Text-independent speaker identifying device based on line spectrum frequency difference value
A technology of speaker identification and line spectrum frequency, applied in speech analysis, instruments, etc., can solve the problems of inconvenient use, easy to be recorded and falsely identified by the recognition system, and difficult to build a speaker model.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] Specific embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings.
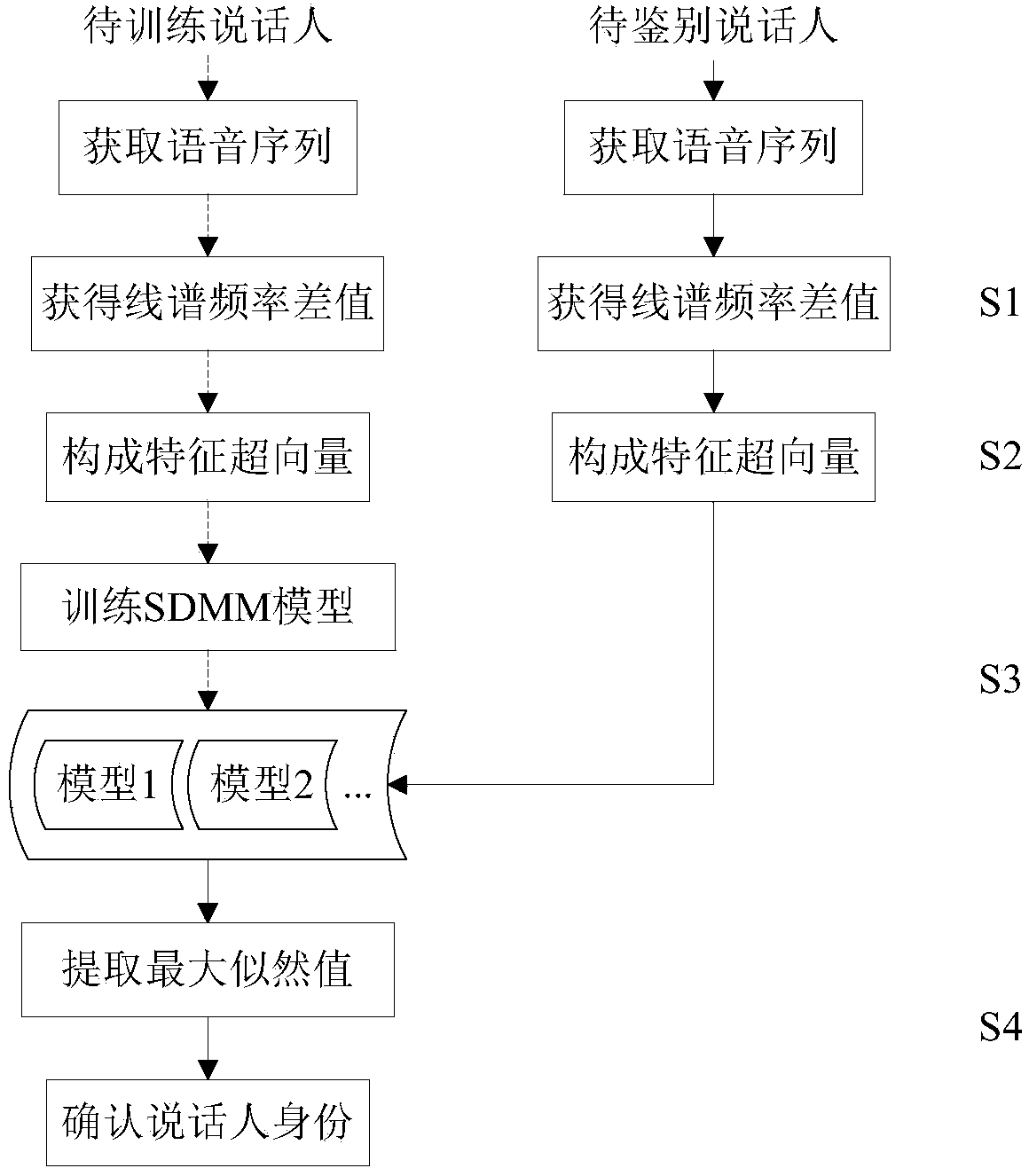
[0034] figure 1 It is a flowchart of the present invention, wherein the dotted line represents the direction of the training part of the process, and the solid line represents the direction of the identification part of the process, including the following steps:
[0035] The first step: feature extraction step, feature extraction of the speaker's voice sequence to be trained
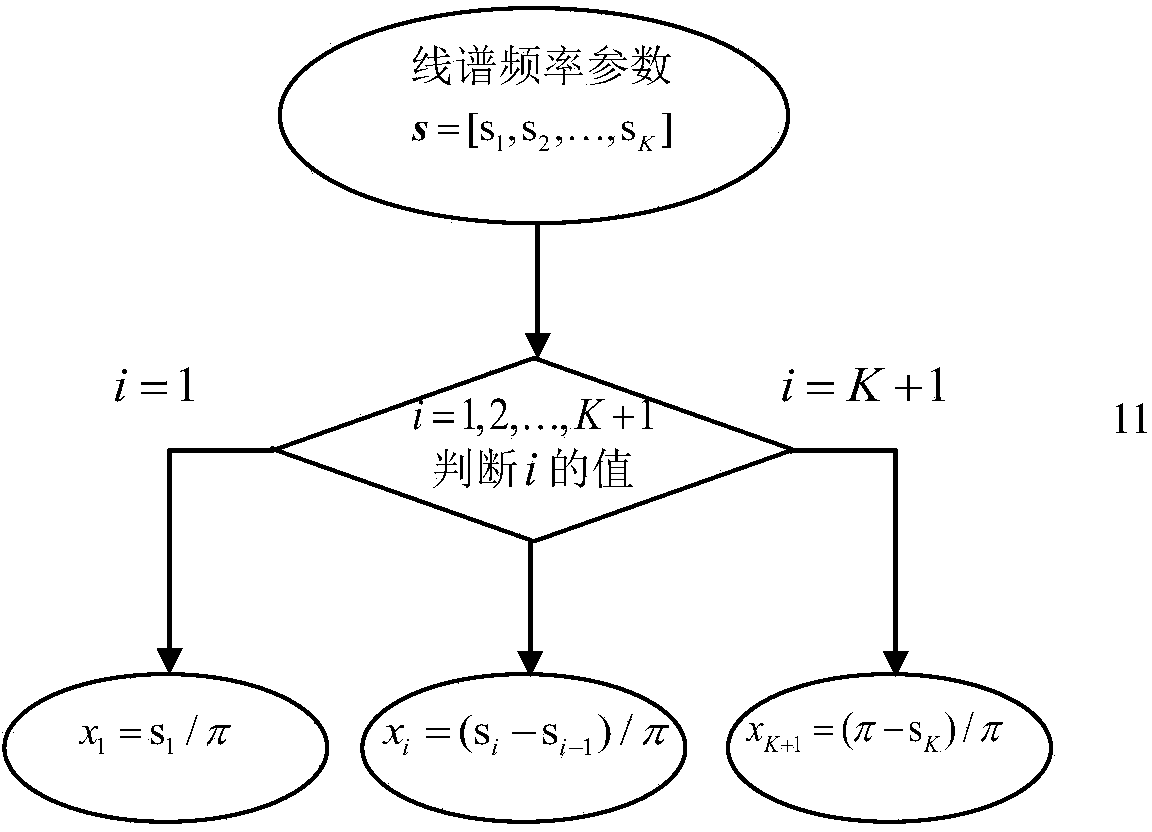
[0036] Step S1: converting the line spectrum frequency parameter into a line spectrum frequency parameter difference;
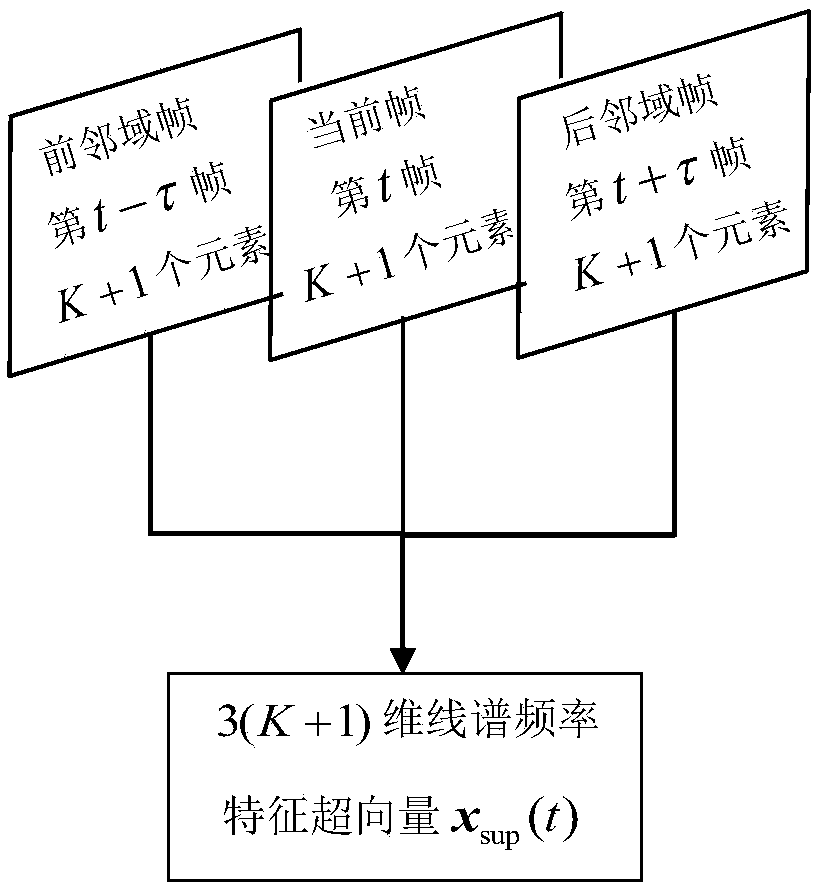
[0037] Step S2: generating a line spectrum frequency feature supervector;
[0038] Step 2: Train the model
[0039] Step S3: use the super-Dirichlet mixture model to simulate the distribution of feature supervectors, and solve the parameters in the model;
[0040] Step Three: Identification Process
[0041] Repeat step S1 and step S2 in the first ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More