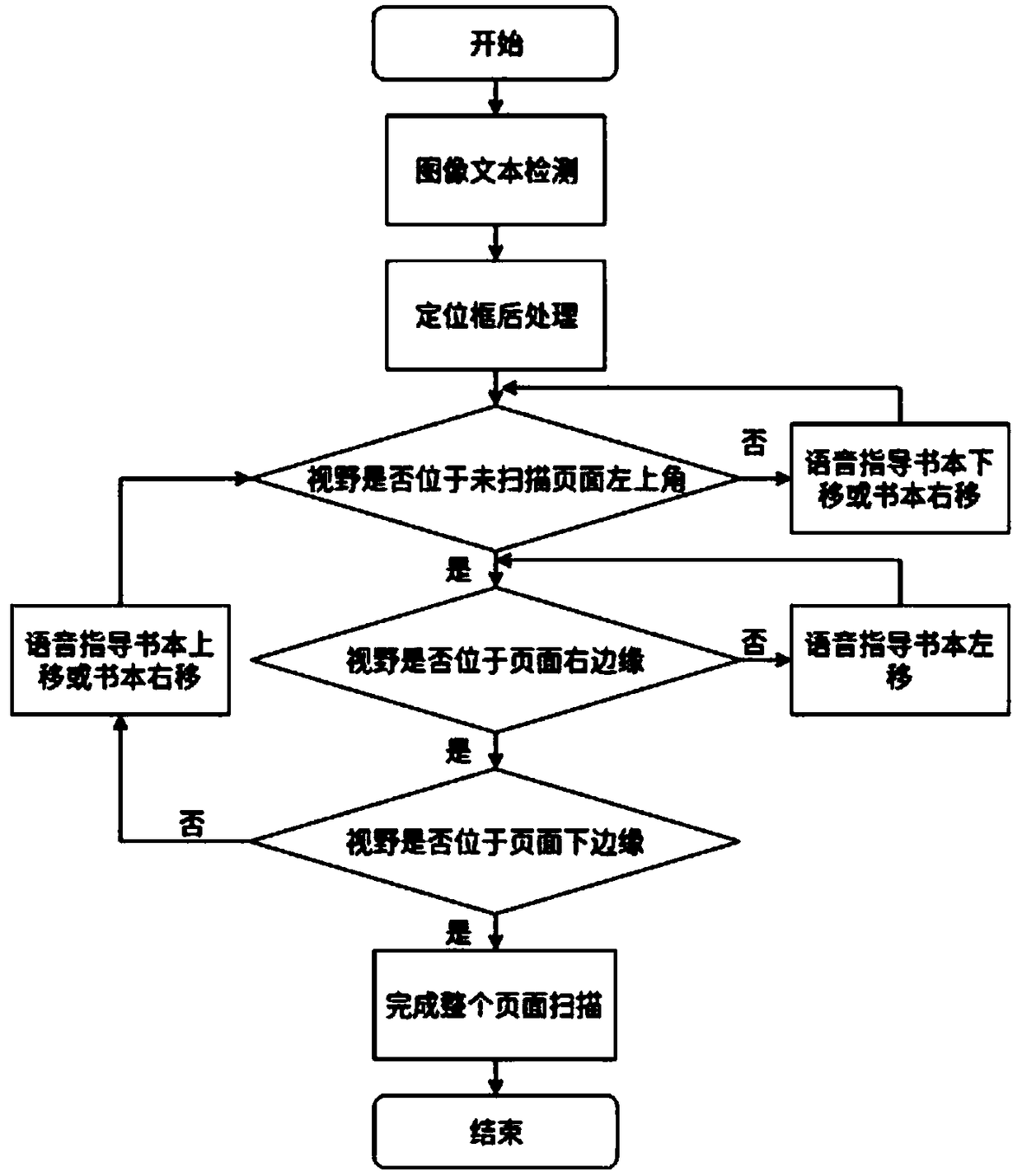
[0053] Preferably, on the basis of Example 1, such as figure 2 As shown, the specific process of the voice guidance algorithm is:
[0054] A. Use the camera image acquisition module to acquire video frames with a size of 640 pixels*480 pixels in real time, and output a stable frame frequency; perform text position detection on video frames with a size of 640 pixels*480 pixels, calculate text features and get Positioning boxes of all text line regions within the video frame, each positioning box contains the coordinates of its 4 vertices.
[0055]B. Perform post-processing on the positioning frame of the detection output. The post-processing includes removing text boxes whose short side length is smaller than a certain threshold. In this specific embodiment, 20 pixels are used. Post-processing also includes sequentially judging the 4 vertices of each positioning frame, and if there is a vertex that is less than 50 pixels away from the edge of the input image, the correspondin...
Embodiment 3
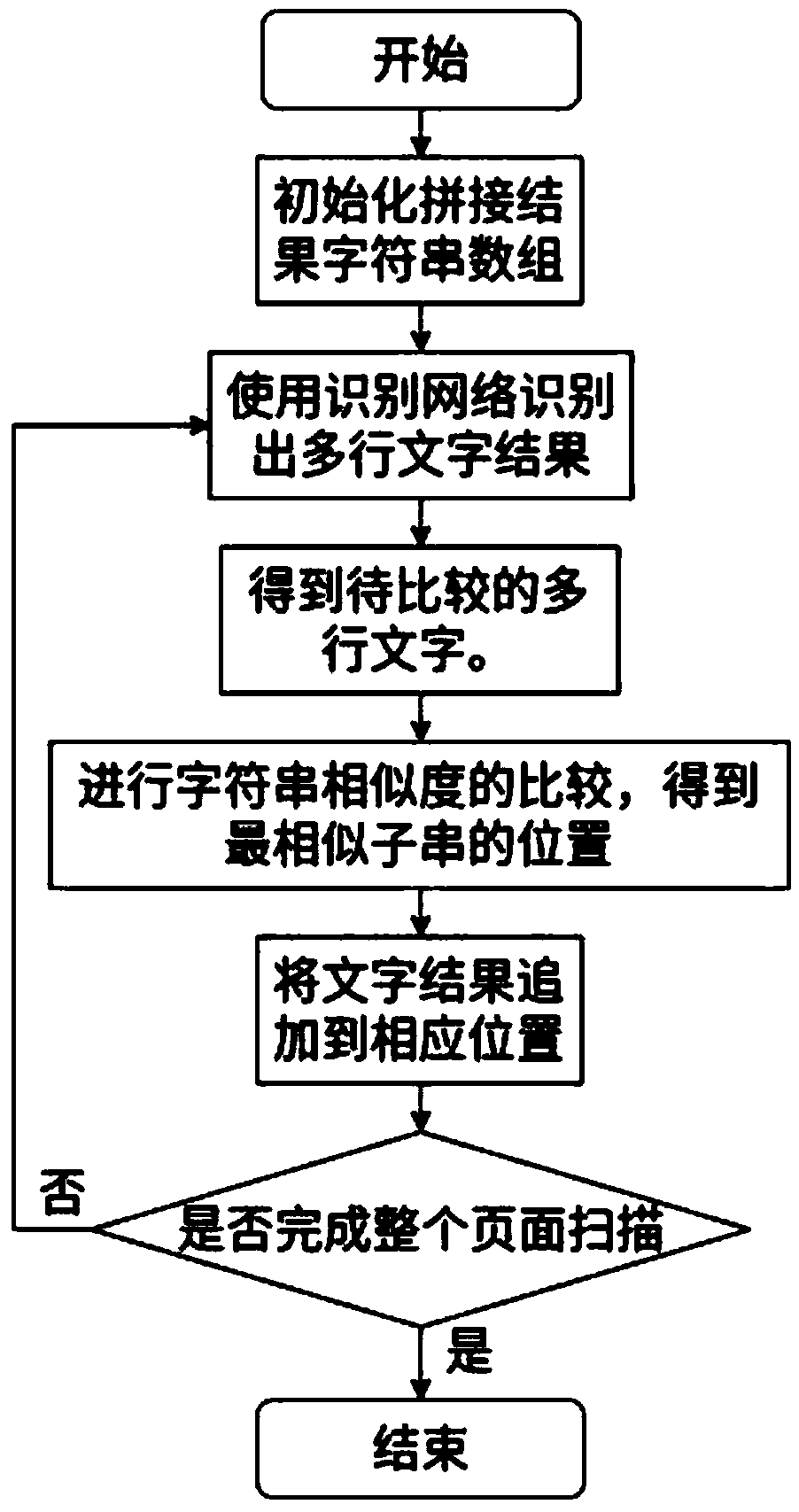
[0061] Preferably, on the basis of embodiment 1 and embodiment 2, the specific method steps of described text splicing algorithm are:
[0062] a. Initialize a string array all_text to store the splicing result, which is empty in the initial state;
[0063] b. Send the current video frame and the corresponding detection and positioning frame to the recognition network to obtain the recognized multi-line text result, and store the result in a string array text.
[0064] c. Extract the first 5 characters of each character string in the character string array text, and obtain the character string array compare_text to be compared.
[0065] d. Compare each string in the string array compare_text to be compared with the 5-character substring of each string in the result string array all_text one by one, if a certain string in compare_text If the similarity with a certain substring of a certain string in all_text is greater than 0.7, record the position information of the substring....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More