

Voice recognition method and voice recognition terminal
A speech recognition and terminal technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of high cost and large amount of data, and achieve the effect of reducing input cost, reducing data to be processed, and reducing the amount of dialect information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
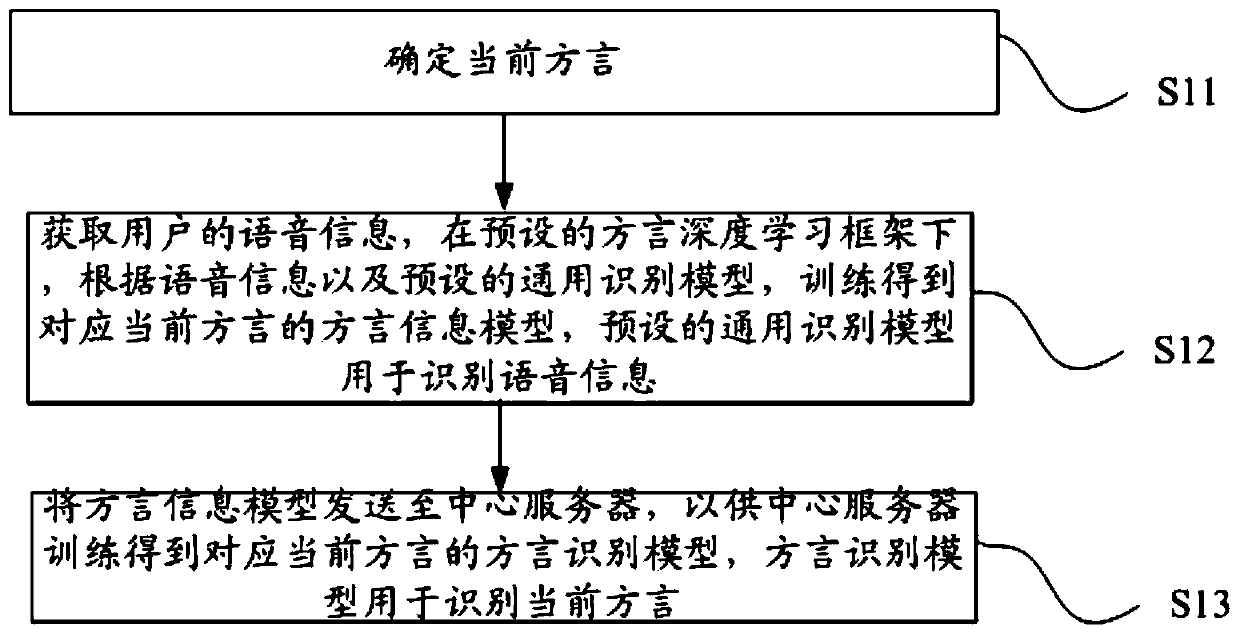
[0027] Such as figure 1 As shown, this embodiment provides a method for speech recognition, a terminal based on speech recognition, the method includes:
[0028] S11. Determine the current dialect.
[0029] Wherein, that is to say, determine the dialect type of the current location, for example, if the terminal is in Guangdong province, the dialect type is Cantonese, and if the terminal is in Zhejiang province, the dialect type is Zhejiang dialect, etc.
[0030] S12. Obtain the voice information of the user, and under the preset dialect deep learning framework, according to the voice information and the preset general recognition model, train the dialect information model corresponding to the current dialect, and the preset general recognition model is used to recognize the voice information .
[0031] Among them, that is to say, the preset general recognition model can recognize voice information (such as Mandarin, etc.), but the preset general recognition model is not very...
Embodiment 2
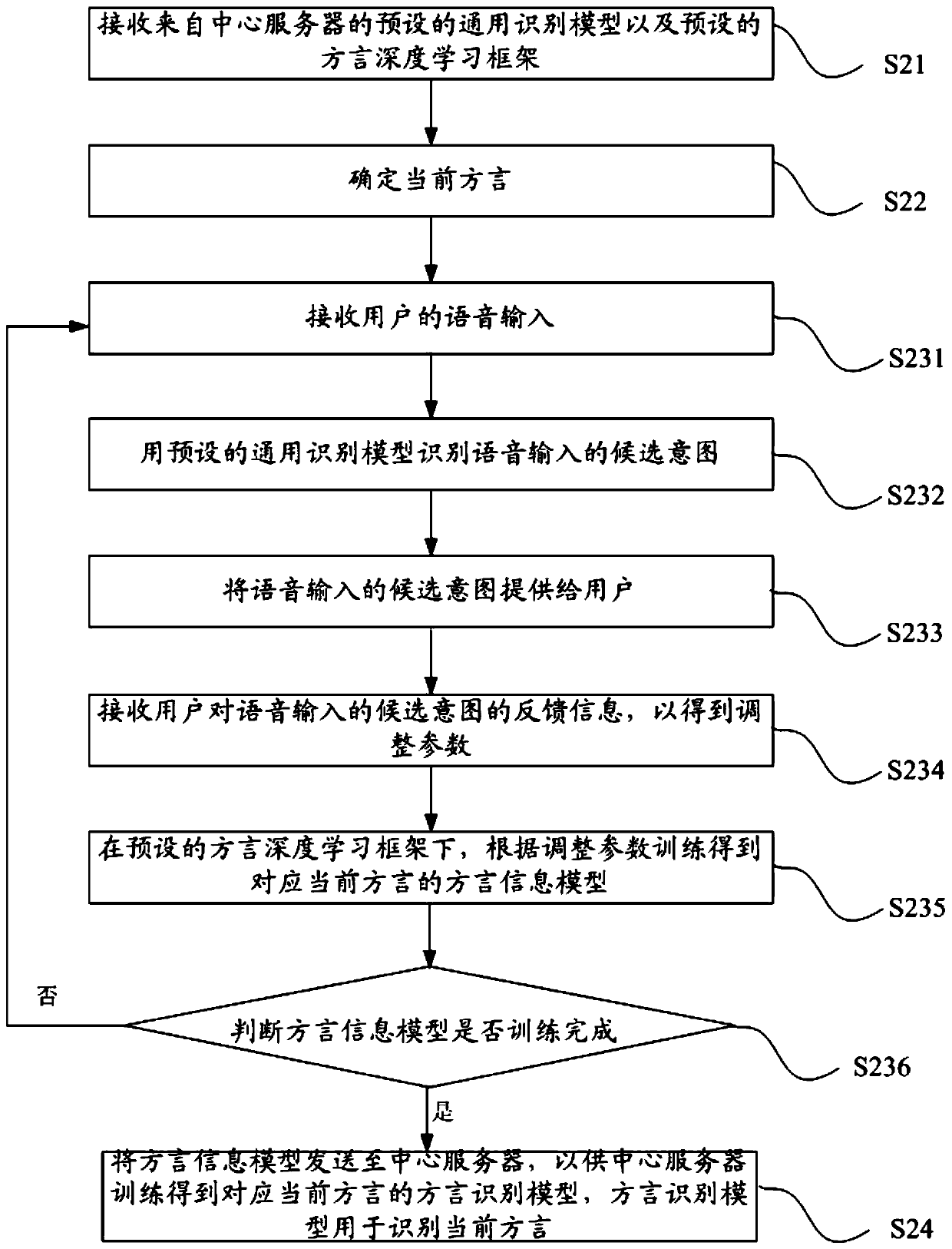
[0038] Such as figure 2 As shown, this embodiment provides a method for speech recognition, a terminal based on speech recognition, the method includes:
[0039] S21. Receive a preset universal recognition model and a preset dialect deep learning framework from the central server.
[0040] For example, the terminal can download related software from the central server, and the software includes a preset general recognition model and a preset dialect deep learning framework. Specifically, the preset general recognition model can recognize speech information (such as Mandarin, etc.), but the preset general recognition model is not very accurate for the recognition of specific dialect speech information
[0041] S22. Determine the current dialect.
[0042] Wherein, that is to say, determine the dialect type of the current location, for example, if the terminal is in Guangdong province, the dialect type is Cantonese, and if the terminal is in Zhejiang province, the dialect type...
Embodiment 3
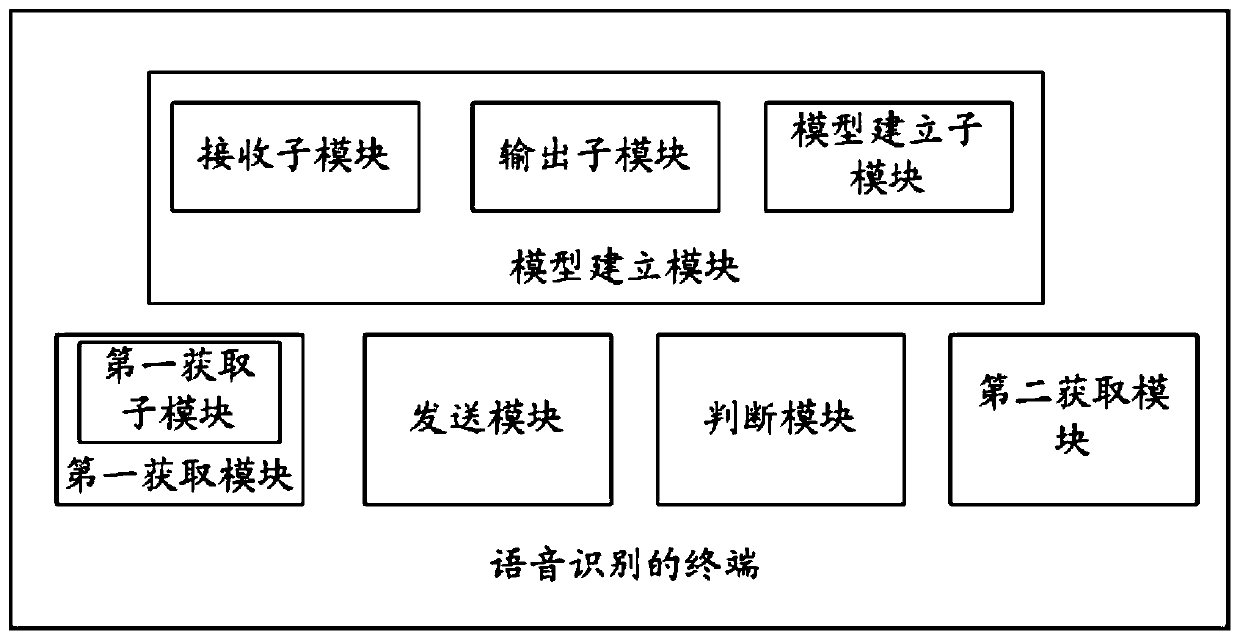
[0066] Such as image 3 As shown, this embodiment provides a speech recognition terminal, including:
[0067] The first acquisition module is used to determine the current dialect;
[0068] The model building module is used to obtain the voice information of the user. Under the preset dialect deep learning framework, according to the voice information and the preset general recognition model, the dialect information model corresponding to the current dialect is obtained through training. The preset general recognition model is used to for recognizing voice information.
[0069] The sending module is used to send the dialect information model to the central server, so that the central server can train to obtain a dialect recognition model corresponding to the current dialect, and the dialect recognition model is used to recognize the current dialect.
[0070] Preferably, the model building module includes:
[0071] The receiving sub-module is used to receive the user's voice...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More