

Voice cloning method and device based on single-speaker speech synthesis data set
A speech synthesis and speech data technology, applied in speech synthesis, speech analysis, speech recognition, etc., can solve the problems of high cost, high cost, and inability to label speech synthesis data sets.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
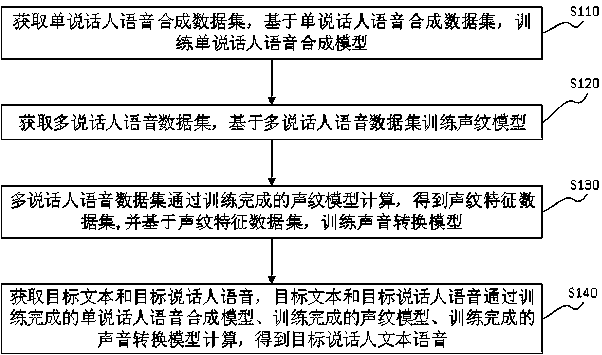
[0046] Embodiment 1 provides a sound cloning method based on a single-speaker speech synthesis data set, aiming at training a single-speaker speech synthesis model through the speaker's speech synthesis data set. Human speech synthesis model, voiceprint model and voice conversion model are calculated, and the voice of the target text can be obtained in the voice of the target speaker. This method only needs a single-speaker speech synthesis data set to clone the voice of the target speaker. The processing of single-speaker speech synthesis data is simple and convenient, without the need to collect and process a large number of speaker speech synthesis data. Greatly reduce manpower, time and capital costs.
[0047] Please refer to figure 1 As shown, a voice cloning method based on a single-speaker speech synthesis dataset, including the following steps:
[0048] S110. Acquire a single-speaker speech synthesis data set, and train a single-speaker speech synthesis model based o...
Embodiment 2
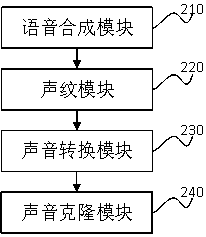
[0071] Embodiment 2 discloses a voice cloning device based on a single-speaker speech synthesis data set corresponding to the above embodiment, which is the virtual device structure of the above embodiment, please refer to figure 2 shown, including:
[0072] The speech synthesis module 210 is used to obtain a single-speaker speech synthesis data set, and train a single-speaker speech synthesis model based on the single-speaker speech synthesis data set;
[0073] The voiceprint module 220 is used to obtain a multi-speaker voice data set, and train a voiceprint model based on the multi-speaker voice data set;
[0074] The voice conversion module 230 is used to calculate the voiceprint model through the training of the multi-speaker voice data set to obtain a voiceprint feature data set, and train the voice conversion model based on the voiceprint feature data set;
[0075] The sound cloning module 240 is used to obtain the target text and the target speaker's voice, the target...
Embodiment 3
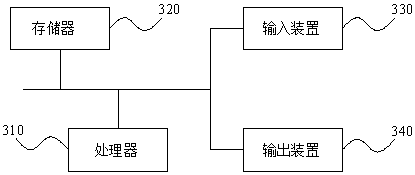
[0078] image 3 A schematic structural diagram of an electronic device provided in Embodiment 3 of the present invention, such as image 3 As shown, the electronic device includes a processor 310, a memory 320, an input device 330, and an output device 340; the number of processors 310 in a computer device may be one or more, image 3 Take a processor 310 as an example; the processor 310, memory 320, input device 330 and output device 340 in the electronic device can be connected by bus or other methods, image 3 Take connection via bus as an example.
[0079] The memory 320, as a computer-readable storage medium, can be used to store software programs, computer-executable programs and modules, such as the program instructions / modules corresponding to the voice cloning method based on the single-speaker speech synthesis data set in the embodiment of the present invention ( For example, the voice synthesis module 210, the voiceprint module 220, the voice conversion module 230...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More