Single-channel speech enhancement method based on joint dictionary learning and sparse representation
A sparse representation, speech enhancement technology, applied in speech analysis, complex mathematical operations, instruments, etc., can solve the performance limitations of speech enhancement, rarely use phase information and other problems, to increase the time-frequency representation ability, reduce estimation error, quality boosted effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


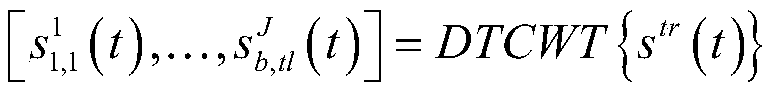
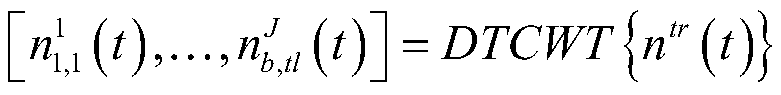
Examples
Embodiment Construction
[0012] The technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some of the embodiments of the present invention, not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
[0013] Different from most of the existing single-channel speech enhancement algorithms, the embodiment of the present invention provides a single-channel speech enhancement method based on joint dictionary learning and sparse representation. This method first decomposes the single-channel signal into a group of sub-signals, and increases the signal Representation ability; secondly, make full use of the amplitude, real part and imaginary part inform...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More