

SLAM Algorithms Optimized For Edge AI Hardware
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
SLAM-Edge AI Integration Background and Objectives
Simultaneous Localization and Mapping (SLAM) technology has evolved significantly over the past three decades, transitioning from theoretical research to practical applications across various domains. Initially developed for robotics navigation in controlled environments, SLAM algorithms have progressively adapted to more complex scenarios including autonomous vehicles, augmented reality, and industrial automation. The convergence of SLAM with Edge AI represents a pivotal advancement in this technological trajectory, addressing critical limitations of traditional cloud-dependent implementations.
Edge AI hardware, characterized by its ability to process data locally with minimal latency, has emerged as a compelling platform for SLAM deployment. This integration aims to overcome fundamental challenges in real-time spatial mapping and localization by leveraging the computational efficiency of specialized AI accelerators while maintaining operation within strict power and form factor constraints typical of edge devices.
The primary technical objective of optimizing SLAM algorithms for Edge AI hardware is to achieve robust real-time performance without compromising accuracy or reliability. This entails redesigning computational pipelines to exploit hardware-specific features such as tensor processing units, neural processing units, and specialized vision processing units that are increasingly common in modern edge computing platforms.
A secondary but equally important goal is reducing the energy footprint of SLAM operations, enabling longer operational periods for battery-powered devices such as drones, mobile robots, and wearable AR systems. This energy efficiency objective necessitates novel approaches to algorithm design that prioritize computational efficiency alongside traditional metrics of mapping accuracy and localization precision.
The evolution of SLAM technology is further driven by the need for enhanced adaptability across diverse environmental conditions. Current research focuses on developing algorithms capable of functioning reliably in challenging scenarios including low-light conditions, dynamic environments with moving objects, and visually repetitive or feature-poor settings that traditionally confound vision-based SLAM systems.
From an architectural perspective, the integration aims to establish a more balanced distribution of computational workloads between specialized hardware components, optimizing parallel processing capabilities while minimizing data transfer bottlenecks. This requires fundamental rethinking of traditional SLAM pipelines, potentially incorporating neural network approaches for feature extraction, loop closure detection, and map optimization tasks traditionally handled by classical computer vision techniques.
The technological trajectory suggests a progressive convergence toward hybrid systems that combine the robustness of geometric SLAM approaches with the adaptability of learning-based methods, all optimized for the specific constraints and capabilities of edge computing platforms.
Edge AI hardware, characterized by its ability to process data locally with minimal latency, has emerged as a compelling platform for SLAM deployment. This integration aims to overcome fundamental challenges in real-time spatial mapping and localization by leveraging the computational efficiency of specialized AI accelerators while maintaining operation within strict power and form factor constraints typical of edge devices.
The primary technical objective of optimizing SLAM algorithms for Edge AI hardware is to achieve robust real-time performance without compromising accuracy or reliability. This entails redesigning computational pipelines to exploit hardware-specific features such as tensor processing units, neural processing units, and specialized vision processing units that are increasingly common in modern edge computing platforms.
A secondary but equally important goal is reducing the energy footprint of SLAM operations, enabling longer operational periods for battery-powered devices such as drones, mobile robots, and wearable AR systems. This energy efficiency objective necessitates novel approaches to algorithm design that prioritize computational efficiency alongside traditional metrics of mapping accuracy and localization precision.
The evolution of SLAM technology is further driven by the need for enhanced adaptability across diverse environmental conditions. Current research focuses on developing algorithms capable of functioning reliably in challenging scenarios including low-light conditions, dynamic environments with moving objects, and visually repetitive or feature-poor settings that traditionally confound vision-based SLAM systems.
From an architectural perspective, the integration aims to establish a more balanced distribution of computational workloads between specialized hardware components, optimizing parallel processing capabilities while minimizing data transfer bottlenecks. This requires fundamental rethinking of traditional SLAM pipelines, potentially incorporating neural network approaches for feature extraction, loop closure detection, and map optimization tasks traditionally handled by classical computer vision techniques.
The technological trajectory suggests a progressive convergence toward hybrid systems that combine the robustness of geometric SLAM approaches with the adaptability of learning-based methods, all optimized for the specific constraints and capabilities of edge computing platforms.
Market Analysis for Edge-Based SLAM Applications
The SLAM (Simultaneous Localization and Mapping) technology market for edge computing applications is experiencing robust growth, driven by increasing demand for autonomous systems across multiple industries. Current market valuations place the global edge-based SLAM market at approximately $2.1 billion in 2023, with projections indicating a compound annual growth rate of 25-30% over the next five years.
The automotive sector represents the largest market segment, accounting for roughly 38% of edge-based SLAM applications. This is primarily fueled by the rapid development of advanced driver-assistance systems (ADAS) and autonomous vehicles, where low-latency processing of environmental data is critical for safe operation. Major automotive manufacturers and tier-one suppliers are increasingly integrating edge-optimized SLAM solutions into their product roadmaps.
Consumer robotics constitutes the second-largest market segment at 27%, encompassing vacuum cleaners, delivery robots, and personal assistant robots. This segment shows the highest growth potential due to decreasing hardware costs and increasing consumer acceptance of smart home technologies. Companies like iRobot, Ecovacs, and Xiaomi are leading innovation in this space.
Industrial applications, including warehouse automation, manufacturing robots, and inspection drones, represent approximately 22% of the market. These applications demand highly reliable SLAM solutions capable of operating in challenging environments with minimal computational resources. The industrial segment is characterized by its emphasis on robustness and precision over raw processing speed.
Augmented reality and mobile devices form an emerging segment (13%) with significant growth potential. As AR applications become more sophisticated, the demand for efficient SLAM algorithms that can run on mobile processors is increasing. Apple's ARKit and Google's ARCore have established foundational platforms, but significant opportunities remain for optimization.
Geographically, North America leads with 42% market share, followed by Asia-Pacific (31%) and Europe (24%). However, the Asia-Pacific region is expected to show the fastest growth rate due to rapid industrial automation in China, Japan, and South Korea, coupled with substantial investments in autonomous vehicle technology.
Key market drivers include decreasing costs of edge AI hardware, increasing demand for real-time processing capabilities, and growing applications in previously untapped sectors. Barriers to wider adoption include power consumption constraints, accuracy limitations in complex environments, and the need for specialized expertise in algorithm optimization for specific hardware architectures.
The automotive sector represents the largest market segment, accounting for roughly 38% of edge-based SLAM applications. This is primarily fueled by the rapid development of advanced driver-assistance systems (ADAS) and autonomous vehicles, where low-latency processing of environmental data is critical for safe operation. Major automotive manufacturers and tier-one suppliers are increasingly integrating edge-optimized SLAM solutions into their product roadmaps.
Consumer robotics constitutes the second-largest market segment at 27%, encompassing vacuum cleaners, delivery robots, and personal assistant robots. This segment shows the highest growth potential due to decreasing hardware costs and increasing consumer acceptance of smart home technologies. Companies like iRobot, Ecovacs, and Xiaomi are leading innovation in this space.
Industrial applications, including warehouse automation, manufacturing robots, and inspection drones, represent approximately 22% of the market. These applications demand highly reliable SLAM solutions capable of operating in challenging environments with minimal computational resources. The industrial segment is characterized by its emphasis on robustness and precision over raw processing speed.
Augmented reality and mobile devices form an emerging segment (13%) with significant growth potential. As AR applications become more sophisticated, the demand for efficient SLAM algorithms that can run on mobile processors is increasing. Apple's ARKit and Google's ARCore have established foundational platforms, but significant opportunities remain for optimization.
Geographically, North America leads with 42% market share, followed by Asia-Pacific (31%) and Europe (24%). However, the Asia-Pacific region is expected to show the fastest growth rate due to rapid industrial automation in China, Japan, and South Korea, coupled with substantial investments in autonomous vehicle technology.
Key market drivers include decreasing costs of edge AI hardware, increasing demand for real-time processing capabilities, and growing applications in previously untapped sectors. Barriers to wider adoption include power consumption constraints, accuracy limitations in complex environments, and the need for specialized expertise in algorithm optimization for specific hardware architectures.
SLAM on Edge AI: Current Limitations and Challenges
Despite significant advancements in SLAM (Simultaneous Localization and Mapping) algorithms, their deployment on edge AI hardware presents substantial challenges. The computational intensity of traditional SLAM approaches conflicts with the constrained resources available on edge devices, creating a fundamental tension between performance requirements and hardware limitations.
Edge AI hardware typically operates under severe power constraints, often limited to 1-5W compared to desktop GPUs consuming 200-300W. This power envelope restricts computational capabilities, memory bandwidth, and thermal management options. When SLAM algorithms—which traditionally rely on intensive matrix operations and iterative optimization—are deployed on such constrained platforms, performance degradation becomes inevitable without significant algorithmic adaptation.
Memory bandwidth limitations represent another critical bottleneck. High-resolution visual SLAM systems generate substantial data volumes that must be processed in real-time. Edge devices with limited memory interfaces (often 32-bit rather than 256-bit found in desktop systems) struggle to maintain the data throughput required for smooth operation, resulting in processing delays that compromise the real-time nature of SLAM applications.
The heterogeneous computing architecture of edge AI platforms presents additional integration challenges. While these platforms often incorporate specialized neural processing units (NPUs) and digital signal processors (DSPs) alongside traditional CPUs, effectively distributing SLAM workloads across these diverse computing elements requires sophisticated scheduling and optimization techniques that many current SLAM implementations lack.
Precision requirements further complicate edge deployment. Traditional SLAM algorithms typically operate with 32-bit floating-point precision, while edge AI accelerators often prioritize 8-bit or 16-bit fixed-point operations for efficiency. This precision mismatch necessitates careful quantization strategies that preserve mapping accuracy while reducing computational demands—a delicate balance that remains challenging to achieve.
Energy efficiency concerns extend beyond raw performance metrics. Battery-powered edge devices running SLAM applications must maintain operational longevity, requiring algorithms that minimize unnecessary computations. Current SLAM implementations often lack the dynamic scaling capabilities needed to adjust computational intensity based on available power resources or application requirements.
Finally, the diversity of edge hardware platforms creates significant fragmentation challenges. SLAM algorithms optimized for one edge AI architecture may perform poorly on others, necessitating either platform-specific optimizations or more flexible algorithmic approaches that can adapt to varying hardware capabilities—both representing substantial engineering challenges.
Edge AI hardware typically operates under severe power constraints, often limited to 1-5W compared to desktop GPUs consuming 200-300W. This power envelope restricts computational capabilities, memory bandwidth, and thermal management options. When SLAM algorithms—which traditionally rely on intensive matrix operations and iterative optimization—are deployed on such constrained platforms, performance degradation becomes inevitable without significant algorithmic adaptation.
Memory bandwidth limitations represent another critical bottleneck. High-resolution visual SLAM systems generate substantial data volumes that must be processed in real-time. Edge devices with limited memory interfaces (often 32-bit rather than 256-bit found in desktop systems) struggle to maintain the data throughput required for smooth operation, resulting in processing delays that compromise the real-time nature of SLAM applications.
The heterogeneous computing architecture of edge AI platforms presents additional integration challenges. While these platforms often incorporate specialized neural processing units (NPUs) and digital signal processors (DSPs) alongside traditional CPUs, effectively distributing SLAM workloads across these diverse computing elements requires sophisticated scheduling and optimization techniques that many current SLAM implementations lack.
Precision requirements further complicate edge deployment. Traditional SLAM algorithms typically operate with 32-bit floating-point precision, while edge AI accelerators often prioritize 8-bit or 16-bit fixed-point operations for efficiency. This precision mismatch necessitates careful quantization strategies that preserve mapping accuracy while reducing computational demands—a delicate balance that remains challenging to achieve.
Energy efficiency concerns extend beyond raw performance metrics. Battery-powered edge devices running SLAM applications must maintain operational longevity, requiring algorithms that minimize unnecessary computations. Current SLAM implementations often lack the dynamic scaling capabilities needed to adjust computational intensity based on available power resources or application requirements.
Finally, the diversity of edge hardware platforms creates significant fragmentation challenges. SLAM algorithms optimized for one edge AI architecture may perform poorly on others, necessitating either platform-specific optimizations or more flexible algorithmic approaches that can adapt to varying hardware capabilities—both representing substantial engineering challenges.
Current Optimization Approaches for Edge SLAM
01 Visual SLAM optimization techniques
Visual SLAM algorithms can be optimized through various techniques that enhance accuracy and efficiency in real-time mapping and localization. These techniques include improved feature extraction methods, robust pose estimation algorithms, and advanced camera calibration approaches. By optimizing the visual components of SLAM systems, the overall performance in dynamic environments can be significantly enhanced, leading to more accurate 3D reconstructions and better tracking capabilities.- Visual SLAM optimization techniques: Visual SLAM algorithms can be optimized through various techniques that enhance accuracy and efficiency in real-time mapping and localization. These optimizations include improved feature extraction methods, robust pose estimation algorithms, and advanced camera calibration techniques. By implementing these optimizations, visual SLAM systems can achieve better performance in challenging environments with varying lighting conditions and dynamic objects.
- Machine learning approaches for SLAM optimization: Machine learning techniques can significantly enhance SLAM algorithms by improving feature detection, loop closure identification, and trajectory prediction. Deep learning models can be trained to recognize patterns in sensor data, enabling more accurate mapping in complex environments. These approaches can adapt to different scenarios and improve the robustness of SLAM systems against noise and environmental variations.
- Sensor fusion for enhanced SLAM performance: Integrating multiple sensors such as cameras, LiDAR, IMU, and GPS can optimize SLAM algorithms by leveraging complementary data sources. Sensor fusion techniques help overcome limitations of individual sensors, providing more robust localization and mapping capabilities. Advanced filtering methods like Kalman filters and particle filters can be employed to combine data from different sensors effectively, resulting in improved accuracy and reliability in diverse environments.
- Real-time computational efficiency improvements: Optimizing SLAM algorithms for real-time performance involves reducing computational complexity while maintaining accuracy. Techniques include parallel processing, algorithm simplification, and efficient data structures. Hardware acceleration using GPUs or specialized processors can significantly improve processing speed. These optimizations enable SLAM systems to operate effectively on resource-constrained platforms such as mobile devices, drones, and autonomous vehicles.
- Loop closure and drift correction methods: Advanced loop closure detection and drift correction techniques are essential for optimizing SLAM algorithms. These methods identify when a system revisits previously mapped areas and adjust the map accordingly to reduce accumulated errors. Graph-based optimization approaches can refine the entire trajectory and map structure when loops are detected. Implementing efficient loop closure algorithms improves long-term mapping accuracy and enables consistent localization in extended operations.
02 Machine learning approaches for SLAM optimization
Machine learning techniques can be applied to optimize SLAM algorithms by improving pattern recognition, feature matching, and prediction capabilities. Deep learning models can be trained to enhance loop closure detection, reduce drift, and better handle environmental variations. These approaches enable SLAM systems to adapt to different scenarios and improve their performance through continuous learning from collected data, resulting in more robust navigation solutions for autonomous systems.Expand Specific Solutions03 Sensor fusion for enhanced SLAM performance
Integrating multiple sensors such as LiDAR, cameras, IMUs, and radar can optimize SLAM algorithms by leveraging complementary data sources. Sensor fusion techniques help overcome limitations of individual sensors, providing more comprehensive environmental perception and improving localization accuracy in challenging conditions. Advanced filtering methods and calibration techniques ensure proper alignment of data from different sensors, resulting in more reliable mapping and navigation capabilities.Expand Specific Solutions04 Computational efficiency improvements in SLAM
Optimizing the computational aspects of SLAM algorithms involves techniques such as parallel processing, algorithm simplification, and memory management strategies. These improvements enable real-time performance on resource-constrained devices while maintaining accuracy. Techniques like sparse matrix operations, keyframe selection, and efficient loop closure detection contribute to reducing computational load while preserving mapping quality, making SLAM more practical for mobile robots and AR/VR applications.Expand Specific Solutions05 Dynamic environment handling in SLAM
Optimizing SLAM algorithms for dynamic environments involves developing methods to identify and filter out moving objects, adapt to changing scenes, and maintain map consistency over time. These techniques include motion segmentation, dynamic object tracking, and map updating strategies that can distinguish between permanent and temporary features. By effectively handling dynamic elements, SLAM systems can create more stable maps and achieve more reliable localization in real-world scenarios with moving objects and changing conditions.Expand Specific Solutions
Leading Companies in Edge AI SLAM Development
The SLAM algorithms optimized for Edge AI hardware market is currently in a growth phase, with increasing demand driven by autonomous systems and robotics applications. The market size is expanding rapidly, projected to reach significant value by 2025 due to rising adoption in autonomous vehicles, drones, and mobile robots. Technologically, the field is maturing with companies like Intel, Samsung, and Sony leading commercial implementations, while academic institutions such as Beijing Institute of Technology and University of Electronic Science & Technology of China contribute fundamental research. Cambricon Technologies and MediaTek are advancing specialized Edge AI chips optimized for SLAM workloads. The integration of SLAM with Edge AI is progressing from experimental to production-ready solutions, with increasing focus on power efficiency and real-time processing capabilities.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has developed an edge-optimized SLAM solution called "ExynoSLAM" that runs on their Exynos processors with NPU (Neural Processing Unit) acceleration. Their approach focuses on lightweight visual SLAM algorithms that leverage hardware acceleration for key computational bottlenecks. Samsung's implementation utilizes a hybrid sparse-dense mapping technique that selectively processes visual information based on scene complexity, reducing computational overhead. Their solution incorporates specialized tensor operations for feature extraction and matching that are efficiently executed on their NPU hardware. Samsung has also implemented memory optimization techniques that reduce bandwidth requirements by up to 40% compared to conventional SLAM implementations. Their system dynamically adjusts computational precision based on available resources, enabling deployment across a range of edge devices from smartphones to autonomous robots. Samsung's SLAM technology integrates with their SmartThings ecosystem, enabling spatial awareness for consumer IoT applications.
Strengths: Efficient memory usage optimized for mobile devices; scalable performance across different hardware tiers; integration with broader Samsung ecosystem. Weaknesses: Limited availability outside Samsung hardware ecosystem; less robust in feature-poor environments; requires specific Exynos processors for optimal performance.
Cambricon Technologies Corp. Ltd.
Technical Solution: Cambricon has developed specialized neural processing hardware and accompanying SLAM algorithms optimized for edge AI deployment. Their MLU (Machine Learning Unit) series of processors feature dedicated tensor acceleration units that significantly speed up the feature extraction and matching operations critical to SLAM performance. Cambricon's approach focuses on neural-enhanced SLAM that incorporates deep learning for improved feature detection and scene understanding while maintaining edge deployment capabilities. Their solution implements a novel quantization scheme that reduces computational precision requirements while preserving mapping accuracy, achieving up to 3x performance improvement over floating-point implementations. Cambricon's edge SLAM technology incorporates specialized instruction sets for common SLAM operations like pose estimation and bundle adjustment, enabling efficient execution on their hardware. Their system supports dynamic workload balancing between CPU, GPU, and MLU components based on the specific requirements of different SLAM stages, optimizing both performance and power consumption.
Strengths: Purpose-built hardware acceleration for AI-enhanced SLAM; excellent performance-per-watt metrics; advanced quantization techniques preserve accuracy. Weaknesses: Limited deployment outside of Chinese market; requires specialized development knowledge; less mature ecosystem compared to larger competitors.
Key Technical Innovations in Lightweight SLAM Algorithms
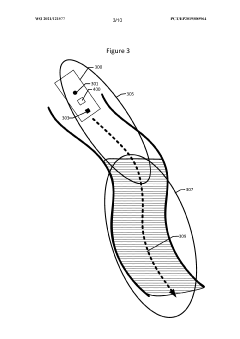
Method and apparatus for accelerating simultaneous localization and mapping
PatentPendingUS20220358262A1
Innovation
- The proposed solution involves an apparatus and method that selectively computes and accumulates elements of an optimization matrix without generating the entire Hessian matrix, using a pipeline structure to perform optimization operations sequentially, and employing Schur-complement operations to reduce the computational burden, allowing for high-speed and low-power processing of SLAM tasks.
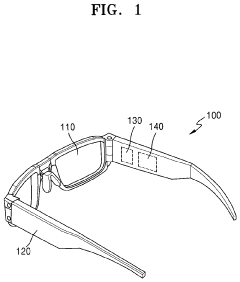
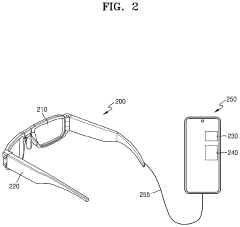
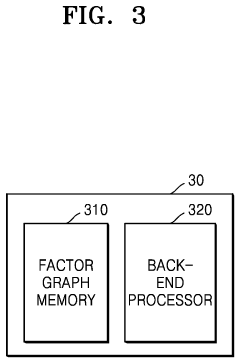
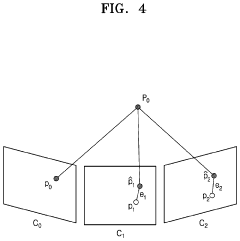
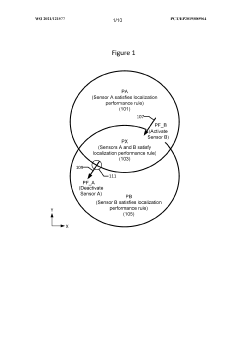
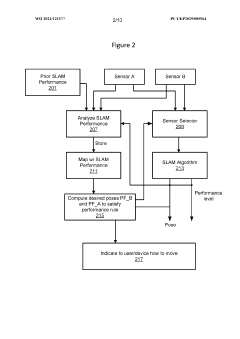
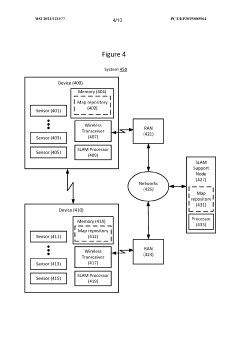
Localization using sensors that are tranportable with a device
PatentWO2021121577A1
Innovation
- A device and method that dynamically activate and deactivate sensors based on specific pose conditions to ensure optimal sensor usage, switching between sensors to maintain localization performance while reducing power consumption and resource utilization.
Power Efficiency Considerations for Edge SLAM Deployment
Power efficiency represents a critical constraint for deploying SLAM algorithms on edge devices, where battery life and thermal management are paramount concerns. Edge SLAM implementations must balance computational requirements with energy consumption to ensure practical deployment in resource-constrained environments such as mobile robots, drones, and AR/VR headsets. Current edge AI hardware typically operates within 1-5W power envelopes, significantly limiting the computational resources available for SLAM operations.
The power consumption profile of SLAM algorithms varies considerably across different processing stages. Feature extraction and matching operations, particularly when using deep learning-based methods, consume disproportionate energy compared to other components. Research indicates that optimizing these high-consumption stages through algorithm-hardware co-design can reduce overall power requirements by 30-45% without significant accuracy degradation.
Dynamic power management strategies have emerged as essential techniques for edge SLAM deployment. These approaches include adaptive feature extraction that scales computational complexity based on scene complexity and motion dynamics. Implementations that dynamically adjust processing frequency and precision based on real-time requirements have demonstrated power savings of up to 60% during periods of low motion or simplified environments.
Hardware-specific optimizations represent another critical dimension for power-efficient SLAM. Leveraging specialized hardware accelerators such as visual processing units (VPUs) and neural processing units (NPUs) can significantly reduce energy consumption for specific SLAM components. Intel's Movidius VPU and Google's Edge TPU have demonstrated 5-10x improvements in performance-per-watt for visual feature extraction compared to general-purpose processors.
Memory access patterns substantially impact power consumption in edge SLAM implementations. Optimizing data locality and minimizing off-chip memory transfers can reduce power requirements by 15-25%. Techniques such as loop fusion, data quantization, and sparse computation have proven effective in minimizing memory-related power consumption while maintaining acceptable accuracy levels.
Recent research has explored approximate computing techniques for SLAM, deliberately trading minimal accuracy for substantial power savings. Selective precision reduction in floating-point operations, early termination of iterative algorithms, and feature pruning strategies have demonstrated power reductions of 20-40% with accuracy degradation below 5%, an acceptable trade-off for many applications where absolute precision is less critical than operational longevity.
The power consumption profile of SLAM algorithms varies considerably across different processing stages. Feature extraction and matching operations, particularly when using deep learning-based methods, consume disproportionate energy compared to other components. Research indicates that optimizing these high-consumption stages through algorithm-hardware co-design can reduce overall power requirements by 30-45% without significant accuracy degradation.
Dynamic power management strategies have emerged as essential techniques for edge SLAM deployment. These approaches include adaptive feature extraction that scales computational complexity based on scene complexity and motion dynamics. Implementations that dynamically adjust processing frequency and precision based on real-time requirements have demonstrated power savings of up to 60% during periods of low motion or simplified environments.
Hardware-specific optimizations represent another critical dimension for power-efficient SLAM. Leveraging specialized hardware accelerators such as visual processing units (VPUs) and neural processing units (NPUs) can significantly reduce energy consumption for specific SLAM components. Intel's Movidius VPU and Google's Edge TPU have demonstrated 5-10x improvements in performance-per-watt for visual feature extraction compared to general-purpose processors.
Memory access patterns substantially impact power consumption in edge SLAM implementations. Optimizing data locality and minimizing off-chip memory transfers can reduce power requirements by 15-25%. Techniques such as loop fusion, data quantization, and sparse computation have proven effective in minimizing memory-related power consumption while maintaining acceptable accuracy levels.
Recent research has explored approximate computing techniques for SLAM, deliberately trading minimal accuracy for substantial power savings. Selective precision reduction in floating-point operations, early termination of iterative algorithms, and feature pruning strategies have demonstrated power reductions of 20-40% with accuracy degradation below 5%, an acceptable trade-off for many applications where absolute precision is less critical than operational longevity.
Real-time Performance Benchmarking Methodologies
Benchmarking the real-time performance of SLAM algorithms on edge AI hardware requires specialized methodologies that account for the unique constraints of resource-limited devices. Traditional benchmarking approaches often fail to capture the nuanced performance characteristics relevant to edge deployment scenarios, necessitating more targeted evaluation frameworks.
A comprehensive benchmarking methodology must first establish clear metrics that reflect real-world operational requirements. These typically include processing latency (frame-to-pose delay), throughput (frames processed per second), mapping accuracy, localization drift, and power consumption. For edge AI applications, the energy efficiency metric (accuracy per watt) becomes particularly critical as it directly impacts device battery life and thermal management.
Test environments should incorporate standardized datasets that represent diverse operational conditions. The EuRoC MAV, KITTI, and TUM RGB-D datasets provide established benchmarks, but edge-specific datasets that feature challenging lighting conditions, rapid motion, and resource constraints are increasingly valuable. Custom datasets that simulate intended deployment environments often yield more relevant performance insights than generic benchmarks.
Hardware-aware profiling tools must be employed to identify computational bottlenecks specific to edge processors. Tools like ARM Streamline, Intel VTune, and NVIDIA Nsight provide detailed execution traces that reveal memory access patterns, cache utilization, and processor load distribution. These insights enable algorithm optimization tailored to specific edge hardware architectures.
Workload characterization should distinguish between initialization, tracking, and mapping phases, as each places different demands on the hardware. The initialization phase often requires significant computational resources but occurs infrequently, while tracking must maintain consistent real-time performance. Understanding these workload patterns helps in developing adaptive resource allocation strategies for edge devices.
Comparative analysis should include both quantitative metrics and qualitative assessments of robustness. Algorithm stability under varying conditions, recovery capabilities after tracking failures, and graceful degradation under resource constraints are essential qualities that pure numerical benchmarks may not capture. A scoring system that weights these factors according to application requirements provides a more holistic evaluation.
Finally, reproducibility protocols must be established to ensure benchmark results can be verified across different implementations and hardware configurations. This includes detailed documentation of parameter settings, preprocessing steps, and environmental conditions that might influence performance outcomes.
A comprehensive benchmarking methodology must first establish clear metrics that reflect real-world operational requirements. These typically include processing latency (frame-to-pose delay), throughput (frames processed per second), mapping accuracy, localization drift, and power consumption. For edge AI applications, the energy efficiency metric (accuracy per watt) becomes particularly critical as it directly impacts device battery life and thermal management.
Test environments should incorporate standardized datasets that represent diverse operational conditions. The EuRoC MAV, KITTI, and TUM RGB-D datasets provide established benchmarks, but edge-specific datasets that feature challenging lighting conditions, rapid motion, and resource constraints are increasingly valuable. Custom datasets that simulate intended deployment environments often yield more relevant performance insights than generic benchmarks.
Hardware-aware profiling tools must be employed to identify computational bottlenecks specific to edge processors. Tools like ARM Streamline, Intel VTune, and NVIDIA Nsight provide detailed execution traces that reveal memory access patterns, cache utilization, and processor load distribution. These insights enable algorithm optimization tailored to specific edge hardware architectures.
Workload characterization should distinguish between initialization, tracking, and mapping phases, as each places different demands on the hardware. The initialization phase often requires significant computational resources but occurs infrequently, while tracking must maintain consistent real-time performance. Understanding these workload patterns helps in developing adaptive resource allocation strategies for edge devices.
Comparative analysis should include both quantitative metrics and qualitative assessments of robustness. Algorithm stability under varying conditions, recovery capabilities after tracking failures, and graceful degradation under resource constraints are essential qualities that pure numerical benchmarks may not capture. A scoring system that weights these factors according to application requirements provides a more holistic evaluation.
Finally, reproducibility protocols must be established to ensure benchmark results can be verified across different implementations and hardware configurations. This includes detailed documentation of parameter settings, preprocessing steps, and environmental conditions that might influence performance outcomes.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!