

All-end-to-end Chinese and English mixed air traffic control voice recognition method and device
A speech recognition and speech recognition model technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as scattered features, difficult pronunciation and scale of word meaning, poor speech signal quality, etc., to achieve pronunciation scale enhancement, enhanced learning, The effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
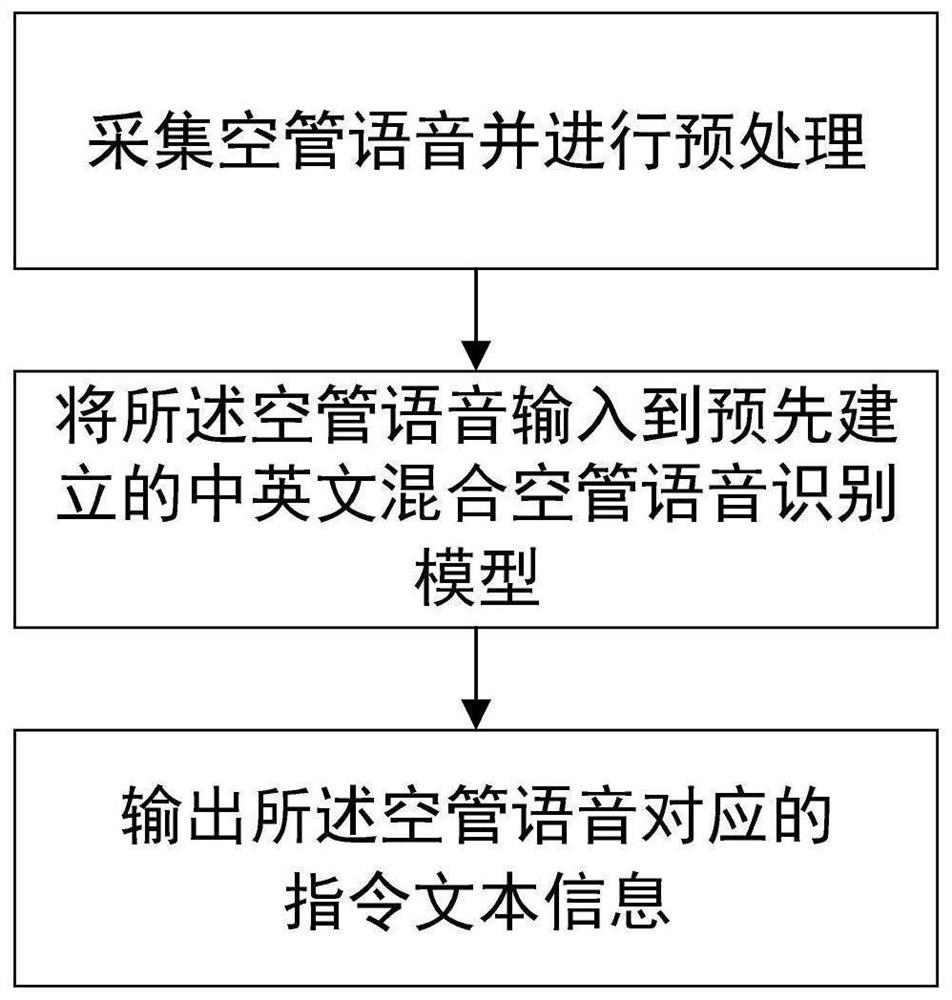
[0069] Such as figure 1 As shown, a full-end-to-end Chinese-English mixed air traffic control speech recognition method includes the following steps:
[0070] a: collecting air traffic control voice and preprocessing the air traffic control voice; wherein, the air traffic control voice is audio data mixed in Chinese and English;
[0071] b: input the air traffic control voice into the pre-established Chinese and English mixed air traffic control voice recognition model;
[0072] c: output the command information corresponding to the air traffic control voice;
[0073] The Chinese-English mixed air traffic control speech recognition model includes a feature learning module and a speech recognition module; the feature learning module is used to extract the speech features of the air traffic control speech, and the speech recognition module is used to optimize model parameters and output corresponding instruction information.
[0074] Wherein, the training of the Chinese-Englis...
Embodiment 2
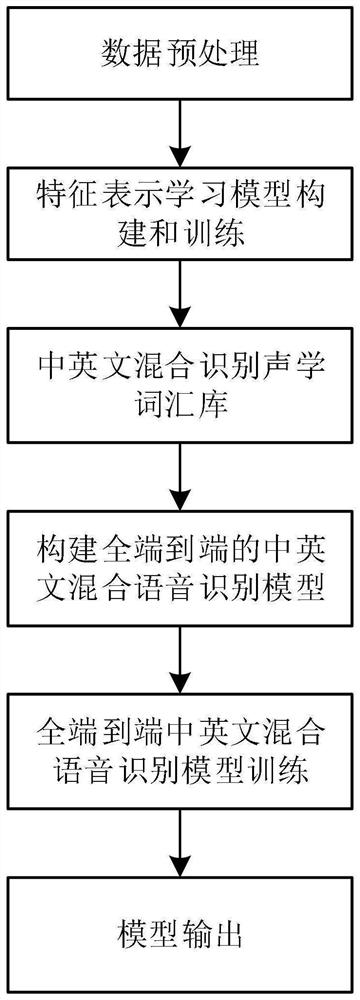
[0100] Such as figure 2 As shown, the present embodiment is the detailed training process of the Chinese-English mixed air traffic control speech recognition model described in Embodiment 1, and the specific steps are as follows:
[0101] Step 1: Preprocessing the speech recognition training samples, including the following process:
[0102] Step 1-1: First, use voice activity detection technology (voice activity detection, VAD) to divide the continuous original dialogue voice into individual audio files, each audio only contains the voice of a single speaker, that is, the content of a single control instruction, and removes the silence and noisy data.
[0103] Step 1-2: According to the air traffic control voice content involved in this scheme, use Chinese characters and English words to mark the readable instruction text corresponding to the audio, and output the unmarked original voice signal and the single voice signal after segmentation and marking.
[0104] Step 2: Bu...
Embodiment 3
[0138] The difference between this embodiment and Embodiment 1 and Embodiment 2 is that the Chinese-English mixed air traffic control speech recognition model also includes a Chinese-English instruction vocabulary.
[0139] From the perspective of pronunciation, Chinese characters use monosyllable pronunciation, while English words (partial letters) generally belong to polysyllable pronunciation. From a linguistic point of view, Chinese characters are the basic morphological units of Chinese, but Chinese phrases can express complete meanings; for English, letters are the basic morphological units, and English words are the smallest language units with complete meanings. Generally speaking, Chinese phrases generally contain 2-4 Chinese characters, while English words may contain as many as 10 letters. It can be seen that Chinese and English languages are not on the same scale in terms of pronunciation or language; therefore, a new method for training and building Chinese and ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More