

N-gram grammar model constructing method for voice identification and voice identification system
An n-gram grammar and speech recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of limited data volume, time-consuming and labor-intensive, etc., and achieve the effect of effective control, alleviation of sparsity, and optimization of the language model part.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

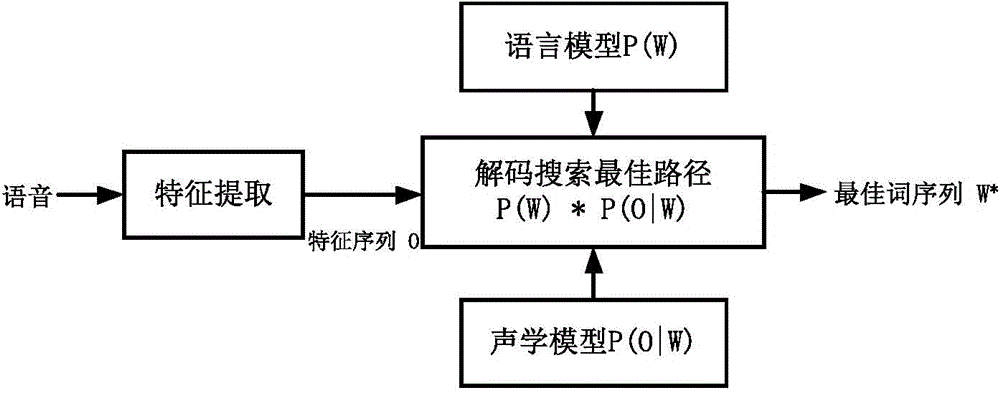
Examples
Embodiment Construction
[0028] The solution of the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
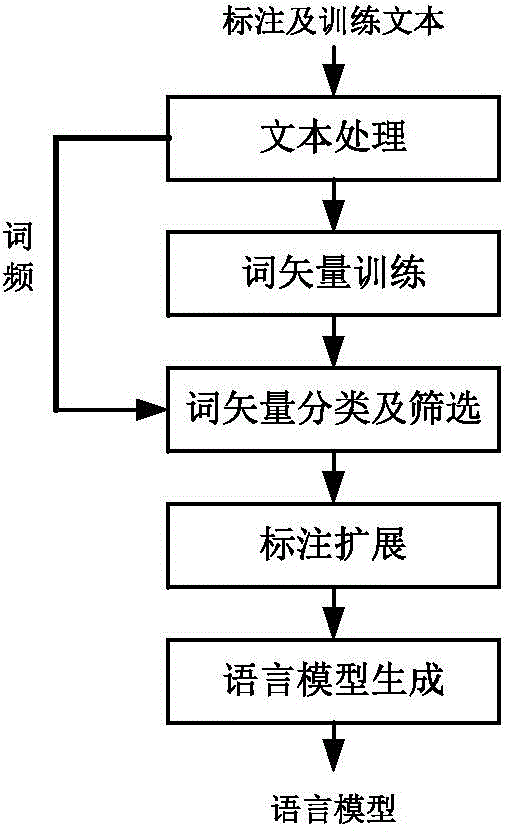
[0029] The process flow of the n-gram grammar model construction method based on word vector expansion manual labeling process provided by the present invention is as follows figure 1 As shown, specifically include:
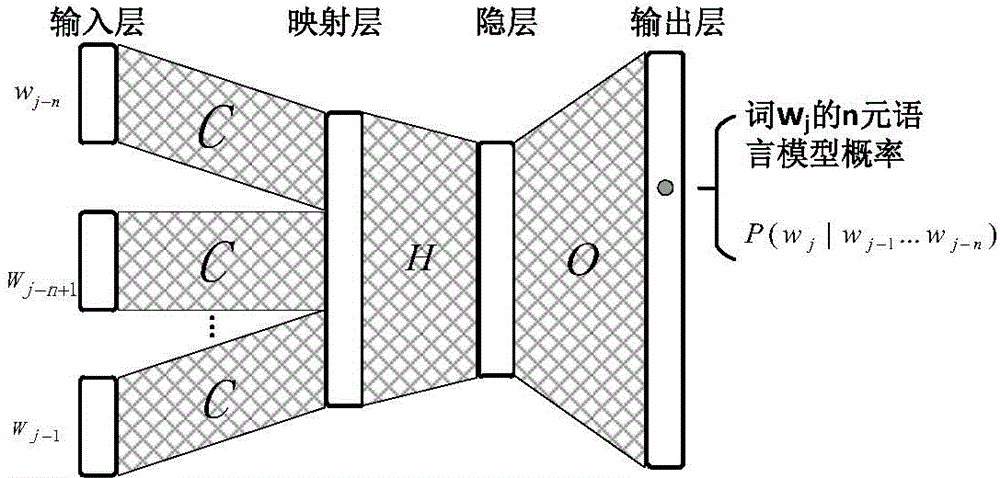
[0030] 1. Word vector training: The corresponding word vectors of the words in the dictionary are obtained through neural network language model training. The training adopts the classic NNLM form, and its structure diagram is as follows figure 2 shown.
[0031] The model consists of input layer, mapping layer, hidden layer and output layer. Each word in the dictionary is represented by a vector whose dimension is the size of the dictionary, with 1 in the position of the word and 0 in the remaining dimensions. For the n-gram model, the input layer input is a long vector composed of "n-1" word vectors connect...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More