

Method and device for extracting information based on multistage rule base
A technology of information extraction and rules, applied in the fields of instruments, computing, electrical and digital data processing, etc., can solve the problems of low accuracy, low degree of automation, complex structure, etc., to achieve the effect of low price and improve the degree of automation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0046] The present invention will be further described below in conjunction with drawings and embodiments.
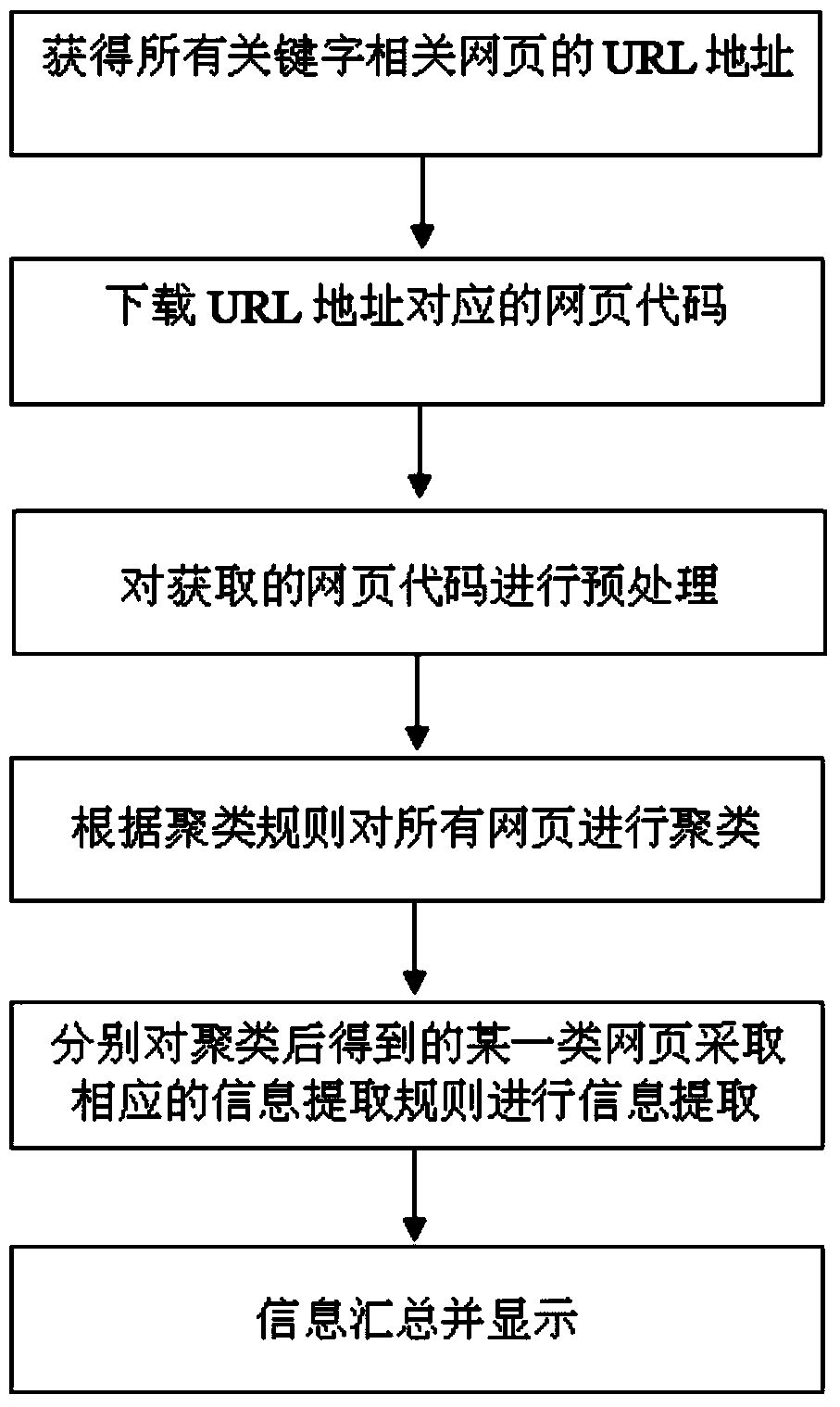
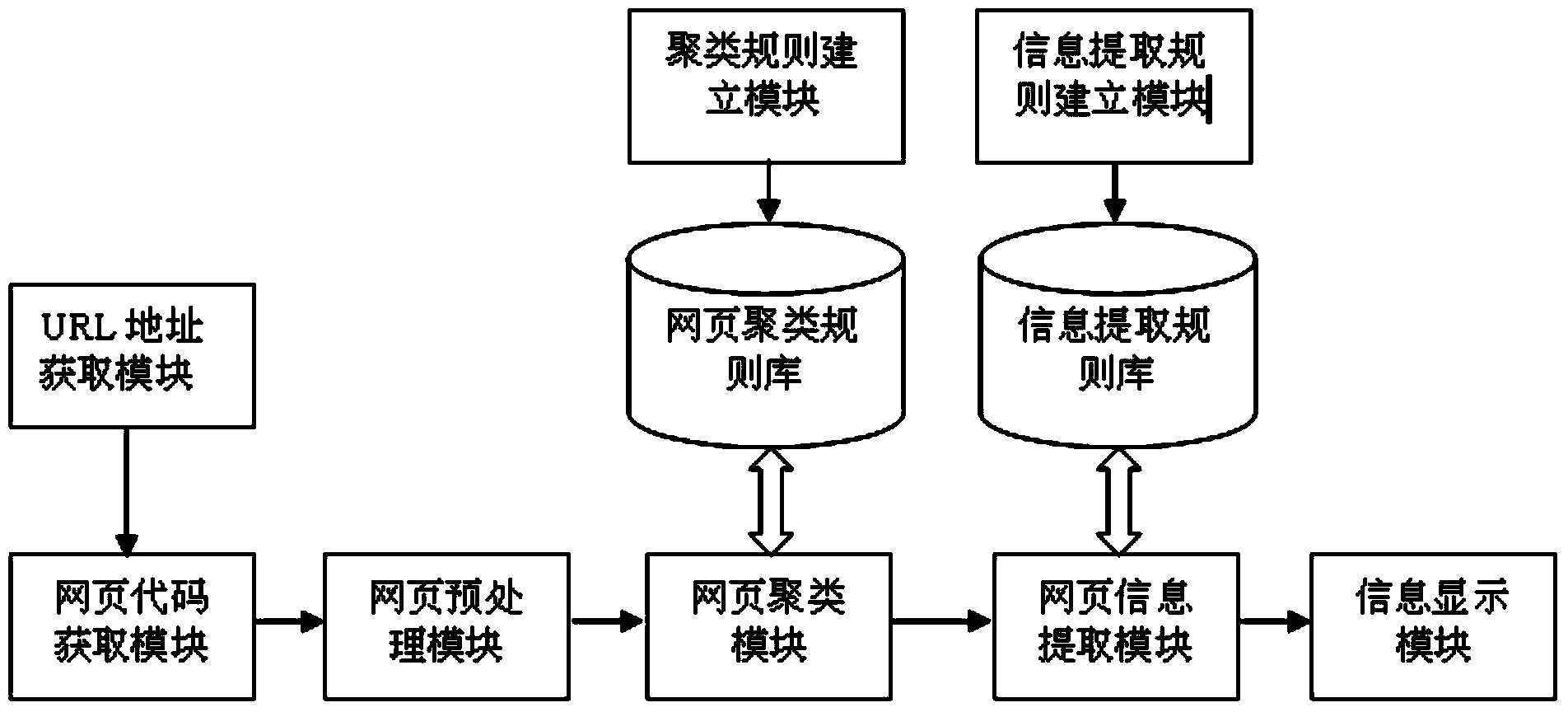
[0047] An information extraction method based on a multi-level rule base, the specific steps are as follows:
[0048]1) URL address acquisition. Firstly, the search sequence is used to search the relevant webpages of the search keyword to obtain the URL address of the webpage. The URL addresses obtained here cover all URL addresses related to the query sequence, and are a large number of addresses, not a single address.
[0049] 2) Web page download. Use web crawler technology to download relevant web page codes for the obtained web page URL addresses.
[0050] 3) Web page preprocessing. Process the obtained web pages to obtain a standard Dom Tree. Including: webpage cleaning, DOM analysis and graphical display of webpage structure.
[0051] Web page cleaning refers to: repairing and converting HTML pages into standard XML documents. Since HTML does not strictly ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More