

Analog Training Workflows For PCM-Based Neural Accelerators
AUG 29, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
PCM Neural Accelerator Background and Objectives
Phase Change Memory (PCM) technology has emerged as a promising foundation for neural accelerators, representing a significant evolution in the field of neuromorphic computing. The development of PCM-based neural accelerators traces back to the early 2010s when researchers began exploring non-volatile memory technologies as alternatives to traditional CMOS-based implementations. This technological trajectory was driven by the increasing computational demands of neural networks and the physical limitations of conventional computing architectures.
PCM offers unique advantages for neural computation, including non-volatility, high density, and the ability to perform analog computations directly in memory. These properties align remarkably well with the computational patterns of neural networks, where massive parallelism and frequent weight updates are common requirements. The evolution of PCM technology has been characterized by progressive improvements in reliability, endurance, and precision, making it increasingly viable for neural network applications.
The current technological landscape shows a clear trend toward hardware-software co-design approaches that optimize neural network training specifically for PCM-based architectures. This represents a departure from traditional digital implementations and moves toward more efficient analog computing paradigms that can potentially offer orders of magnitude improvements in energy efficiency and computational density.
The primary objective of analog training workflows for PCM-based neural accelerators is to develop robust methodologies that can effectively harness the analog computational capabilities of PCM while mitigating its inherent limitations. These limitations include device-to-device variability, limited precision, and non-linear conductance response, which pose significant challenges for neural network training.
Another critical goal is to establish training algorithms that can adapt to the unique characteristics of PCM devices, including asymmetric weight updates, limited dynamic range, and drift in conductance values over time. These specialized training approaches must maintain or improve upon the accuracy achieved by conventional digital implementations while delivering substantial improvements in energy efficiency and computational throughput.
Looking forward, the field aims to develop end-to-end solutions that seamlessly integrate PCM-based hardware with popular deep learning frameworks, enabling widespread adoption across various application domains. This includes creating abstraction layers that shield AI developers from the complexities of the underlying hardware while still leveraging its unique capabilities.
The ultimate technological objective is to enable on-chip training capabilities that can support continuous learning and adaptation in edge devices, opening new possibilities for intelligent systems that can evolve and improve their performance in real-world environments without requiring constant communication with centralized servers.
PCM offers unique advantages for neural computation, including non-volatility, high density, and the ability to perform analog computations directly in memory. These properties align remarkably well with the computational patterns of neural networks, where massive parallelism and frequent weight updates are common requirements. The evolution of PCM technology has been characterized by progressive improvements in reliability, endurance, and precision, making it increasingly viable for neural network applications.
The current technological landscape shows a clear trend toward hardware-software co-design approaches that optimize neural network training specifically for PCM-based architectures. This represents a departure from traditional digital implementations and moves toward more efficient analog computing paradigms that can potentially offer orders of magnitude improvements in energy efficiency and computational density.
The primary objective of analog training workflows for PCM-based neural accelerators is to develop robust methodologies that can effectively harness the analog computational capabilities of PCM while mitigating its inherent limitations. These limitations include device-to-device variability, limited precision, and non-linear conductance response, which pose significant challenges for neural network training.
Another critical goal is to establish training algorithms that can adapt to the unique characteristics of PCM devices, including asymmetric weight updates, limited dynamic range, and drift in conductance values over time. These specialized training approaches must maintain or improve upon the accuracy achieved by conventional digital implementations while delivering substantial improvements in energy efficiency and computational throughput.
Looking forward, the field aims to develop end-to-end solutions that seamlessly integrate PCM-based hardware with popular deep learning frameworks, enabling widespread adoption across various application domains. This includes creating abstraction layers that shield AI developers from the complexities of the underlying hardware while still leveraging its unique capabilities.
The ultimate technological objective is to enable on-chip training capabilities that can support continuous learning and adaptation in edge devices, opening new possibilities for intelligent systems that can evolve and improve their performance in real-world environments without requiring constant communication with centralized servers.
Market Analysis for Analog AI Hardware
The analog AI hardware market is experiencing significant growth, driven by the increasing demand for energy-efficient computing solutions for artificial intelligence applications. Current market valuations indicate that the neuromorphic computing market, which includes analog AI hardware, is projected to reach $8.3 billion by 2026, growing at a compound annual growth rate of 20.7% from 2021. PCM-based neural accelerators represent a promising segment within this market due to their non-volatile memory characteristics and analog computation capabilities.
The demand for analog AI hardware is primarily fueled by applications requiring edge computing capabilities, where power efficiency is paramount. These include autonomous vehicles, IoT devices, smartphones, and other battery-powered systems that benefit from the reduced energy consumption offered by analog computing approaches. PCM-based solutions specifically address the growing need for on-device training capabilities, which is expected to be a key differentiator in next-generation AI systems.
Market segmentation reveals distinct categories within the analog AI hardware space. The largest segment currently consists of inference-only accelerators, which dominate approximately 65% of the market. However, the training-capable hardware segment, where PCM-based neural accelerators position themselves, is growing at a faster rate of approximately 27% annually, indicating shifting market priorities toward complete on-device AI solutions.
Regional analysis shows North America leading the market with approximately 42% share, followed by Asia-Pacific at 35%, which is growing most rapidly due to significant investments in semiconductor manufacturing and AI research in countries like China, South Korea, and Taiwan. Europe accounts for about 18% of the market, with particular strength in research-oriented applications.
Key customer segments include cloud service providers seeking energy-efficient data center solutions, automotive manufacturers developing advanced driver assistance systems, consumer electronics companies integrating AI capabilities into devices, and industrial automation firms. Each segment has distinct requirements regarding performance, power efficiency, and cost considerations that influence their adoption of PCM-based neural accelerators.
The economic factors driving market growth include the rising costs of traditional computing approaches for AI workloads, particularly in training large models, and the increasing emphasis on sustainable computing solutions. PCM-based neural accelerators offer potential cost advantages through reduced power consumption, which can translate to operational savings of 30-40% compared to digital alternatives in certain applications.
Market forecasts suggest that analog training workflows for PCM-based neural accelerators will see accelerated adoption between 2024-2027, coinciding with the maturation of programming frameworks and development tools that make these novel architectures more accessible to AI developers and researchers.
The demand for analog AI hardware is primarily fueled by applications requiring edge computing capabilities, where power efficiency is paramount. These include autonomous vehicles, IoT devices, smartphones, and other battery-powered systems that benefit from the reduced energy consumption offered by analog computing approaches. PCM-based solutions specifically address the growing need for on-device training capabilities, which is expected to be a key differentiator in next-generation AI systems.
Market segmentation reveals distinct categories within the analog AI hardware space. The largest segment currently consists of inference-only accelerators, which dominate approximately 65% of the market. However, the training-capable hardware segment, where PCM-based neural accelerators position themselves, is growing at a faster rate of approximately 27% annually, indicating shifting market priorities toward complete on-device AI solutions.
Regional analysis shows North America leading the market with approximately 42% share, followed by Asia-Pacific at 35%, which is growing most rapidly due to significant investments in semiconductor manufacturing and AI research in countries like China, South Korea, and Taiwan. Europe accounts for about 18% of the market, with particular strength in research-oriented applications.
Key customer segments include cloud service providers seeking energy-efficient data center solutions, automotive manufacturers developing advanced driver assistance systems, consumer electronics companies integrating AI capabilities into devices, and industrial automation firms. Each segment has distinct requirements regarding performance, power efficiency, and cost considerations that influence their adoption of PCM-based neural accelerators.
The economic factors driving market growth include the rising costs of traditional computing approaches for AI workloads, particularly in training large models, and the increasing emphasis on sustainable computing solutions. PCM-based neural accelerators offer potential cost advantages through reduced power consumption, which can translate to operational savings of 30-40% compared to digital alternatives in certain applications.
Market forecasts suggest that analog training workflows for PCM-based neural accelerators will see accelerated adoption between 2024-2027, coinciding with the maturation of programming frameworks and development tools that make these novel architectures more accessible to AI developers and researchers.
Technical Challenges in PCM-Based Neural Computing
Phase-change memory (PCM) technology presents significant challenges in the context of neural computing, particularly for analog training workflows. The non-linear resistance characteristics of PCM cells create inconsistent weight updates during neural network training, resulting in convergence difficulties and reduced accuracy compared to digital implementations. This non-linearity varies across different PCM devices and can change over time, making standardization problematic.
Resistance drift represents another major obstacle, as PCM cell resistance tends to increase logarithmically over time due to structural relaxation of the amorphous phase. For neural network applications requiring stable weights, this temporal instability introduces unpredictable behavior during both training and inference phases, necessitating complex compensation mechanisms.
The limited endurance of PCM cells poses a critical challenge for training workflows. With typical endurance of 10^6 to 10^8 write cycles, PCM cells may degrade during the extensive weight updates required for deep neural network training. This limitation becomes particularly problematic for continuous learning applications or networks requiring frequent retraining.
Device-to-device variability further complicates PCM-based neural accelerators. Manufacturing variations lead to inconsistent resistance levels across nominally identical PCM cells, resulting in weight precision issues. This variability necessitates sophisticated calibration techniques and error correction mechanisms, increasing system complexity and potentially offsetting energy efficiency advantages.
The asymmetric write operation in PCM cells presents additional challenges. The SET (crystallization) and RESET (amorphization) operations have different energy requirements and timing characteristics, creating an inherent asymmetry in weight updates. This asymmetry complicates the implementation of gradient-based learning algorithms that assume symmetric weight adjustments.
Power consumption during programming operations remains a significant concern. While PCM offers advantages in read energy efficiency, the programming current required for reliable state changes can be substantial. This creates thermal management challenges in densely packed neural accelerator architectures and may limit the parallelism achievable during training operations.
The limited precision of PCM cells restricts the representation of weight gradients during backpropagation. Most PCM implementations achieve only 4-6 bits of effective precision, whereas high-precision training typically requires 16-32 bit representations. This precision gap necessitates novel quantization techniques or hybrid architectures combining PCM with traditional CMOS memory for gradient storage.
Resistance drift represents another major obstacle, as PCM cell resistance tends to increase logarithmically over time due to structural relaxation of the amorphous phase. For neural network applications requiring stable weights, this temporal instability introduces unpredictable behavior during both training and inference phases, necessitating complex compensation mechanisms.
The limited endurance of PCM cells poses a critical challenge for training workflows. With typical endurance of 10^6 to 10^8 write cycles, PCM cells may degrade during the extensive weight updates required for deep neural network training. This limitation becomes particularly problematic for continuous learning applications or networks requiring frequent retraining.
Device-to-device variability further complicates PCM-based neural accelerators. Manufacturing variations lead to inconsistent resistance levels across nominally identical PCM cells, resulting in weight precision issues. This variability necessitates sophisticated calibration techniques and error correction mechanisms, increasing system complexity and potentially offsetting energy efficiency advantages.
The asymmetric write operation in PCM cells presents additional challenges. The SET (crystallization) and RESET (amorphization) operations have different energy requirements and timing characteristics, creating an inherent asymmetry in weight updates. This asymmetry complicates the implementation of gradient-based learning algorithms that assume symmetric weight adjustments.
Power consumption during programming operations remains a significant concern. While PCM offers advantages in read energy efficiency, the programming current required for reliable state changes can be substantial. This creates thermal management challenges in densely packed neural accelerator architectures and may limit the parallelism achievable during training operations.
The limited precision of PCM cells restricts the representation of weight gradients during backpropagation. Most PCM implementations achieve only 4-6 bits of effective precision, whereas high-precision training typically requires 16-32 bit representations. This precision gap necessitates novel quantization techniques or hybrid architectures combining PCM with traditional CMOS memory for gradient storage.
Current Analog Training Workflow Solutions
01 PCM-based neural network architecture design
Phase Change Memory (PCM) can be used to design neural network architectures that optimize training workflows. These architectures leverage the non-volatile properties of PCM to store synaptic weights efficiently, reducing power consumption during training. The designs include specialized memory arrays and circuit configurations that enable parallel processing of neural network operations, accelerating the training process while maintaining accuracy.- PCM-based neural network architecture design: Phase Change Memory (PCM) can be utilized in neural network architectures to improve computational efficiency. These designs leverage PCM's non-volatile characteristics and analog computation capabilities to implement neural network operations directly in memory, reducing the von Neumann bottleneck. The architecture typically includes PCM cells arranged in crossbar arrays that can perform matrix-vector multiplications for neural network inference and training, significantly accelerating these operations while reducing power consumption.
- Training optimization techniques for PCM-based neural accelerators: Various optimization techniques can enhance the training process for PCM-based neural accelerators. These include specialized gradient descent algorithms adapted for PCM characteristics, batch processing methods that maximize parallel operations, and techniques to handle the non-ideal properties of PCM cells such as drift and variability. Advanced training workflows incorporate iterative weight updates that account for PCM's unique write behavior and resistance states, enabling more efficient and accurate neural network training.
- In-memory computing for neural network training: In-memory computing paradigms using PCM technology enable neural network training directly within memory arrays. This approach eliminates the need to shuttle data between processing and memory units, significantly reducing energy consumption and latency. The training workflows involve specialized programming sequences that configure PCM cells to represent synaptic weights, with analog conductance states used to store and update these weights during backpropagation. This architecture supports both forward and backward passes of neural network training within the memory substrate.
- Hardware-software co-design for PCM neural accelerators: Effective PCM-based neural accelerators require tight integration between hardware architecture and software frameworks. This co-design approach includes developing specialized compilers that map neural network operations to PCM hardware, runtime systems that manage resource allocation and scheduling, and programming models that expose PCM capabilities to machine learning frameworks. The workflows incorporate hardware-aware training algorithms that account for PCM device characteristics while optimizing for accuracy and computational efficiency.
- Fault tolerance and reliability mechanisms: PCM-based neural accelerators incorporate fault tolerance mechanisms to address reliability challenges inherent in PCM technology. These include error correction techniques, redundancy schemes, and adaptive training methods that compensate for PCM cell failures and performance degradation over time. The training workflows implement periodic calibration procedures, wear-leveling algorithms to distribute write operations evenly across PCM cells, and resilient weight encoding schemes that maintain neural network accuracy despite device variability and aging effects.
02 Training optimization techniques for PCM-based accelerators
Various optimization techniques can enhance the training workflows on PCM-based neural accelerators. These include specialized algorithms that account for PCM's unique characteristics such as limited write endurance and asymmetric read/write operations. Techniques like gradient quantization, weight pruning, and adaptive learning rates are implemented to improve training efficiency while working within the constraints of PCM technology.Expand Specific Solutions03 Hardware-software co-design for PCM neural accelerators
Hardware-software co-design approaches optimize PCM-based neural accelerator training workflows by creating specialized instruction sets and programming models that leverage PCM characteristics. These approaches include compiler optimizations, custom APIs, and runtime systems that efficiently map neural network operations to PCM hardware, balancing computational requirements with memory access patterns to maximize throughput and energy efficiency.Expand Specific Solutions04 PCM device characteristics and reliability for neural training
PCM device characteristics significantly impact neural network training workflows. Techniques to address PCM's inherent variability, drift, and limited endurance are essential for reliable neural network training. These include error correction mechanisms, redundancy schemes, and wear-leveling techniques that distribute write operations evenly across the memory array, extending device lifetime while maintaining training accuracy.Expand Specific Solutions05 System-level integration of PCM-based neural accelerators
System-level integration approaches for PCM-based neural accelerators focus on efficiently incorporating these devices into larger computing systems. This includes designing memory hierarchies that leverage PCM alongside traditional memory technologies, developing data movement strategies that minimize bottlenecks, and creating power management techniques that exploit PCM's non-volatility. These approaches enable scalable training workflows across distributed computing environments.Expand Specific Solutions
Leading Companies in PCM Neural Accelerator Space
The analog training workflows for PCM-based neural accelerators market is in an early growth stage, characterized by significant research activity but limited commercial deployment. The global neuromorphic computing market, which encompasses this technology, is projected to reach $8-10 billion by 2028, with PCM-based solutions representing an emerging segment. Technologically, this field remains in development with varying maturity levels across key players. IBM leads with extensive PCM research and neuromorphic computing patents, while Samsung, Intel, and Huawei are advancing hardware implementations. Academic institutions like Fudan University and Harbin Institute of Technology contribute fundamental research, while specialized startups like Innatera and Polyn Technology are developing novel analog AI chip architectures. The ecosystem is evolving through collaborative efforts between established semiconductor companies and research institutions to address challenges in training efficiency and hardware reliability.
International Business Machines Corp.
Technical Solution: IBM has pioneered PCM-based neural accelerators with their analog AI hardware approach. Their technology utilizes phase-change memory (PCM) devices as artificial synapses in neural networks, enabling in-memory computing where calculations occur directly within memory arrays rather than shuttling data between separate processing and memory units. IBM's analog training workflow involves programming PCM cells to specific conductance states that represent synaptic weights, with incremental weight updates performed through precise electrical pulses. Their architecture implements backpropagation directly in the analog domain, using a combination of forward passes through PCM crossbar arrays and backward passes for weight updates[1]. IBM has demonstrated this technology in their analog AI chip that achieves 8-bit precision for training and can perform 14.4 trillion operations per second per watt, representing a 100x improvement in energy efficiency compared to digital architectures[3].
Strengths: Significantly higher energy efficiency compared to digital implementations; reduced memory-processor bottleneck; compact hardware footprint enabling edge deployment. Weaknesses: PCM device variability and drift requiring specialized compensation algorithms; limited precision compared to floating-point digital systems; challenges in scaling to larger networks due to analog signal degradation.
Huawei Technologies Co., Ltd.
Technical Solution: Huawei has developed a hybrid digital-analog approach for PCM-based neural accelerators, focusing on optimizing the training workflow for edge AI applications. Their solution employs a mixed-precision strategy where high-precision digital operations handle critical parts of the training process while analog PCM arrays perform matrix multiplications and weight storage. Huawei's training workflow incorporates a novel conductance mapping scheme that addresses the non-linear characteristics of PCM devices, enabling more accurate weight representation[2]. The company has implemented a specialized programming protocol that minimizes the impact of device-to-device variations through an iterative verification and reprogramming process. Their architecture includes on-chip temperature compensation circuits that dynamically adjust programming parameters to maintain consistent PCM behavior across varying operating conditions. Huawei has reported achieving training accuracy within 1% of purely digital implementations while reducing energy consumption by approximately 40x for convolutional neural networks[4].
Strengths: Balanced approach combining digital precision where needed with analog efficiency; robust compensation mechanisms for PCM variability; practical focus on deployable edge AI solutions. Weaknesses: More complex control circuitry than pure analog approaches; higher power consumption than fully analog systems; requires specialized software frameworks to optimize the hybrid workflow.
Key PCM Training Algorithm Innovations
Pulsing synaptic devices based on phase-change memory to increase the linearity in weight update
PatentWO2022268416A1
Innovation
- The method involves modifying the RESET pulse, applying a post-RESET annealing pulse, and adjusting the weight update pulse width and amplitude to increase the linearity of weight updates in PCM cells, allowing for incremental conductance changes and achieving intermediate resistance states by using a combination of modified RESET, incubation, and pre-annealing pulses.
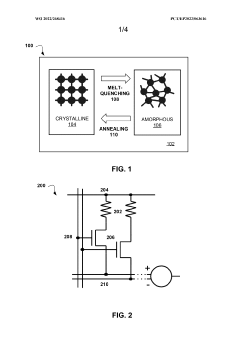
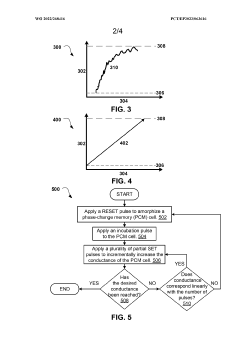
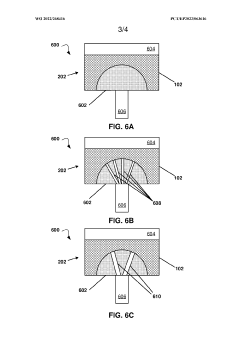
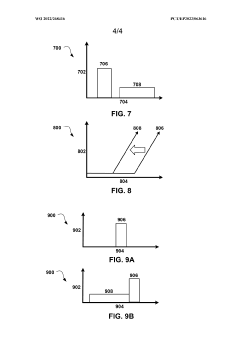
Multi-layer phase change memory device
PatentActiveUS11889773B2
Innovation
- A PCM cell design featuring multiple phase change layers with varying thicknesses and resistivities, including a doped phase change layer and undoped phase change layers, allows for controlled amorphous and polycrystalline configurations, enhancing resistance state retention and programming efficiency by utilizing a mixture of phase change materials and dopant materials.
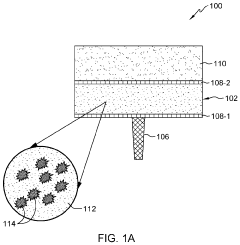
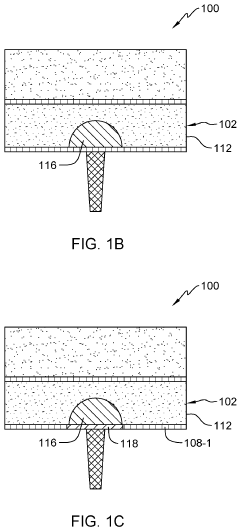
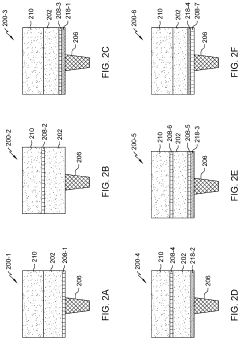
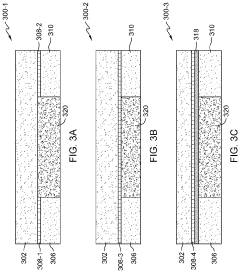
Energy Efficiency Benchmarking
Energy efficiency represents a critical benchmark for evaluating PCM-based neural accelerators, particularly when implementing analog training workflows. Current benchmarking data indicates that these accelerators can achieve significant energy savings compared to conventional digital implementations, with some studies reporting efficiency improvements of 10-100x for specific neural network operations.
The energy consumption profile of PCM-based accelerators shows distinct advantages during the forward pass computation, where matrix-vector multiplications are performed in the analog domain. This operation typically consumes only 1-10 pJ per multiply-accumulate operation, compared to 100-1000 pJ in digital CMOS implementations. However, the energy efficiency advantage narrows during the backward pass and weight update phases of training, where additional peripheral circuitry is required.
Systematic benchmarking across different network architectures reveals that energy efficiency varies significantly with network topology and training algorithm modifications. Convolutional neural networks (CNNs) demonstrate particularly favorable energy scaling on PCM-based platforms, while recurrent architectures present additional challenges due to their sequential nature and frequent weight updates.
Temperature sensitivity emerges as a critical factor affecting energy efficiency benchmarks. PCM devices exhibit temperature-dependent resistance drift, requiring additional compensation circuitry that can increase overall energy consumption by 15-30% under variable operating conditions. This represents an important consideration for deployment scenarios with fluctuating thermal environments.
Recent benchmarking studies have established standardized metrics for comparing energy efficiency across different analog training implementations. These include Energy-Delay Product (EDP), Training Energy per Sample (TEPS), and Energy-Accuracy Pareto frontiers. These metrics provide a more nuanced understanding of the tradeoffs between computational speed, energy consumption, and model accuracy.
Industry consortia have begun establishing standardized benchmarking methodologies specifically for emerging non-volatile memory-based neural accelerators. These methodologies account for both the computational energy and the often-overlooked data movement energy between on-chip components, which can dominate the overall energy profile in practical implementations.
Looking forward, energy efficiency benchmarking must evolve to incorporate long-term reliability considerations, as PCM device characteristics change over repeated training cycles. Early data suggests that adaptive training algorithms can maintain energy efficiency advantages even as devices age, though this remains an active area of research requiring more comprehensive benchmarking protocols.
The energy consumption profile of PCM-based accelerators shows distinct advantages during the forward pass computation, where matrix-vector multiplications are performed in the analog domain. This operation typically consumes only 1-10 pJ per multiply-accumulate operation, compared to 100-1000 pJ in digital CMOS implementations. However, the energy efficiency advantage narrows during the backward pass and weight update phases of training, where additional peripheral circuitry is required.
Systematic benchmarking across different network architectures reveals that energy efficiency varies significantly with network topology and training algorithm modifications. Convolutional neural networks (CNNs) demonstrate particularly favorable energy scaling on PCM-based platforms, while recurrent architectures present additional challenges due to their sequential nature and frequent weight updates.
Temperature sensitivity emerges as a critical factor affecting energy efficiency benchmarks. PCM devices exhibit temperature-dependent resistance drift, requiring additional compensation circuitry that can increase overall energy consumption by 15-30% under variable operating conditions. This represents an important consideration for deployment scenarios with fluctuating thermal environments.
Recent benchmarking studies have established standardized metrics for comparing energy efficiency across different analog training implementations. These include Energy-Delay Product (EDP), Training Energy per Sample (TEPS), and Energy-Accuracy Pareto frontiers. These metrics provide a more nuanced understanding of the tradeoffs between computational speed, energy consumption, and model accuracy.
Industry consortia have begun establishing standardized benchmarking methodologies specifically for emerging non-volatile memory-based neural accelerators. These methodologies account for both the computational energy and the often-overlooked data movement energy between on-chip components, which can dominate the overall energy profile in practical implementations.
Looking forward, energy efficiency benchmarking must evolve to incorporate long-term reliability considerations, as PCM device characteristics change over repeated training cycles. Early data suggests that adaptive training algorithms can maintain energy efficiency advantages even as devices age, though this remains an active area of research requiring more comprehensive benchmarking protocols.
Hardware-Software Co-design Strategies
The effective implementation of analog training workflows for PCM-based neural accelerators requires sophisticated hardware-software co-design strategies that bridge the gap between algorithmic requirements and physical device characteristics. These strategies must address the unique challenges posed by phase-change memory (PCM) devices while maximizing their potential for neural network training acceleration.
A fundamental co-design approach involves developing specialized instruction sets and compiler optimizations that can efficiently map neural network operations onto PCM arrays. This requires careful consideration of the analog computation patterns and the inherent variability of PCM cells. Compiler frameworks must incorporate device-aware optimizations that account for PCM-specific characteristics such as asymmetric write operations, limited endurance, and drift compensation requirements.
Memory hierarchy optimization represents another critical co-design strategy. By intelligently partitioning neural network parameters between PCM arrays and conventional memory, system architects can balance performance, energy efficiency, and reliability. This typically involves keeping frequently updated weights in more robust memory while leveraging PCM for parameters that require less frequent modifications or can tolerate higher variability.
Runtime adaptation mechanisms form an essential component of effective co-design strategies. These mechanisms dynamically adjust training parameters based on real-time feedback from PCM arrays, compensating for device-level variations and aging effects. Adaptive precision scaling techniques can be implemented to maintain training accuracy while working within the constraints of analog PCM operations.
Power management co-design is particularly important for PCM-based accelerators due to the significant energy requirements of phase-change operations. Intelligent scheduling algorithms that minimize unnecessary write operations and optimize read sequences can substantially reduce power consumption while maintaining training performance. This includes techniques such as selective parameter updates and gradient sparsification tailored specifically for PCM characteristics.
Error resilience frameworks represent a sophisticated co-design strategy that spans both hardware and software domains. These frameworks incorporate statistical error models of PCM devices directly into training algorithms, allowing neural networks to learn effectively despite device-level imperfections. Techniques such as noise-aware backpropagation and stochastic rounding can transform PCM's inherent variability from a liability into a potential regularization benefit.
Finally, simulation and modeling tools that accurately capture the behavior of PCM devices are essential for effective co-design. These tools enable software developers to optimize training algorithms without requiring constant access to physical hardware, accelerating the development cycle and facilitating exploration of novel co-design approaches.
A fundamental co-design approach involves developing specialized instruction sets and compiler optimizations that can efficiently map neural network operations onto PCM arrays. This requires careful consideration of the analog computation patterns and the inherent variability of PCM cells. Compiler frameworks must incorporate device-aware optimizations that account for PCM-specific characteristics such as asymmetric write operations, limited endurance, and drift compensation requirements.
Memory hierarchy optimization represents another critical co-design strategy. By intelligently partitioning neural network parameters between PCM arrays and conventional memory, system architects can balance performance, energy efficiency, and reliability. This typically involves keeping frequently updated weights in more robust memory while leveraging PCM for parameters that require less frequent modifications or can tolerate higher variability.
Runtime adaptation mechanisms form an essential component of effective co-design strategies. These mechanisms dynamically adjust training parameters based on real-time feedback from PCM arrays, compensating for device-level variations and aging effects. Adaptive precision scaling techniques can be implemented to maintain training accuracy while working within the constraints of analog PCM operations.
Power management co-design is particularly important for PCM-based accelerators due to the significant energy requirements of phase-change operations. Intelligent scheduling algorithms that minimize unnecessary write operations and optimize read sequences can substantially reduce power consumption while maintaining training performance. This includes techniques such as selective parameter updates and gradient sparsification tailored specifically for PCM characteristics.
Error resilience frameworks represent a sophisticated co-design strategy that spans both hardware and software domains. These frameworks incorporate statistical error models of PCM devices directly into training algorithms, allowing neural networks to learn effectively despite device-level imperfections. Techniques such as noise-aware backpropagation and stochastic rounding can transform PCM's inherent variability from a liability into a potential regularization benefit.
Finally, simulation and modeling tools that accurately capture the behavior of PCM devices are essential for effective co-design. These tools enable software developers to optimize training algorithms without requiring constant access to physical hardware, accelerating the development cycle and facilitating exploration of novel co-design approaches.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!