

Structure extended polynomial naive Bayes text classification method
A text classification, polynomial technology, applied in the direction of unstructured text data retrieval, text database clustering/classification, special data processing applications, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

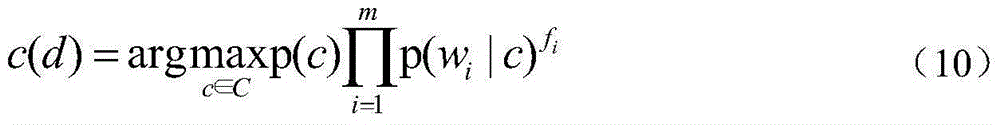

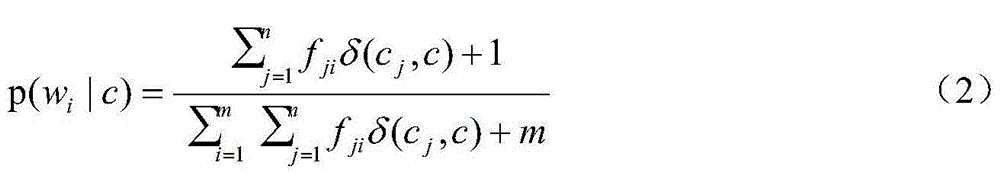
Examples
Embodiment Construction
[0040] In the following, the present invention will be further described in conjunction with the embodiments.
[0041] The present invention provides a polynomial naive Bayes text classification method with extended structure, including a training phase and a classification phase, wherein,
[0042] (1) The training phase includes the following processes:
[0043] (1-1) Use the following formula to calculate the prior probability p(c) of each category in the training document set D:
[0044] p ( c ) = X j = 1 n δ ( c j , c ) + 1 n + s - - - ( 1 )
[0045] Among them, the training document set D is a known document set, and any document d in the training document set D is expressed as a word vector form d= 1 ,w 2 ,...w m > , Where w i Is the i-th word in document d, m is the number of words in training document set D; n is the number of documents in training document set D, s is the number of document categories...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More