

Method for constructing webpage crawler based on repeated removal of news
A web crawler and construction method technology, applied in special data processing applications, instruments, electrical and digital data processing, etc., can solve problems such as low algorithm efficiency, large waste of resources, and difficulty in data maintenance, and achieve convenient data maintenance and small waste of resources. , the effect of saving storage resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
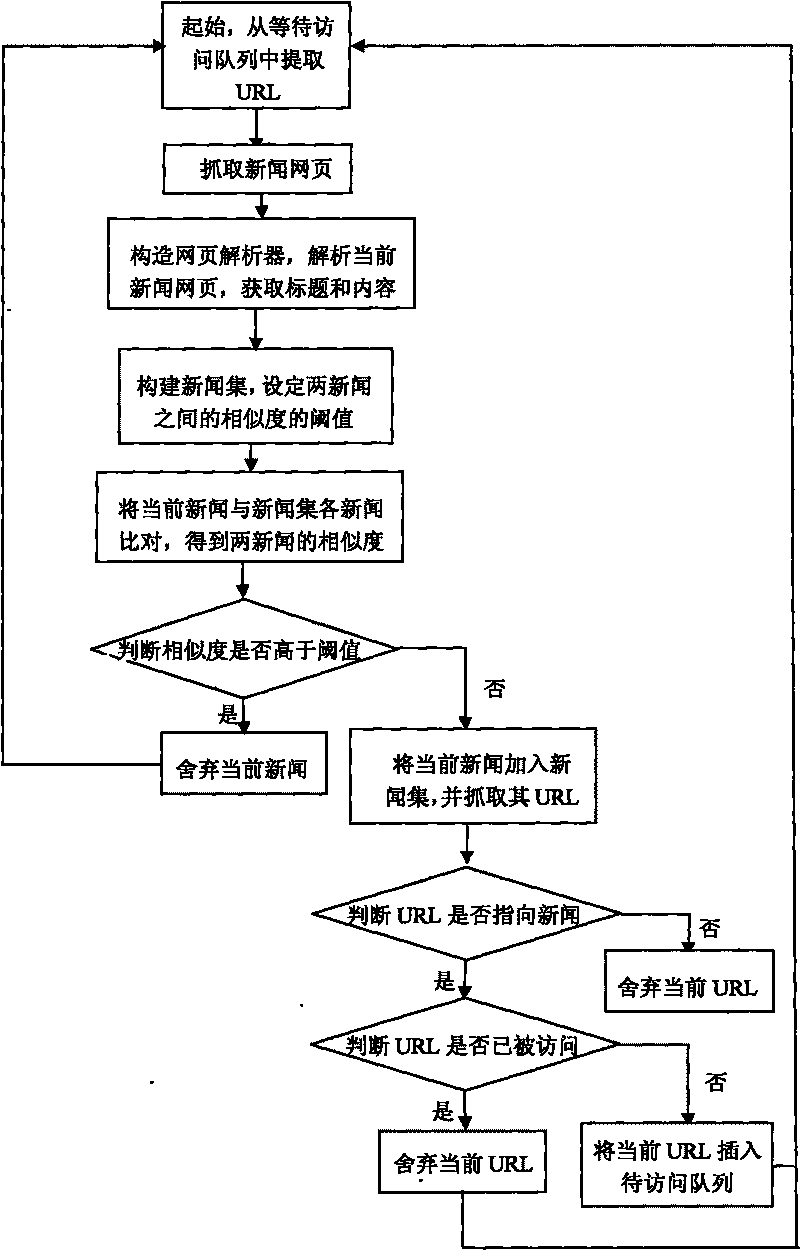
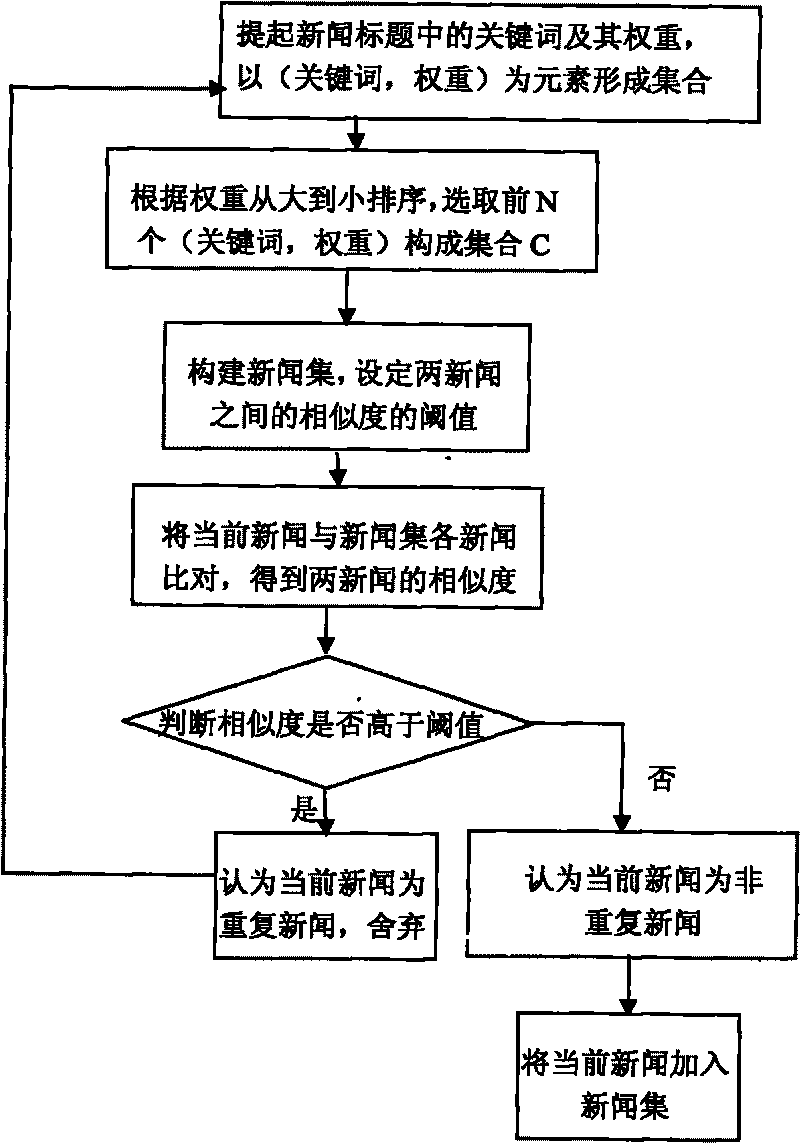
[0041] Refer to attached figure 1 , 2 、4
[0042] A method for constructing a web crawler based on deduplication of news, comprising the following steps:
[0043] 1. A method for constructing a web crawler based on deduplication of news, comprising the following steps:
[0044] 1), construct the parser that can extract the title and content of the news in the webpage, and analyze the news webpage with the parser;
[0045] 2), build the collection of news web pages to form a news collection; set the threshold value of the similarity between the webpage currently grabbed and the news web pages in the news collection, and the similarity is characterized by the degree of repetition of the content;
[0046]3), comparing the currently captured news webpage with the news collection, and judging whether the similarity between them is higher than the threshold;
[0047] (3.1) Extract the keywords in the text and the weight of each keyword from the text of the news title using Chine...
Embodiment 2
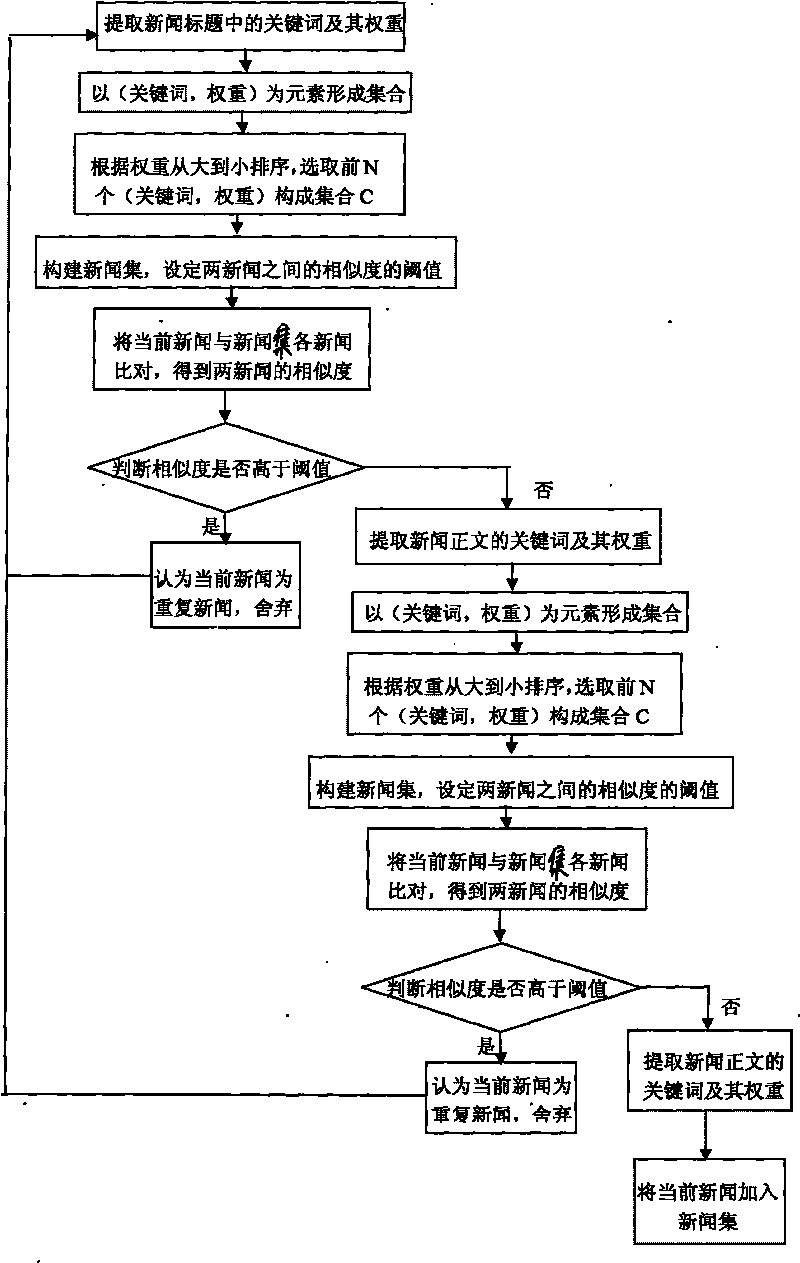
[0063] Refer to attached figure 1 , 3 、4
[0064] The difference between the present embodiment and the first embodiment is: if the set C is judged to be non-repetitive news through (3.4), then the news body text is extracted using the Chinese word segmentation technology to extract the keywords and the weight of each keyword in the text, Perform (3.2) to (3.4) in sequence again; if this judgment is still non-repeating news, then add this news to the news set. The rest is the same.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More