

Webpage metadata automatic extraction method and system based on multi-page comparison
A technology for automatic extraction and metadata, which is used in electrical digital data processing, special data processing applications, instruments, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0114] The specific implementation of the present invention will be described in detail below in conjunction with an example of integrating housing information.
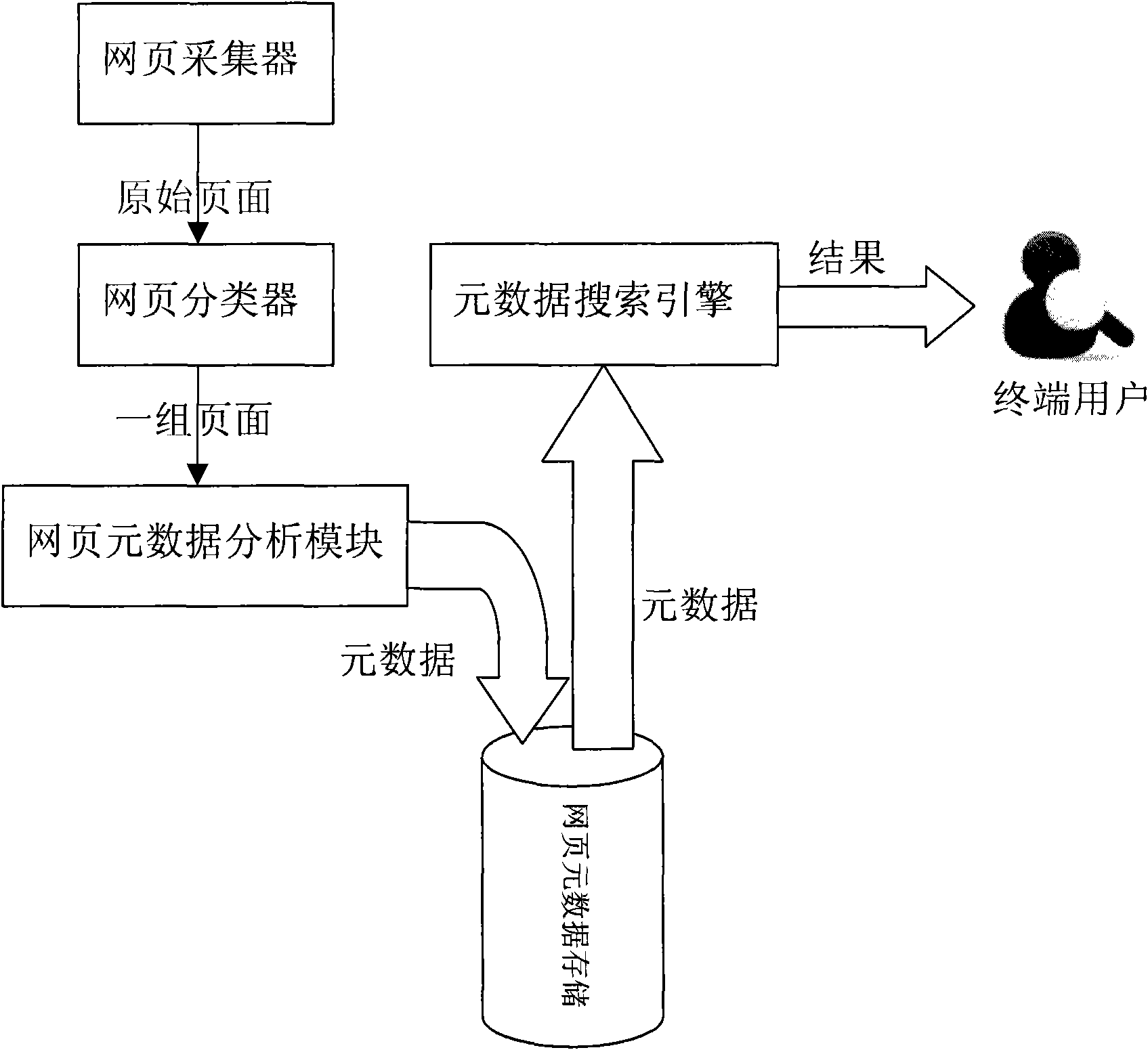
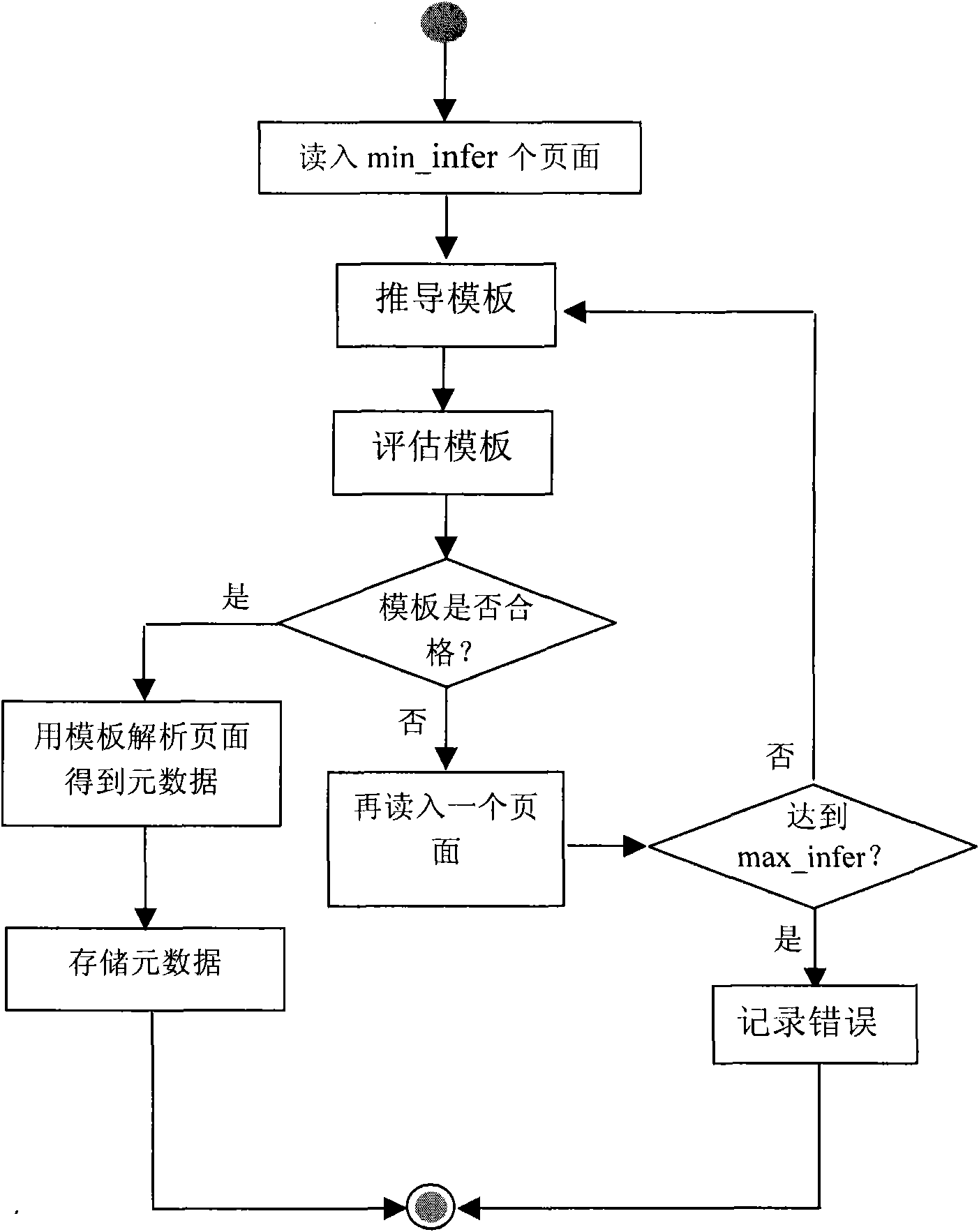
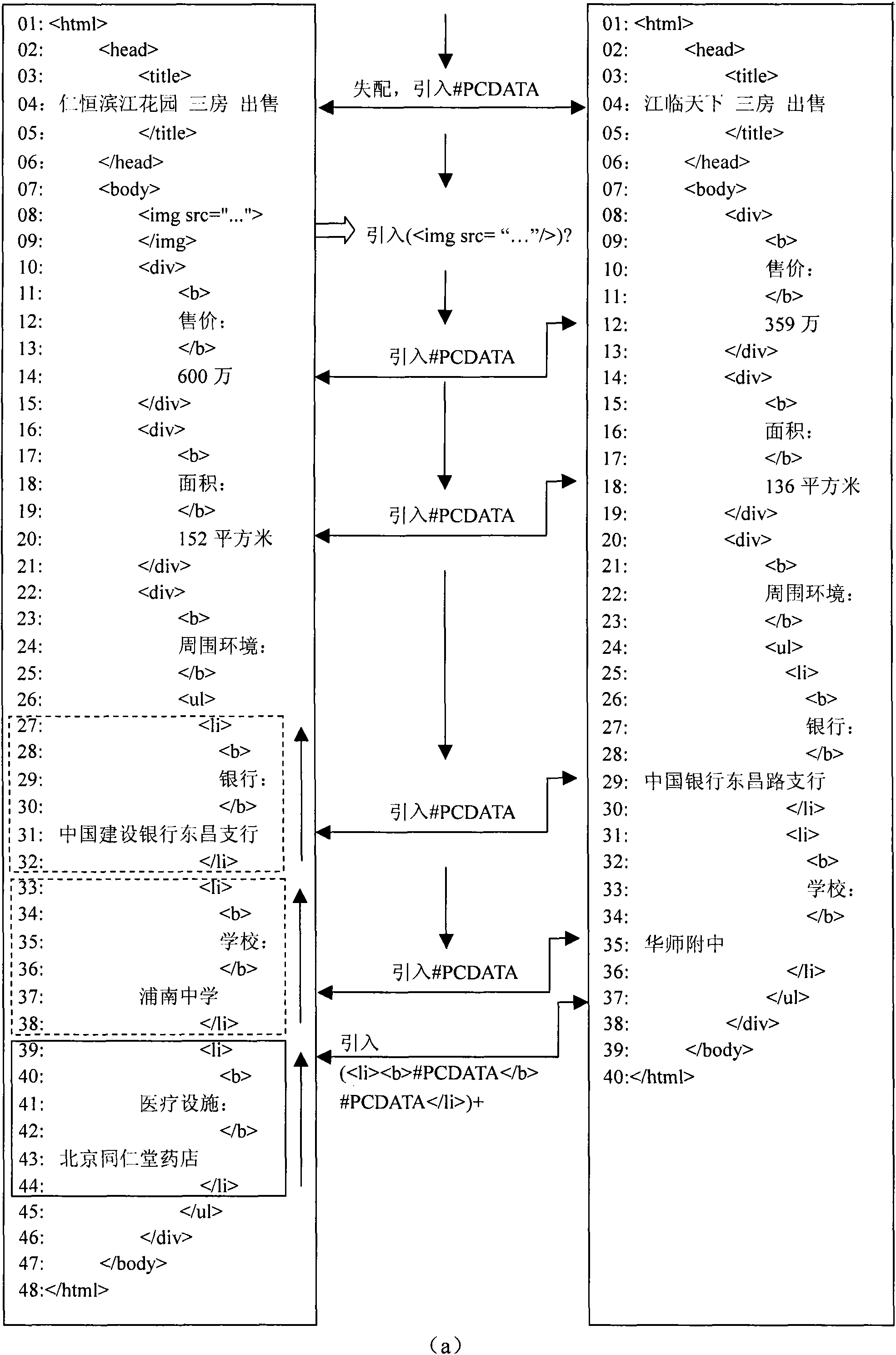
[0115] This specific embodiment describes a method for extracting metadata of house listing pages of real estate websites on the Internet. The goal of the integration of housing information is to provide an integrated platform of housing information for house seekers on the Internet. They only need to search on one website to find housing sources on all websites on the Internet. As an important part of the metadata extraction step, it is necessary to achieve better extraction accuracy for semi-structured web pages and have the ability to process loosely structured documents.
[0116] In this specific embodiment, the extraction of metadata includes the following steps:
[0117] 1. Configure web page collector
[0118] Here you need to define the websites that need to collect web pages, and each website needs to defi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More