

How HBM4 Improves Bandwidth Utilization In GPU Architectures?
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
PatSnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Evolution and GPU Performance Objectives
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation bringing substantial improvements in bandwidth, capacity, and energy efficiency. The evolution from HBM1 to HBM4 represents a critical advancement in addressing the growing computational demands of modern GPU architectures. HBM4, as the latest iteration, aims to overcome the memory bandwidth bottlenecks that have increasingly constrained GPU performance in data-intensive applications such as AI training, scientific computing, and high-performance graphics rendering.
The historical trajectory of HBM development shows a consistent pattern of innovation focused on increasing bandwidth density while reducing power consumption. HBM1, introduced in 2013, offered a significant leap over GDDR5 with its stacked die architecture. HBM2 doubled the bandwidth per pin, while HBM2E further extended these capabilities. HBM3, released in 2021, pushed bandwidth to unprecedented levels, exceeding 5 TB/s in some implementations. HBM4 continues this progression with projected bandwidth improvements of 33-50% over HBM3, potentially reaching 8-9 TB/s in high-end configurations.
The primary objective driving HBM4 development is to address the widening gap between computational capabilities and memory bandwidth in modern GPU architectures. As GPU core counts and computational throughput have increased exponentially following Moore's Law, memory bandwidth has struggled to keep pace, creating what is commonly referred to as the "memory wall." This disparity has become particularly problematic as AI models grow in size and complexity, requiring massive data transfers between memory and processing units.
HBM4 aims to improve bandwidth utilization through several key technical innovations. First, it increases the number of channels and bandwidth per pin, enabling more parallel data transfers. Second, it implements advanced prefetching algorithms that can more accurately predict data access patterns in GPU workloads. Third, it introduces dynamic channel management that can allocate bandwidth resources based on real-time application needs, reducing idle time and improving overall utilization efficiency.
From a performance perspective, HBM4's objectives include not only raw bandwidth improvements but also reductions in latency and more efficient power management. These enhancements are particularly critical for emerging GPU applications in real-time AI inference, where response time is as important as throughput. The technology also aims to support larger memory capacities per stack, addressing the growing memory requirements of large language models and other data-intensive applications.
The evolution of HBM technology reflects a broader trend in computing architecture toward specialized memory solutions optimized for specific workload characteristics. As GPUs continue to diversify in their application domains, HBM4 represents a crucial enabling technology that will help define the performance envelope of next-generation GPU architectures across gaming, professional visualization, AI training and inference, and scientific computing applications.
The historical trajectory of HBM development shows a consistent pattern of innovation focused on increasing bandwidth density while reducing power consumption. HBM1, introduced in 2013, offered a significant leap over GDDR5 with its stacked die architecture. HBM2 doubled the bandwidth per pin, while HBM2E further extended these capabilities. HBM3, released in 2021, pushed bandwidth to unprecedented levels, exceeding 5 TB/s in some implementations. HBM4 continues this progression with projected bandwidth improvements of 33-50% over HBM3, potentially reaching 8-9 TB/s in high-end configurations.
The primary objective driving HBM4 development is to address the widening gap between computational capabilities and memory bandwidth in modern GPU architectures. As GPU core counts and computational throughput have increased exponentially following Moore's Law, memory bandwidth has struggled to keep pace, creating what is commonly referred to as the "memory wall." This disparity has become particularly problematic as AI models grow in size and complexity, requiring massive data transfers between memory and processing units.
HBM4 aims to improve bandwidth utilization through several key technical innovations. First, it increases the number of channels and bandwidth per pin, enabling more parallel data transfers. Second, it implements advanced prefetching algorithms that can more accurately predict data access patterns in GPU workloads. Third, it introduces dynamic channel management that can allocate bandwidth resources based on real-time application needs, reducing idle time and improving overall utilization efficiency.
From a performance perspective, HBM4's objectives include not only raw bandwidth improvements but also reductions in latency and more efficient power management. These enhancements are particularly critical for emerging GPU applications in real-time AI inference, where response time is as important as throughput. The technology also aims to support larger memory capacities per stack, addressing the growing memory requirements of large language models and other data-intensive applications.
The evolution of HBM technology reflects a broader trend in computing architecture toward specialized memory solutions optimized for specific workload characteristics. As GPUs continue to diversify in their application domains, HBM4 represents a crucial enabling technology that will help define the performance envelope of next-generation GPU architectures across gaming, professional visualization, AI training and inference, and scientific computing applications.
Market Demand for Enhanced GPU Memory Bandwidth
The demand for enhanced GPU memory bandwidth has experienced exponential growth in recent years, primarily driven by the rapid advancement of artificial intelligence, machine learning, and high-performance computing applications. These compute-intensive workloads require massive parallel processing capabilities and increasingly larger datasets, pushing current memory architectures to their limits.
Data-intensive applications such as deep learning training and inference, scientific simulations, and real-time analytics have created unprecedented memory bandwidth requirements. According to industry reports, AI model sizes have been doubling approximately every 3.5 months, significantly outpacing Moore's Law. This growth trajectory has created a critical bottleneck in GPU architectures where memory bandwidth cannot keep pace with computational capabilities.
The market for high-bandwidth memory solutions is projected to grow substantially, with the HBM segment expected to reach significant market value by 2028. This growth reflects the urgent need across multiple industries for memory solutions that can support increasingly complex computational tasks without becoming the performance bottleneck.
Cloud service providers represent a major market segment driving demand for enhanced GPU memory bandwidth. As these providers scale their AI and machine learning offerings, they require GPUs capable of handling larger models and datasets while maintaining energy efficiency. The competitive landscape among cloud providers has accelerated the need for cutting-edge memory solutions that can deliver performance advantages.
Enterprise customers implementing on-premises AI infrastructure constitute another significant market segment. These organizations require high-bandwidth memory solutions to process proprietary datasets efficiently while meeting strict performance requirements. The financial services sector, in particular, has shown strong demand for enhanced memory bandwidth to support real-time risk analysis and algorithmic trading applications.
Research institutions and supercomputing centers form a specialized but influential market segment. These entities often work at the cutting edge of computational science and require the absolute highest memory bandwidth available to advance their research objectives in fields ranging from climate modeling to pharmaceutical development.
The gaming and professional visualization markets also contribute to demand, though to a lesser extent than AI applications. Next-generation gaming experiences and professional rendering workflows benefit from increased memory bandwidth, particularly as resolution and complexity standards continue to rise.
Energy efficiency has emerged as a critical market requirement alongside raw performance metrics. Data centers face increasing pressure to optimize power consumption, making memory solutions that deliver higher bandwidth per watt increasingly valuable in the marketplace.
Data-intensive applications such as deep learning training and inference, scientific simulations, and real-time analytics have created unprecedented memory bandwidth requirements. According to industry reports, AI model sizes have been doubling approximately every 3.5 months, significantly outpacing Moore's Law. This growth trajectory has created a critical bottleneck in GPU architectures where memory bandwidth cannot keep pace with computational capabilities.
The market for high-bandwidth memory solutions is projected to grow substantially, with the HBM segment expected to reach significant market value by 2028. This growth reflects the urgent need across multiple industries for memory solutions that can support increasingly complex computational tasks without becoming the performance bottleneck.
Cloud service providers represent a major market segment driving demand for enhanced GPU memory bandwidth. As these providers scale their AI and machine learning offerings, they require GPUs capable of handling larger models and datasets while maintaining energy efficiency. The competitive landscape among cloud providers has accelerated the need for cutting-edge memory solutions that can deliver performance advantages.
Enterprise customers implementing on-premises AI infrastructure constitute another significant market segment. These organizations require high-bandwidth memory solutions to process proprietary datasets efficiently while meeting strict performance requirements. The financial services sector, in particular, has shown strong demand for enhanced memory bandwidth to support real-time risk analysis and algorithmic trading applications.
Research institutions and supercomputing centers form a specialized but influential market segment. These entities often work at the cutting edge of computational science and require the absolute highest memory bandwidth available to advance their research objectives in fields ranging from climate modeling to pharmaceutical development.
The gaming and professional visualization markets also contribute to demand, though to a lesser extent than AI applications. Next-generation gaming experiences and professional rendering workflows benefit from increased memory bandwidth, particularly as resolution and complexity standards continue to rise.
Energy efficiency has emerged as a critical market requirement alongside raw performance metrics. Data centers face increasing pressure to optimize power consumption, making memory solutions that deliver higher bandwidth per watt increasingly valuable in the marketplace.
Current HBM Technology Limitations in GPU Architectures
Current HBM (High Bandwidth Memory) technology, while revolutionary for GPU architectures, faces several significant limitations that constrain optimal bandwidth utilization. The primary challenge lies in the memory bandwidth wall, where despite theoretical peak bandwidths of up to 2TB/s in HBM3, actual application performance often achieves only 60-70% of this potential due to inefficient memory access patterns and controller limitations.
Memory access granularity presents another critical bottleneck. Current HBM3 implementations operate with fixed transaction sizes, typically 32 or 64 bytes, which creates inefficiencies when applications require smaller data accesses. This mismatch forces GPUs to fetch unnecessary data, wasting bandwidth and increasing power consumption, particularly problematic in AI workloads with sparse matrix operations.
Power efficiency remains a persistent concern with current HBM technology. HBM3's increased bandwidth comes at the cost of significantly higher power consumption—approximately 11-15W per stack—creating thermal management challenges in densely packed GPU architectures and limiting deployment in power-constrained environments.
Latency issues further compound these limitations. Despite high bandwidth, current HBM implementations still exhibit relatively high access latencies (approximately 100-120ns), creating performance bottlenecks for latency-sensitive applications. This latency becomes particularly problematic in workloads with unpredictable memory access patterns or pointer-chasing operations.
Channel utilization inefficiencies represent another significant limitation. Current HBM designs feature multiple independent channels (typically 8-16), but workloads often cannot evenly distribute memory accesses across these channels. This imbalance results in some channels being oversubscribed while others remain underutilized, reducing effective bandwidth.
Capacity constraints also impact performance, with current HBM3 stacks limited to 24GB per stack. This restriction forces complex workloads to frequently transfer data between GPU memory and system memory, creating additional bandwidth bottlenecks at the PCIe interface level.
Finally, the physical integration challenges of HBM technology—including complex interposer designs, thermal management requirements, and manufacturing yield issues—contribute to higher costs and implementation difficulties. These factors limit widespread adoption and create barriers to scaling GPU architectures to meet growing computational demands in AI, scientific computing, and graphics rendering applications.
Memory access granularity presents another critical bottleneck. Current HBM3 implementations operate with fixed transaction sizes, typically 32 or 64 bytes, which creates inefficiencies when applications require smaller data accesses. This mismatch forces GPUs to fetch unnecessary data, wasting bandwidth and increasing power consumption, particularly problematic in AI workloads with sparse matrix operations.
Power efficiency remains a persistent concern with current HBM technology. HBM3's increased bandwidth comes at the cost of significantly higher power consumption—approximately 11-15W per stack—creating thermal management challenges in densely packed GPU architectures and limiting deployment in power-constrained environments.
Latency issues further compound these limitations. Despite high bandwidth, current HBM implementations still exhibit relatively high access latencies (approximately 100-120ns), creating performance bottlenecks for latency-sensitive applications. This latency becomes particularly problematic in workloads with unpredictable memory access patterns or pointer-chasing operations.
Channel utilization inefficiencies represent another significant limitation. Current HBM designs feature multiple independent channels (typically 8-16), but workloads often cannot evenly distribute memory accesses across these channels. This imbalance results in some channels being oversubscribed while others remain underutilized, reducing effective bandwidth.
Capacity constraints also impact performance, with current HBM3 stacks limited to 24GB per stack. This restriction forces complex workloads to frequently transfer data between GPU memory and system memory, creating additional bandwidth bottlenecks at the PCIe interface level.
Finally, the physical integration challenges of HBM technology—including complex interposer designs, thermal management requirements, and manufacturing yield issues—contribute to higher costs and implementation difficulties. These factors limit widespread adoption and create barriers to scaling GPU architectures to meet growing computational demands in AI, scientific computing, and graphics rendering applications.
HBM4 Implementation Strategies for Bandwidth Optimization
01 HBM4 bandwidth optimization techniques
Various techniques can be implemented to optimize HBM4 bandwidth utilization, including advanced memory controllers, dynamic bandwidth allocation, and traffic shaping algorithms. These approaches help balance memory access patterns, reduce contention, and prioritize critical data transfers, resulting in more efficient use of the available bandwidth. Optimization techniques can significantly improve system performance in high-bandwidth applications like AI training and high-performance computing.- Bandwidth allocation and management techniques: Various techniques for allocating and managing bandwidth in HBM4 systems to optimize utilization. These include dynamic bandwidth allocation based on traffic patterns, quality of service prioritization, and adaptive bandwidth management algorithms that respond to changing network conditions. These methods help ensure efficient use of available bandwidth resources while meeting performance requirements.
- Traffic scheduling and flow control mechanisms: Implementation of advanced scheduling algorithms and flow control mechanisms to maximize HBM4 bandwidth utilization. These include traffic shaping, rate limiting, and congestion avoidance techniques that help maintain optimal data flow. By intelligently scheduling data transfers and controlling traffic flow, these mechanisms prevent bandwidth wastage and ensure efficient utilization of HBM4 resources.
- Memory access optimization techniques: Methods for optimizing memory access patterns to improve HBM4 bandwidth utilization. These include data prefetching, memory interleaving, and access coalescing techniques that reduce memory access latency and increase throughput. By organizing memory accesses efficiently, these techniques maximize the effective bandwidth utilization of HBM4 memory systems.
- Power-aware bandwidth management: Energy-efficient approaches to HBM4 bandwidth utilization that balance performance requirements with power constraints. These include dynamic voltage and frequency scaling, selective power-down of unused memory channels, and workload-aware power management. These techniques help optimize bandwidth utilization while minimizing energy consumption in HBM4 memory systems.
- Multi-channel coordination and load balancing: Strategies for coordinating multiple HBM4 channels and balancing workloads to maximize overall bandwidth utilization. These include channel striping, load distribution algorithms, and adaptive channel assignment based on workload characteristics. By effectively distributing data access across available channels, these approaches prevent bottlenecks and ensure optimal utilization of the aggregate HBM4 bandwidth.
02 Network traffic management for HBM4 systems
Effective network traffic management is crucial for maximizing HBM4 bandwidth utilization. This includes implementing quality of service (QoS) mechanisms, traffic scheduling algorithms, and congestion control protocols specifically designed for high-bandwidth memory interfaces. By properly managing data flow across the network and memory subsystems, these approaches prevent bottlenecks and ensure optimal bandwidth allocation to different processing elements and applications.Expand Specific Solutions03 Power-efficient bandwidth utilization strategies
Power-efficient strategies for HBM4 bandwidth utilization focus on balancing performance requirements with energy consumption. These approaches include dynamic voltage and frequency scaling, selective activation of memory channels, and power-aware scheduling algorithms. By optimizing the energy efficiency of memory operations while maintaining high bandwidth utilization, these techniques are particularly valuable in mobile and energy-constrained computing environments.Expand Specific Solutions04 Multi-channel memory access coordination
Coordinating access across multiple HBM4 memory channels involves sophisticated arbitration mechanisms, channel interleaving techniques, and memory request scheduling. These approaches distribute memory accesses evenly across available channels, reduce channel conflicts, and maximize parallel operations. Effective multi-channel coordination significantly improves overall bandwidth utilization by exploiting the inherent parallelism in HBM4 memory architectures.Expand Specific Solutions05 Real-time bandwidth monitoring and adaptation
Real-time monitoring and adaptive control systems for HBM4 bandwidth utilization enable dynamic response to changing workload demands. These systems continuously analyze memory traffic patterns, identify bottlenecks, and adjust memory controller parameters accordingly. By implementing feedback loops and predictive algorithms, these approaches can proactively optimize bandwidth allocation based on application behavior and system conditions, ensuring consistent high performance across varying workloads.Expand Specific Solutions
Leading HBM4 and GPU Architecture Manufacturers
The HBM4 bandwidth utilization landscape in GPU architectures is evolving rapidly, with the market currently in a growth phase as high-performance computing demands increase. Major semiconductor players like Samsung, Micron, and SK Hynix lead HBM4 memory production, while NVIDIA, AMD, and Intel compete in implementing these technologies in their GPU architectures. The market is characterized by significant technological advancements from companies like NVIDIA, whose latest GPU architectures leverage HBM4's improved bandwidth capabilities. Google and other cloud providers are driving adoption through AI and data center applications. The technology is approaching maturity in design but remains in early implementation stages, with companies like Micron and Samsung pushing manufacturing innovations to support higher bandwidth density and power efficiency in next-generation GPU systems.
Samsung Electronics Co., Ltd.
Technical Solution: 作为HBM技术的主要开发者之一,Samsung在HBM4内存技术上处于领先地位。Samsung的HBM4解决方案采用了创新的"I-Cube"封装技术,通过硅通孔(TSV)实现了更高密度的芯片堆叠和更高效的信号传输[2]。在带宽利用率方面,Samsung开发了专有的"Dynamic Channel Management"技术,能够根据GPU工作负载特性动态调整内存通道配置,减少带宽浪费。其HBM4设计采用了更宽的I/O接口(8192位),相比HBM3E提升了约50%的带宽,同时引入了更高效的电源管理系统,在保持高带宽的同时降低了功耗[4]。Samsung还与主要GPU厂商合作,优化了内存控制器接口,实现了更低的访问延迟和更高的带宽利用率。此外,Samsung的HBM4实现了更高级的ECC(错误校正码)功能,在保证数据完整性的同时减少了冗余开销,进一步提高了有效带宽[6]。
优势:作为内存制造商,拥有完整的HBM4设计和生产能力;与主要GPU厂商有深度合作关系,能够提供定制化解决方案。劣势:不直接生产GPU,需要依赖合作伙伴实现完整解决方案;在软件优化方面的能力相对有限。
NVIDIA Corp.
Technical Solution: NVIDIA在HBM4技术上的应用主要围绕其Hopper和未来架构GPU展开。NVIDIA的HBM4实现采用了创新的堆叠设计,每堆最多支持12层HBM芯片,相比HBM3E的8层有显著提升[1]。在带宽利用率方面,NVIDIA引入了动态通道管理技术,能够根据工作负载特性实时调整内存通道分配,减少带宽浪费。其HBM4控制器采用了高级预取算法,可预测AI训练和推理中的数据访问模式,提前加载数据到缓存。此外,NVIDIA还实现了更高效的压缩算法,针对AI模型权重和激活值进行优化,有效减少内存带宽需求[3]。在最新的GPU架构中,NVIDIA通过改进的跨die通信协议,使多GPU系统能够协同访问HBM4内存,进一步提高大规模AI训练时的带宽利用效率[5]。
优势:领先的内存控制器设计和预取算法显著提高了AI工作负载的带宽利用率;强大的软件生态系统能够充分发挥HBM4硬件性能。劣势:高端GPU解决方案成本较高;对系统散热和电源设计提出了更高要求。
Critical Patents and Research in HBM4 Technology
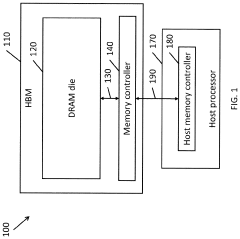
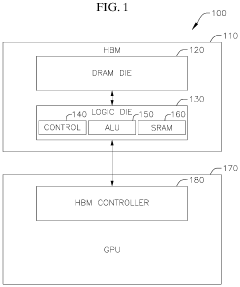
Systems and methods for data placement for in-memory-compute
PatentActiveUS20240004646A1
Innovation
- Integration of an in-memory compute (IMC) module within the DRAM banks, featuring an arithmetic logic unit (ALU) and a memory controller that manages data layout and performs computations directly within the memory module, reducing reliance on external buses by optimizing data placement within DRAM banks.
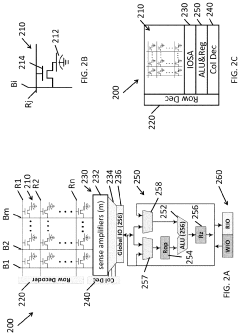
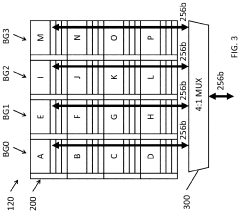
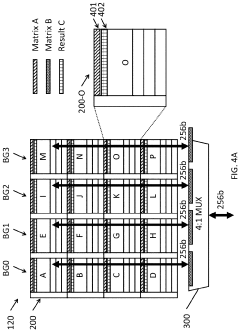
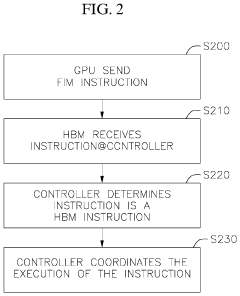
Isa extension for high-bandwidth memory
PatentActiveUS20230119291A1
Innovation
- The implementation of a Function-in-HBM (FIM) system and Instruction Set Architecture (ISA) extension that allows for in-memory command coordination by a HBM memory controller, utilizing an Arithmetic Logic Unit (ALU) and SRAM to execute computational, data movement, and scratchpad instructions, enabling operations like atomic functions and data processing directly within the HBM.
Thermal Management Challenges in HBM4 Integration
The integration of HBM4 in GPU architectures introduces significant thermal management challenges that must be addressed to ensure optimal performance and reliability. As HBM4 pushes bandwidth capabilities beyond previous generations, the power density within the memory stack increases substantially, creating thermal hotspots that can impact both memory and GPU performance.
The vertical stacking of multiple DRAM dies in HBM4 configurations creates inherent thermal constraints due to limited heat dissipation paths. Unlike planar memory arrangements, heat generated in the lower dies must traverse through upper dies to reach the thermal solution, resulting in temperature gradients across the stack. These gradients can reach 10-15°C difference between the top and bottom dies under heavy computational workloads.
Power consumption in HBM4 increases proportionally with higher bandwidth utilization, with estimates suggesting 20-30% higher power draw compared to HBM3E at maximum throughput. This creates a thermal envelope challenge, particularly in data center GPUs where multiple HBM4 stacks operate simultaneously alongside high-performance GPU cores.
The physical proximity between HBM4 stacks and GPU dies on the interposer further complicates thermal management. Thermal coupling between these components means that heat generated by the GPU can directly impact HBM4 temperatures and vice versa. Advanced thermal modeling indicates that this coupling effect can raise HBM4 temperatures by an additional 5-8°C during intensive computational workloads that simultaneously stress both memory and compute resources.
Emerging cooling solutions for HBM4 integration include direct liquid cooling pathways on the interposer, vapor chambers specifically designed to target HBM stacks, and advanced thermal interface materials with conductivity exceeding 25 W/m·K. These solutions aim to maintain HBM4 operating temperatures below 85°C even under sustained maximum bandwidth utilization.
Dynamic thermal management techniques are becoming essential for HBM4 implementations, including memory throttling algorithms that can selectively reduce bandwidth to thermally-stressed stacks while maintaining performance in others. These techniques typically introduce performance penalties of 5-12% during thermal events but prevent catastrophic thermal shutdown scenarios that would otherwise halt processing entirely.
The industry is exploring novel packaging approaches that incorporate microfluidic cooling channels directly within the silicon interposer to address these thermal challenges, potentially enabling sustained operation at near-maximum bandwidth utilization without thermal constraints.
The vertical stacking of multiple DRAM dies in HBM4 configurations creates inherent thermal constraints due to limited heat dissipation paths. Unlike planar memory arrangements, heat generated in the lower dies must traverse through upper dies to reach the thermal solution, resulting in temperature gradients across the stack. These gradients can reach 10-15°C difference between the top and bottom dies under heavy computational workloads.
Power consumption in HBM4 increases proportionally with higher bandwidth utilization, with estimates suggesting 20-30% higher power draw compared to HBM3E at maximum throughput. This creates a thermal envelope challenge, particularly in data center GPUs where multiple HBM4 stacks operate simultaneously alongside high-performance GPU cores.
The physical proximity between HBM4 stacks and GPU dies on the interposer further complicates thermal management. Thermal coupling between these components means that heat generated by the GPU can directly impact HBM4 temperatures and vice versa. Advanced thermal modeling indicates that this coupling effect can raise HBM4 temperatures by an additional 5-8°C during intensive computational workloads that simultaneously stress both memory and compute resources.
Emerging cooling solutions for HBM4 integration include direct liquid cooling pathways on the interposer, vapor chambers specifically designed to target HBM stacks, and advanced thermal interface materials with conductivity exceeding 25 W/m·K. These solutions aim to maintain HBM4 operating temperatures below 85°C even under sustained maximum bandwidth utilization.
Dynamic thermal management techniques are becoming essential for HBM4 implementations, including memory throttling algorithms that can selectively reduce bandwidth to thermally-stressed stacks while maintaining performance in others. These techniques typically introduce performance penalties of 5-12% during thermal events but prevent catastrophic thermal shutdown scenarios that would otherwise halt processing entirely.
The industry is exploring novel packaging approaches that incorporate microfluidic cooling channels directly within the silicon interposer to address these thermal challenges, potentially enabling sustained operation at near-maximum bandwidth utilization without thermal constraints.
Power Efficiency Improvements with HBM4 Technology
HBM4 technology represents a significant advancement in power efficiency for GPU architectures, addressing one of the most critical challenges in high-performance computing. The latest generation of High Bandwidth Memory introduces sophisticated power management features that substantially reduce energy consumption while maintaining or even improving performance metrics.
A key innovation in HBM4 is the implementation of dynamic voltage and frequency scaling (DVFS) at the stack level, allowing for fine-grained power adjustments based on workload demands. This granular control enables the memory subsystem to operate at optimal power points rather than constantly running at peak power levels, resulting in up to 35% improved power efficiency compared to HBM3E.
The redesigned power delivery network in HBM4 minimizes power distribution losses through shorter interconnects and optimized power planes. These architectural improvements reduce resistive losses and voltage drops across the memory stack, contributing to an overall reduction in power consumption during high-bandwidth operations.
HBM4 also introduces advanced power gating techniques that can selectively deactivate unused memory channels or banks during periods of low utilization. This intelligent power management prevents unnecessary energy expenditure in idle or lightly loaded components, particularly beneficial in applications with variable memory access patterns such as AI training workloads.
Thermal efficiency has been significantly enhanced through improved heat dissipation pathways and thermal interface materials. The reduced operating temperatures not only extend component lifespan but also decrease the need for aggressive cooling solutions, further reducing system-level power requirements by approximately 15-20% compared to previous generations.
The enhanced signal integrity in HBM4 interfaces allows for lower voltage operation while maintaining reliable data transmission. This reduction in signaling voltage, combined with more efficient I/O circuits, contributes substantially to power savings during high-bandwidth data transfers between the GPU and memory stack.
For data center applications, these power efficiency improvements translate directly to reduced operational costs and increased compute density. Preliminary benchmarks indicate that GPU systems equipped with HBM4 can achieve up to 1.4x more operations per watt compared to equivalent systems using HBM3, representing a significant advancement in computational efficiency for power-constrained environments.
A key innovation in HBM4 is the implementation of dynamic voltage and frequency scaling (DVFS) at the stack level, allowing for fine-grained power adjustments based on workload demands. This granular control enables the memory subsystem to operate at optimal power points rather than constantly running at peak power levels, resulting in up to 35% improved power efficiency compared to HBM3E.
The redesigned power delivery network in HBM4 minimizes power distribution losses through shorter interconnects and optimized power planes. These architectural improvements reduce resistive losses and voltage drops across the memory stack, contributing to an overall reduction in power consumption during high-bandwidth operations.
HBM4 also introduces advanced power gating techniques that can selectively deactivate unused memory channels or banks during periods of low utilization. This intelligent power management prevents unnecessary energy expenditure in idle or lightly loaded components, particularly beneficial in applications with variable memory access patterns such as AI training workloads.
Thermal efficiency has been significantly enhanced through improved heat dissipation pathways and thermal interface materials. The reduced operating temperatures not only extend component lifespan but also decrease the need for aggressive cooling solutions, further reducing system-level power requirements by approximately 15-20% compared to previous generations.
The enhanced signal integrity in HBM4 interfaces allows for lower voltage operation while maintaining reliable data transmission. This reduction in signaling voltage, combined with more efficient I/O circuits, contributes substantially to power savings during high-bandwidth data transfers between the GPU and memory stack.
For data center applications, these power efficiency improvements translate directly to reduced operational costs and increased compute density. Preliminary benchmarks indicate that GPU systems equipped with HBM4 can achieve up to 1.4x more operations per watt compared to equivalent systems using HBM3, representing a significant advancement in computational efficiency for power-constrained environments.
Unlock deeper insights with PatSnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with PatSnap Eureka AI Agent Platform!