

Voice synchronous-drive three-dimensional face mouth shape and face posture animation method
A voice-synchronized driving and facial gesture technology, which is applied in animation production, computer parts, image data processing, etc., can solve problems such as difficult facial gestures and weak correlations, and achieve the effect of reducing intelligibility and recognizability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


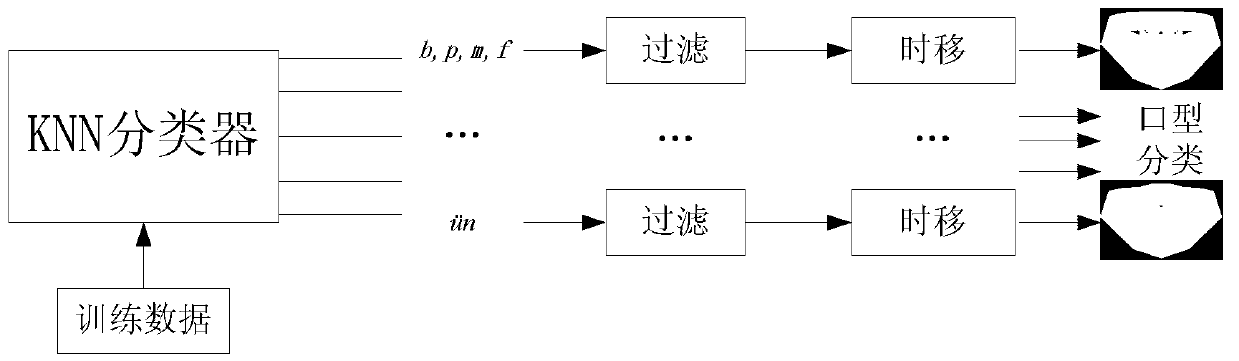
Examples
Embodiment
[0030] The present invention will be further described below in conjunction with accompanying drawing and specific embodiment:
[0031] The specific implementation method of the present invention roughly comprises the following steps:
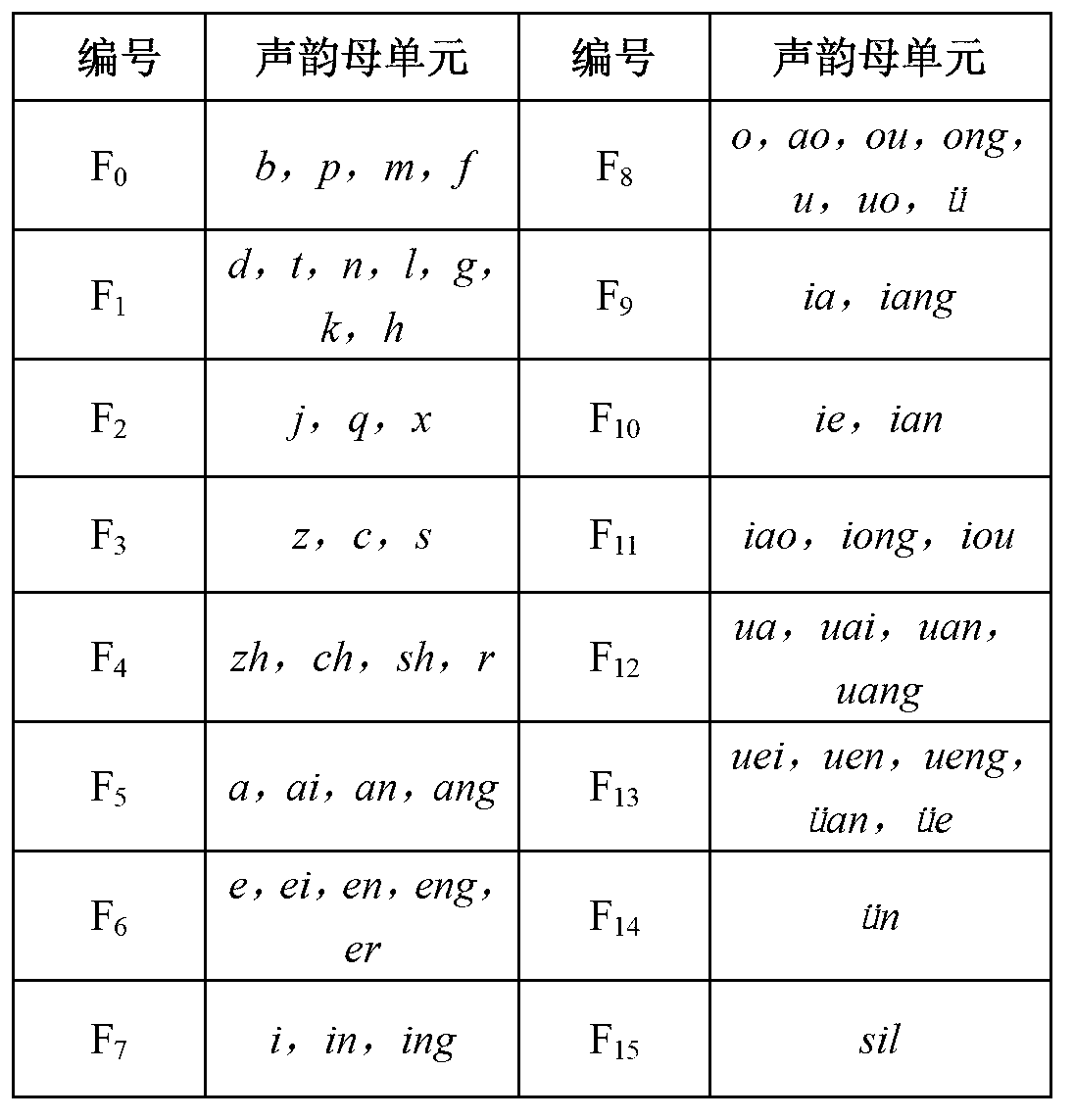
[0032] 1. Viseme classification, because the corresponding mouth-frames of some consonants and finals are similar, in order to reduce the amount of calculation, the present invention carries out viseme classification of some consonants and finals according to their corresponding mouth shapes, which are divided into 16 categories, F 0 -F 15 . Specific categories such as figure 1 shown.
[0033] 2. Create an audio / video corpus and record it with a high-definition video camera. 20 people, 10 men and 10 women, read the classified consonants in step 1, and record audio and video at the same time. When the voice is recorded, facial video information synchronized with the voice is collected. In order to facilitate the retrieval and extraction of ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More