

Duplication elimination method based on search results of metasearch engine
A meta-search engine and search result technology, which is applied in network data retrieval, other database retrieval, web data retrieval using information identifiers, etc., can solve the problems that the same webpage cannot be deduplicated, and redirected webpages cannot be deduplicated, etc. Achieve obvious effect of de-weighting effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

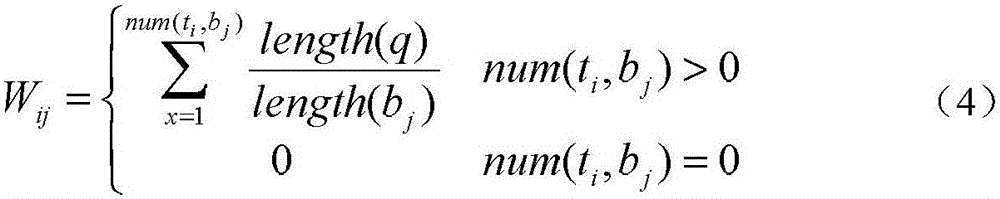
Examples
specific Embodiment approach 1
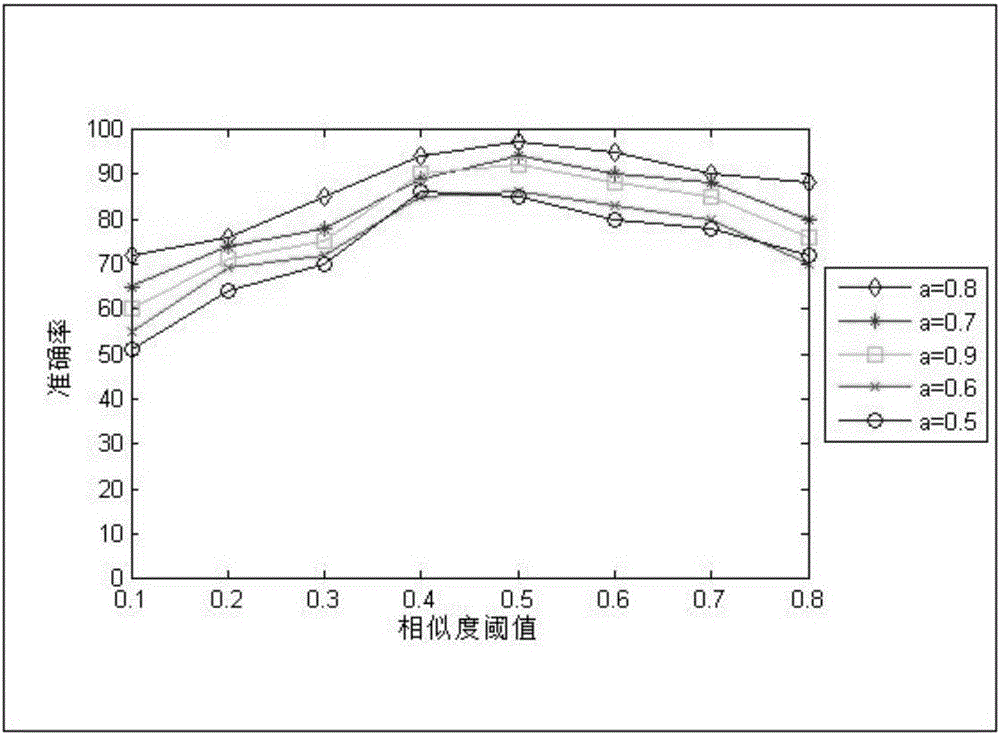
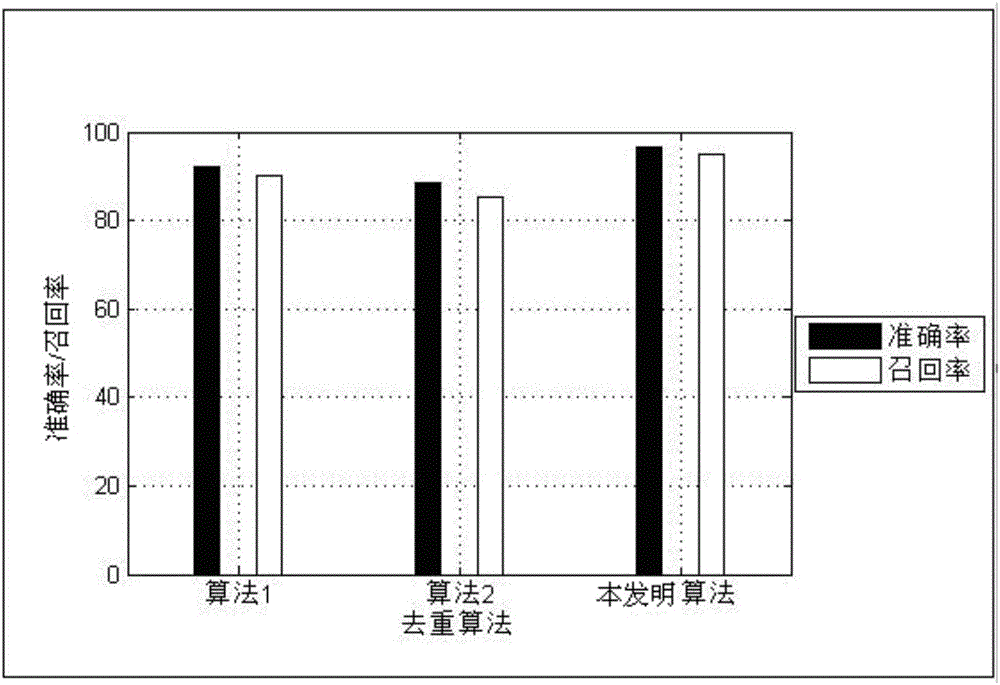
[0032] Embodiment 1: The method for removing duplicates based on meta-search engine search results in this embodiment is specifically prepared according to the following steps:
[0033]Step 1: Judging according to the URL of the returned webpage (the result of the search engine search), unifying the URL formats of two or more return webpages, and judging that the two or more return webpages after the unified format are Whether the URL addresses are consistent, if the URL addresses are the same, it is considered a duplicate web page; the judgment based on the URL address is divided into two cases: one is the direct comparison method of the URL address normalization, and the other is the redirection situation for the URL address Judgment method; through the judgment of the above two cases, it is much more comprehensive than directly comparing the URL addresses of web pages;
[0034] Step 2. If it is judged by step 1 that it is not a duplicate web page, go to the next step to jud...
specific Embodiment approach 2
[0045] Embodiment 2: The difference between this embodiment and Embodiment 1 is that the method for direct comparison of URL address normalization in step 1 is specifically:
[0046] The direct comparison method of URL address normalization is very efficient, but some web pages are not in the standard URL format, and some URLs are partially defaulted, so the format of the URL address is unified first, that is, both URLs include Protocol name, host domain name, path and file name four elements; if the URL includes the same protocol name, host domain name, path and file name, the webpage is judged to be a duplicate webpage;
[0047] If there is no file name, add " / index.html", and convert it to ".html" for the suffix ".htm"; for example:
[0048] www.hrbeu.edu.cn
[0049] After normalization, it is
[0050] http: / / www.hrbeu.edu.cn / index.html
[0051] Both point to the same web page, so it is considered to be a duplicate web page, which can detect many situations, such as ...
specific Embodiment approach 3
[0052] Embodiment 3: This embodiment is different from Embodiment 1 or 2 in that: the method for judging the redirection situation of the URL address in step 1 is specifically:
[0053] According to the redirection of the URL address, some web pages are pointed to multiple times in the same website, that is, the URL address is changed, the old URL is redirected to the new URL, the web page file name is the same as the host domain name, the path is different, and the title is the same , the webpage is judged to be a duplicate webpage. Other steps and parameters are the same as in the first or second embodiment.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More