

Topic web crawler method and system based on text classification
A web crawler and text classification technology, which is applied in the fields of artificial intelligence and deep learning, can solve problems such as high memory usage, less than 50% information coverage, and weak personalized needs, and achieve the effect of improving the degree of topic matching
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

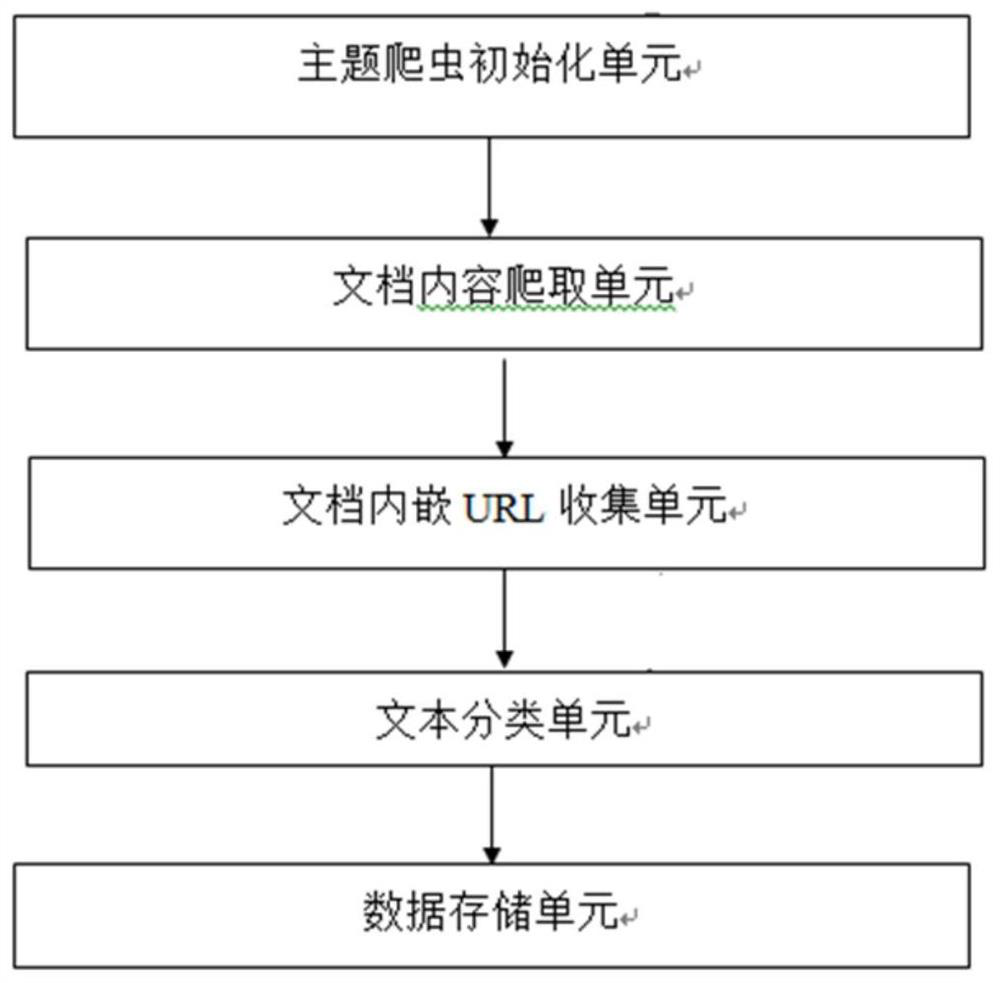
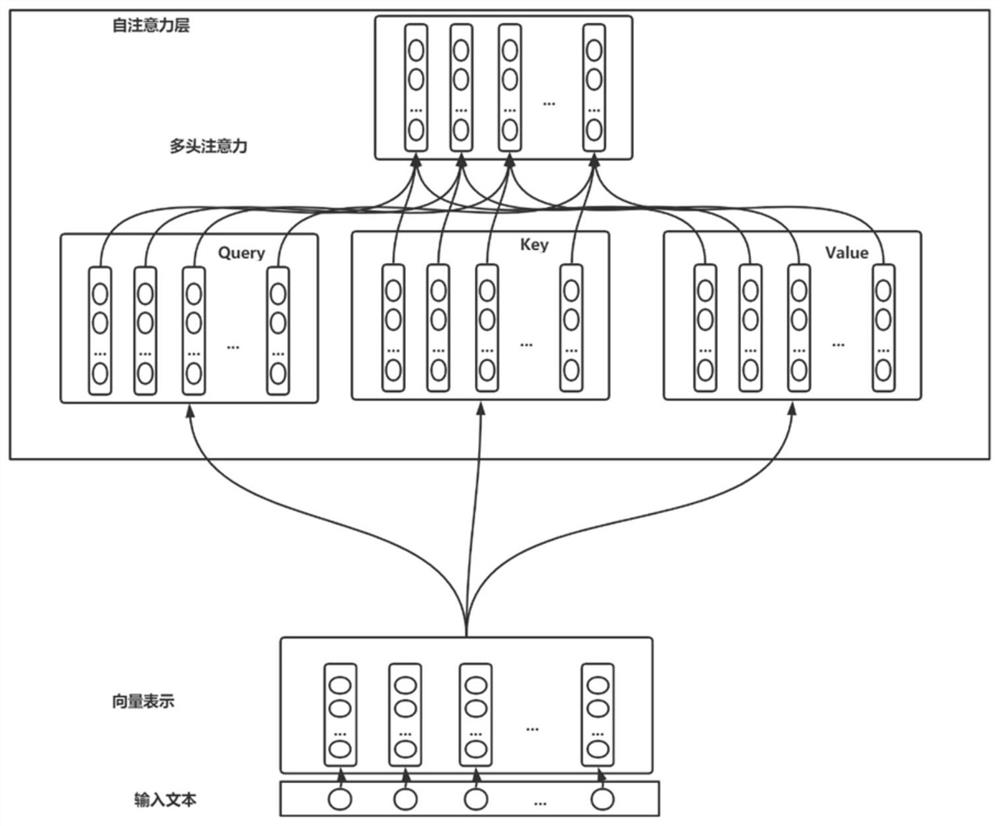
Examples
Embodiment Construction
[0038] In order to make the purpose, technical solutions and advantages of the embodiments of the present invention more clear, the technical solutions in the embodiments of the present invention will be checked and completely described below in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments It is a part of embodiments of the present invention, but not all embodiments. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
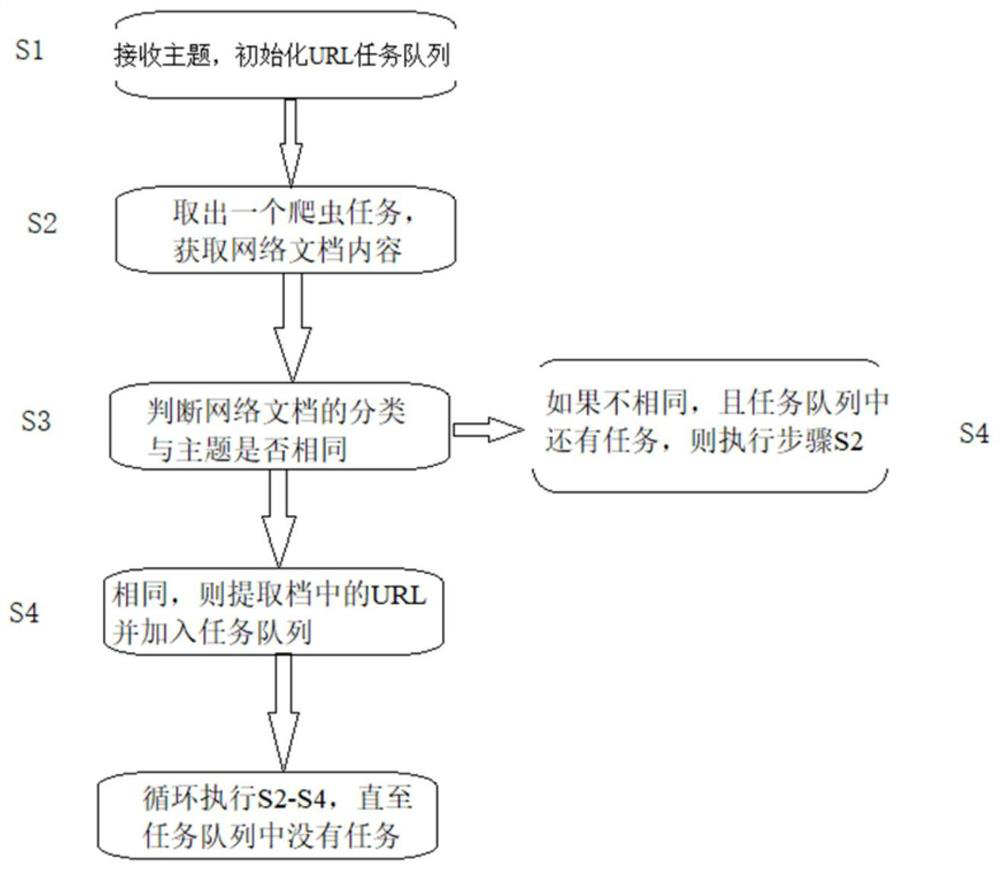
[0039] A kind of theme web crawler method based on text classification proposed by the present invention, such as figure 1 shown, including the following steps:
[0040] S1. Receive the theme and initialize the URL task queue;
[0041] S2. Take out a crawler task from the URL task queue to obtain the content of the network ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More