

Webpage information extraction method and system
A technology of webpage information and webpage, which is applied in the field of information extraction, and can solve the problems of no overall awareness of the extraction method, low versatility, and low robustness of the extraction method
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
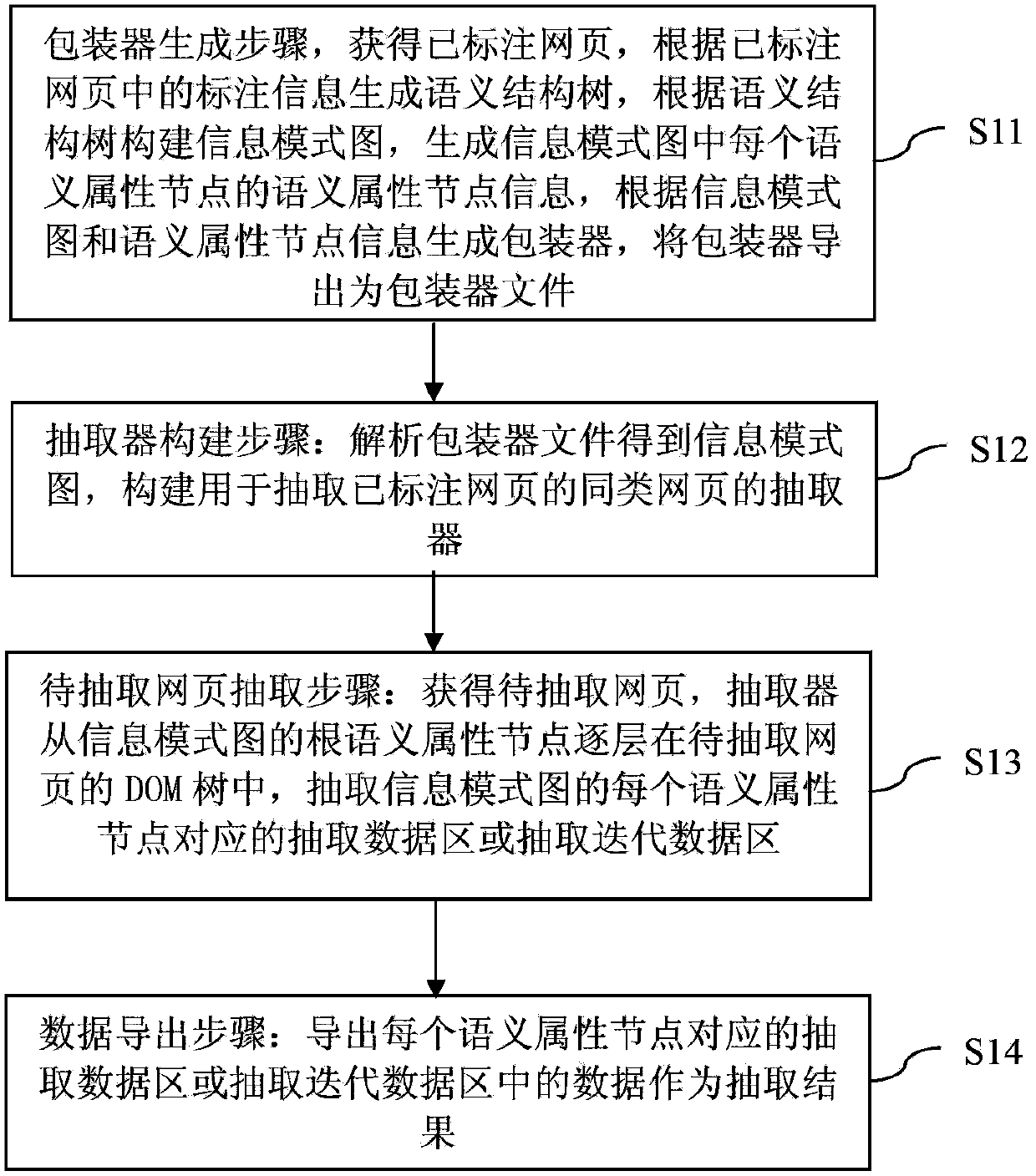
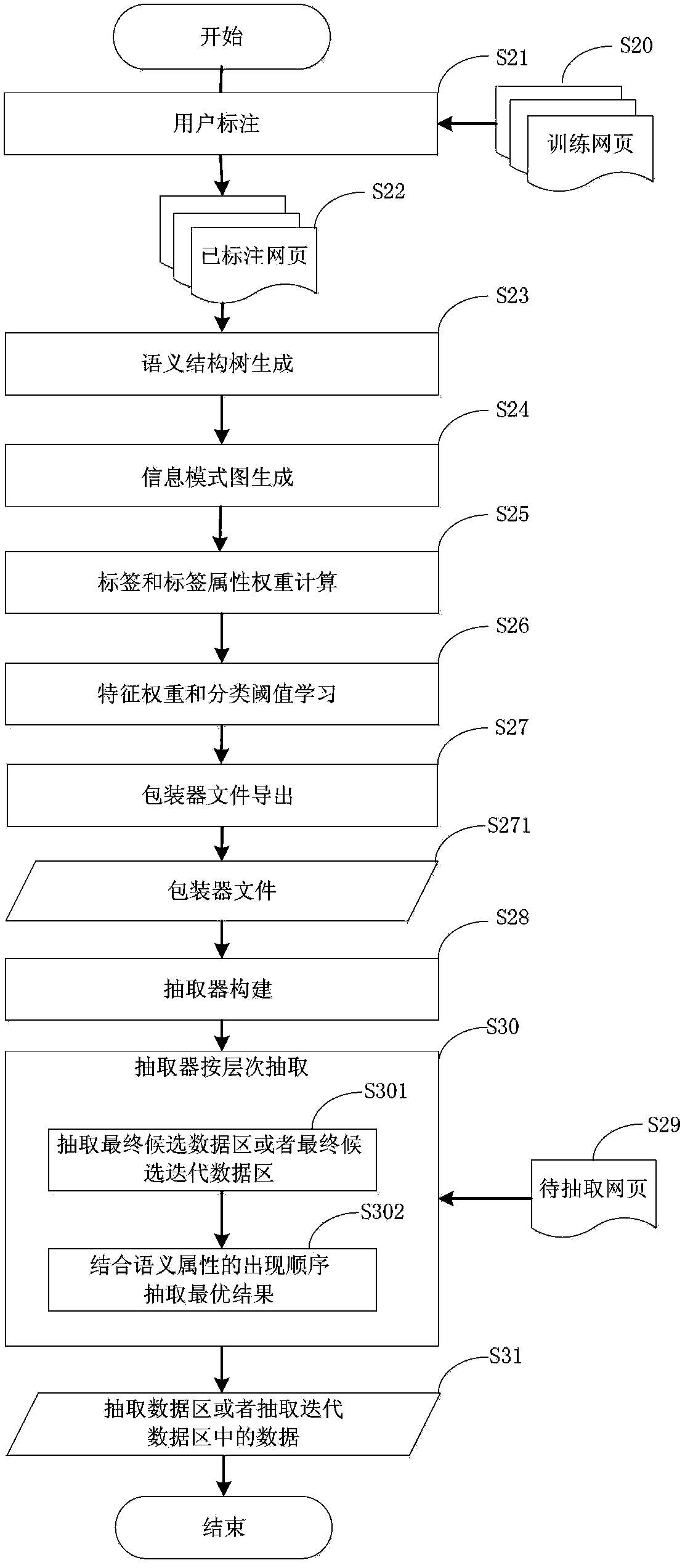
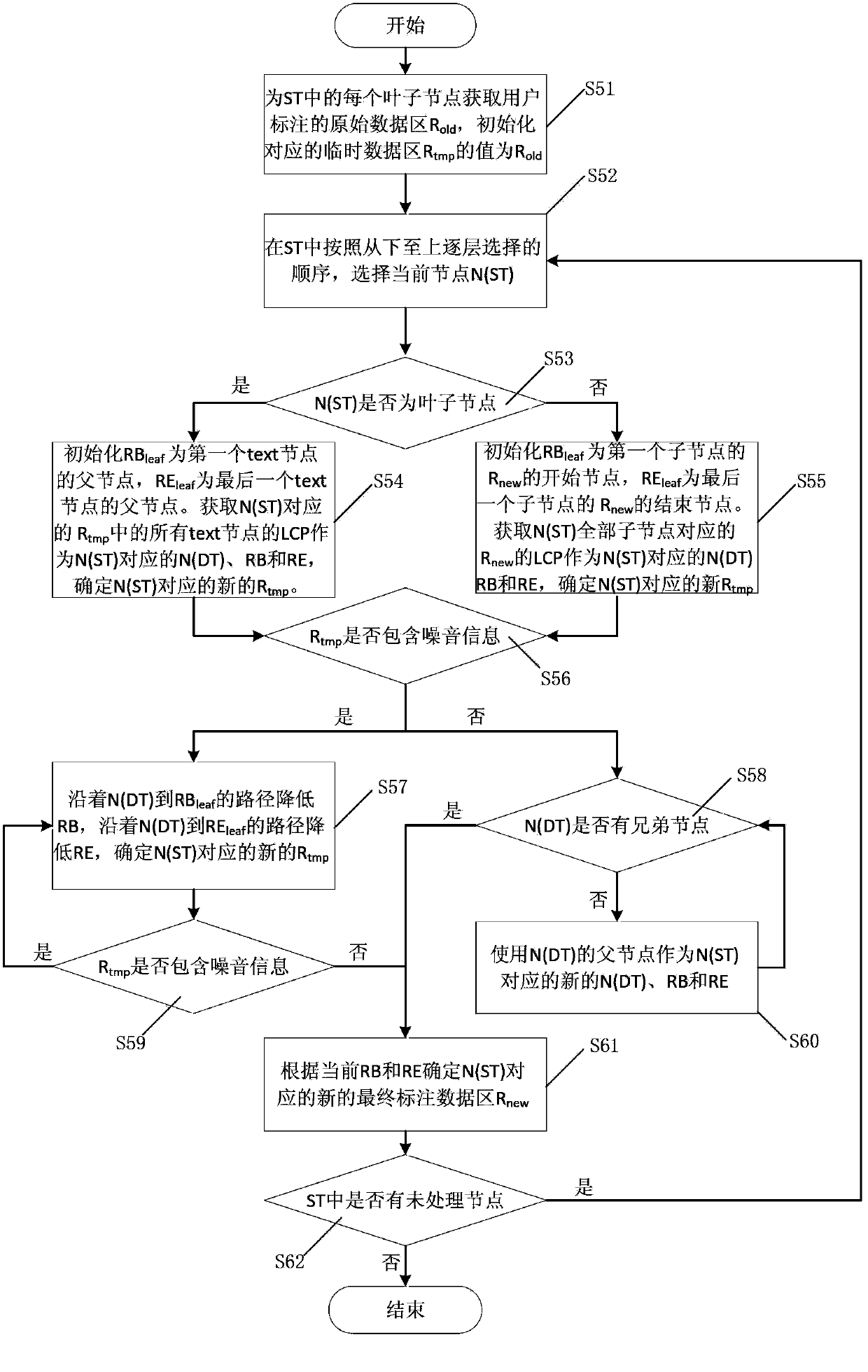
[0072] The technical solutions of the present invention will be described in detail below in conjunction with the embodiments and the accompanying drawings.
[0073] First, the application scenarios and concepts used in the present invention are described.
[0074] The content in a web page is composed of some semantic units, and each semantic unit corresponds to a semantic attribute. The combination of semantic attributes can form a new semantic attribute. The new semantic attribute is called the parent semantic attribute. The semantic attribute directly contained in the parent semantic attribute is Sub-semantic attributes, the sub-semantic attributes under the same parent semantic attribute are sibling semantic attributes. Each specific value of the semantic attribute is a subtree forest in the DOM tree of the web page, and the subtrees in the subtree forest are continuous and non-overlapping, that is, there are no adjacent subtrees in the subtree forest. If there are other...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More