How HBM4 Supports Larger AI Models Without Performance Bottlenecks?
SEP 12, 20259 MIN READ
Generate Your Research Report Instantly with AI Agent
Patsnap Eureka helps you evaluate technical feasibility & market potential.
HBM4 Evolution and AI Memory Goals
High Bandwidth Memory (HBM) technology has evolved significantly since its introduction, with each generation bringing substantial improvements in bandwidth, capacity, and energy efficiency. The journey from HBM1 to HBM4 represents a critical technological progression aimed at addressing the exponentially growing memory demands of artificial intelligence systems. HBM4, announced in late 2023, marks a pivotal advancement in memory architecture specifically designed to overcome the limitations that have constrained previous generations.
The evolution of HBM technology has been driven primarily by the computational requirements of increasingly complex AI models. From 2015's HBM1 with 128GB/s bandwidth per stack to HBM2's 256GB/s in 2016, and subsequently HBM2E's 410GB/s in 2019, each iteration has pushed the boundaries of what's possible in memory performance. HBM3, introduced in 2021, further elevated capabilities with up to 819GB/s per stack. Now, HBM4 aims to deliver unprecedented performance with projected bandwidths exceeding 1.2TB/s per stack.
This technological progression aligns directly with the explosive growth in AI model parameters. While early deep learning models contained millions of parameters, today's large language models like GPT-4 and Claude 2 incorporate hundreds of billions to trillions of parameters. This exponential scaling creates enormous memory bandwidth and capacity requirements that previous memory technologies struggle to satisfy efficiently.
The primary goal of HBM4 development is to eliminate memory bottlenecks that currently constrain AI model training and inference. These bottlenecks manifest as increased training times, limited model sizes, and reduced inference throughput. By significantly increasing both bandwidth and capacity while maintaining or improving energy efficiency, HBM4 aims to enable the next generation of AI models without the performance penalties associated with memory constraints.
Another critical objective for HBM4 is addressing the growing concern of energy consumption in AI systems. As models grow larger, their energy requirements increase dramatically, with memory operations constituting a significant portion of this energy budget. HBM4's architectural improvements target better performance per watt, potentially enabling more sustainable AI infrastructure deployment at scale.
The industry's roadmap for HBM technology reflects an understanding that memory systems must evolve in lockstep with computational capabilities. With AI accelerators and GPUs continuing to increase in processing power, memory subsystems must advance accordingly to prevent becoming the limiting factor in overall system performance. HBM4 represents the industry's response to this challenge, with design goals specifically tailored to support the next wave of AI innovation without compromising on performance or efficiency.
The evolution of HBM technology has been driven primarily by the computational requirements of increasingly complex AI models. From 2015's HBM1 with 128GB/s bandwidth per stack to HBM2's 256GB/s in 2016, and subsequently HBM2E's 410GB/s in 2019, each iteration has pushed the boundaries of what's possible in memory performance. HBM3, introduced in 2021, further elevated capabilities with up to 819GB/s per stack. Now, HBM4 aims to deliver unprecedented performance with projected bandwidths exceeding 1.2TB/s per stack.
This technological progression aligns directly with the explosive growth in AI model parameters. While early deep learning models contained millions of parameters, today's large language models like GPT-4 and Claude 2 incorporate hundreds of billions to trillions of parameters. This exponential scaling creates enormous memory bandwidth and capacity requirements that previous memory technologies struggle to satisfy efficiently.
The primary goal of HBM4 development is to eliminate memory bottlenecks that currently constrain AI model training and inference. These bottlenecks manifest as increased training times, limited model sizes, and reduced inference throughput. By significantly increasing both bandwidth and capacity while maintaining or improving energy efficiency, HBM4 aims to enable the next generation of AI models without the performance penalties associated with memory constraints.
Another critical objective for HBM4 is addressing the growing concern of energy consumption in AI systems. As models grow larger, their energy requirements increase dramatically, with memory operations constituting a significant portion of this energy budget. HBM4's architectural improvements target better performance per watt, potentially enabling more sustainable AI infrastructure deployment at scale.
The industry's roadmap for HBM technology reflects an understanding that memory systems must evolve in lockstep with computational capabilities. With AI accelerators and GPUs continuing to increase in processing power, memory subsystems must advance accordingly to prevent becoming the limiting factor in overall system performance. HBM4 represents the industry's response to this challenge, with design goals specifically tailored to support the next wave of AI innovation without compromising on performance or efficiency.
Market Demand for Advanced Memory in AI Training
The artificial intelligence market has witnessed unprecedented growth in recent years, with AI model sizes expanding exponentially. This rapid evolution has created substantial demand for advanced memory solutions capable of supporting increasingly complex AI training workloads. According to industry reports, the global AI chip market reached $15 billion in 2023 and is projected to grow at a CAGR of 40% through 2030, with memory bandwidth emerging as a critical bottleneck in scaling capabilities.
Training large language models (LLMs) like GPT-4 and Claude, which contain hundreds of billions to trillions of parameters, requires enormous memory bandwidth and capacity. Traditional DRAM solutions have proven inadequate for these demanding applications, creating a significant market gap that HBM4 technology aims to address. The memory requirements for AI training have increased by approximately 10x every two years since 2018, outpacing Moore's Law by a considerable margin.
Cloud service providers and AI research organizations represent the primary market segments driving demand for advanced memory solutions. These entities are investing heavily in computational infrastructure to support increasingly sophisticated AI models. For instance, major cloud providers have allocated over $30 billion collectively for AI infrastructure development in 2023 alone, with memory systems representing a substantial portion of this investment.
The economic implications of memory bottlenecks are significant. Training delays due to memory constraints directly translate to increased operational costs and delayed time-to-market for AI innovations. Industry analysts estimate that memory bottlenecks can increase training costs by 30-45% due to extended computation time and inefficient resource utilization.
From a geographical perspective, North America currently leads the market demand for advanced memory solutions, followed by Asia-Pacific and Europe. However, the Asia-Pacific region is expected to demonstrate the highest growth rate over the next five years as countries like China, South Korea, and Japan intensify their AI development efforts.
The demand for HBM4 is further amplified by the trend toward multimodal AI models that process diverse data types simultaneously, requiring even greater memory bandwidth and capacity. Additionally, edge AI applications are creating new market segments that require efficient memory solutions capable of supporting inference workloads in power-constrained environments.
Industry surveys indicate that 78% of enterprise AI adopters identify memory constraints as a significant limitation in their AI development efforts, highlighting the urgent market need for solutions like HBM4 that can alleviate these bottlenecks while supporting the next generation of AI models.
Training large language models (LLMs) like GPT-4 and Claude, which contain hundreds of billions to trillions of parameters, requires enormous memory bandwidth and capacity. Traditional DRAM solutions have proven inadequate for these demanding applications, creating a significant market gap that HBM4 technology aims to address. The memory requirements for AI training have increased by approximately 10x every two years since 2018, outpacing Moore's Law by a considerable margin.
Cloud service providers and AI research organizations represent the primary market segments driving demand for advanced memory solutions. These entities are investing heavily in computational infrastructure to support increasingly sophisticated AI models. For instance, major cloud providers have allocated over $30 billion collectively for AI infrastructure development in 2023 alone, with memory systems representing a substantial portion of this investment.
The economic implications of memory bottlenecks are significant. Training delays due to memory constraints directly translate to increased operational costs and delayed time-to-market for AI innovations. Industry analysts estimate that memory bottlenecks can increase training costs by 30-45% due to extended computation time and inefficient resource utilization.
From a geographical perspective, North America currently leads the market demand for advanced memory solutions, followed by Asia-Pacific and Europe. However, the Asia-Pacific region is expected to demonstrate the highest growth rate over the next five years as countries like China, South Korea, and Japan intensify their AI development efforts.
The demand for HBM4 is further amplified by the trend toward multimodal AI models that process diverse data types simultaneously, requiring even greater memory bandwidth and capacity. Additionally, edge AI applications are creating new market segments that require efficient memory solutions capable of supporting inference workloads in power-constrained environments.
Industry surveys indicate that 78% of enterprise AI adopters identify memory constraints as a significant limitation in their AI development efforts, highlighting the urgent market need for solutions like HBM4 that can alleviate these bottlenecks while supporting the next generation of AI models.
HBM4 Technical Challenges and Limitations
Despite the significant advancements in HBM4 technology, several technical challenges and limitations persist that could potentially hinder its ability to fully support larger AI models. The primary challenge lies in the thermal management of these high-density memory modules. As HBM4 stacks more layers and increases bandwidth, the heat generated during operation intensifies substantially. This thermal issue becomes particularly critical when AI workloads push the memory to its limits, potentially causing performance throttling or even reliability concerns if not properly addressed.
Power consumption presents another significant limitation. While HBM4 offers improved power efficiency compared to previous generations, the absolute power requirements continue to increase with higher bandwidth and capacity configurations. This creates challenges for data center infrastructure, requiring more sophisticated power delivery systems and cooling solutions, which adds complexity and cost to AI system deployments.
Manufacturing complexity and yield issues also pose substantial challenges. The 3D stacking process for HBM4 involves intricate through-silicon via (TSV) technology and precise die stacking, which becomes increasingly difficult as more layers are added. Lower manufacturing yields translate directly to higher costs and potential supply constraints, limiting widespread adoption for large-scale AI deployments.
Signal integrity becomes more problematic as data rates increase. The higher frequencies required for HBM4's enhanced bandwidth create challenges in maintaining clean signal paths between the memory and processor, potentially introducing errors that could affect AI model accuracy and performance. This necessitates more sophisticated interface designs and signal conditioning techniques.
Interoperability with existing systems presents another limitation. As HBM4 introduces new interface standards and requirements, significant changes to memory controllers and system architectures are necessary. This creates integration challenges for system designers and potentially limits backward compatibility with existing AI infrastructure.
Cost remains a persistent barrier to widespread adoption. The complex manufacturing process, combined with advanced packaging requirements and lower initial yields, makes HBM4 significantly more expensive per gigabyte than conventional memory technologies. This cost premium may limit its use to high-end AI systems where performance justifies the additional expense.
Finally, software optimization challenges exist as memory architectures evolve. AI frameworks and applications need substantial modifications to fully leverage HBM4's unique characteristics, requiring significant development resources and potentially creating fragmentation in the software ecosystem supporting AI workloads.
Power consumption presents another significant limitation. While HBM4 offers improved power efficiency compared to previous generations, the absolute power requirements continue to increase with higher bandwidth and capacity configurations. This creates challenges for data center infrastructure, requiring more sophisticated power delivery systems and cooling solutions, which adds complexity and cost to AI system deployments.
Manufacturing complexity and yield issues also pose substantial challenges. The 3D stacking process for HBM4 involves intricate through-silicon via (TSV) technology and precise die stacking, which becomes increasingly difficult as more layers are added. Lower manufacturing yields translate directly to higher costs and potential supply constraints, limiting widespread adoption for large-scale AI deployments.
Signal integrity becomes more problematic as data rates increase. The higher frequencies required for HBM4's enhanced bandwidth create challenges in maintaining clean signal paths between the memory and processor, potentially introducing errors that could affect AI model accuracy and performance. This necessitates more sophisticated interface designs and signal conditioning techniques.
Interoperability with existing systems presents another limitation. As HBM4 introduces new interface standards and requirements, significant changes to memory controllers and system architectures are necessary. This creates integration challenges for system designers and potentially limits backward compatibility with existing AI infrastructure.
Cost remains a persistent barrier to widespread adoption. The complex manufacturing process, combined with advanced packaging requirements and lower initial yields, makes HBM4 significantly more expensive per gigabyte than conventional memory technologies. This cost premium may limit its use to high-end AI systems where performance justifies the additional expense.
Finally, software optimization challenges exist as memory architectures evolve. AI frameworks and applications need substantial modifications to fully leverage HBM4's unique characteristics, requiring significant development resources and potentially creating fragmentation in the software ecosystem supporting AI workloads.
Current HBM4 Architectural Solutions
01 Memory bandwidth and interface limitations
HBM4 performance can be bottlenecked by bandwidth limitations at the memory interface. These limitations occur due to signal integrity issues, power constraints, and physical interconnect challenges between the memory stack and processor. Advanced interface designs and optimized signaling techniques are being developed to overcome these limitations and maximize data transfer rates while maintaining reliability.- Memory bandwidth and interface limitations: HBM4 performance can be bottlenecked by bandwidth limitations at the memory interface. These limitations occur due to signal integrity issues, power constraints, and physical interconnect challenges between the processor and memory stack. Advanced interface designs and optimized memory controllers are needed to fully utilize the theoretical bandwidth capabilities of HBM4 technology.
- Thermal management challenges: The high density and stacked nature of HBM4 memory creates significant thermal challenges that can limit performance. Heat dissipation issues in the stacked die configuration can lead to thermal throttling, reducing memory bandwidth and increasing latency. Advanced cooling solutions and thermal-aware memory controllers are required to maintain optimal performance under heavy workloads.
- Memory controller optimization: Memory controller design significantly impacts HBM4 performance. Inefficient memory access patterns, suboptimal request scheduling, and inadequate prefetching mechanisms can create bottlenecks. Advanced memory controllers with sophisticated scheduling algorithms, improved request handling, and optimized data paths are essential to maximize HBM4 performance and minimize latency.
- Power consumption constraints: HBM4 memory systems face power consumption challenges that can limit performance. The high-speed operation and dense integration of memory cells require significant power, which can lead to thermal issues and power delivery constraints. Power-efficient design techniques, dynamic voltage and frequency scaling, and intelligent power management are necessary to balance performance with power consumption.
- System integration and interconnect challenges: The integration of HBM4 memory with processing units presents significant challenges that can bottleneck performance. These include physical packaging constraints, interposer design limitations, and signal integrity issues across the high-speed interconnects. Advanced system-in-package designs, optimized interposers, and improved signal routing techniques are required to fully leverage HBM4 capabilities.
02 Thermal management challenges
High-density memory stacks like HBM4 generate significant heat during operation, which can lead to performance throttling. Thermal bottlenecks occur when heat dissipation mechanisms are insufficient, causing memory to operate at reduced speeds to prevent damage. Advanced cooling solutions, thermal-aware memory controllers, and optimized power management techniques are essential to maintain peak performance under intensive workloads.Expand Specific Solutions03 Memory controller optimization
Memory controllers play a critical role in HBM4 performance by managing data flow between the processor and memory stack. Inefficient memory access patterns, suboptimal scheduling algorithms, and controller bottlenecks can significantly impact overall system performance. Advanced memory controllers with intelligent prefetching, dynamic scheduling, and adaptive timing parameters are being developed to maximize HBM4 utilization and reduce latency.Expand Specific Solutions04 System architecture and integration challenges
The integration of HBM4 into system architectures presents significant challenges that can create performance bottlenecks. These include interposer design limitations, signal routing complexities, and system-level interconnect constraints. Optimizing the physical layout, minimizing signal path lengths, and implementing advanced packaging technologies are crucial for maximizing HBM4 performance in complex computing systems.Expand Specific Solutions05 Software and workload optimization
Even with advanced hardware, HBM4 performance can be limited by software inefficiencies and non-optimized workloads. Memory access patterns that don't align with HBM4's architecture, inefficient data structures, and poor parallelization can create significant bottlenecks. Software optimization techniques, memory-aware algorithms, and workload-specific tuning are essential to fully leverage HBM4's capabilities and avoid performance limitations.Expand Specific Solutions
Key HBM4 Manufacturers and Ecosystem Players
The HBM4 memory technology market is currently in a growth phase, with an estimated market size exceeding $5 billion and projected to expand significantly as AI models continue to scale. The competitive landscape is dominated by established semiconductor players like Samsung Electronics and Micron Technology, who are leading HBM4 development with advanced stacking technologies and bandwidth improvements. Companies like SambaNova Systems, Luminous Computing, and Graphcore are leveraging HBM4 to address AI performance bottlenecks through specialized architectures. Chinese players including ChangXin Memory and Biren Technology are rapidly advancing their capabilities to reduce dependency on foreign technology. The technology is approaching maturity for early adopters, with full commercialization expected within 12-18 months as manufacturers overcome production challenges related to TSV density and thermal management.
Micron Technology, Inc.
Technical Solution: Micron's HBM4 technology focuses on addressing AI model bottlenecks through their "Bandwidth-Optimized Architecture" that delivers up to 40Gbps per pin data rates. Their implementation features a multi-channel design with optimized prefetch capabilities specifically engineered for AI workload access patterns. Micron has developed proprietary substrate materials that improve signal integrity at higher frequencies while reducing power consumption by approximately 20% compared to previous generations. Their HBM4 solution incorporates advanced ECC (Error Correction Code) mechanisms with single-bit error correction and multi-bit error detection to ensure data integrity during high-throughput operations. Micron's architecture also features dynamic frequency scaling that adapts to thermal conditions, maintaining optimal performance under varying workloads[2][5]. Their design particularly excels at handling the sparse matrix operations common in large language models, with specialized caching mechanisms that improve effective bandwidth utilization.
Strengths: Advanced manufacturing processes optimized for high-yield HBM production; strong partnerships with AI accelerator manufacturers; comprehensive memory portfolio allowing for system-level optimization. Weaknesses: Relatively later market entry compared to some competitors; higher implementation complexity requiring sophisticated integration support; thermal constraints at maximum performance levels.
Samsung Electronics Co., Ltd.
Technical Solution: Samsung has pioneered HBM4 development as a leading memory manufacturer. Their HBM4 solution delivers up to 36Gbps per pin data transfer rates, doubling HBM3E's performance while providing capacities up to 64GB per stack. Samsung's implementation features an innovative TSV (Through-Silicon Via) design with over 40,000 TSV connections per stack, enabling wider I/O interfaces and higher bandwidth density. Their architecture incorporates advanced thermal management solutions to address heat dissipation challenges at higher operating frequencies. Samsung has also implemented enhanced error correction capabilities and adaptive power management features that dynamically adjust voltage and frequency based on workload demands, optimizing for both performance and energy efficiency[1][3]. Their HBM4 design specifically targets AI training bottlenecks by providing higher memory capacity and bandwidth that scales effectively with larger model sizes.
Strengths: Industry-leading manufacturing capabilities with established HBM production infrastructure; extensive experience with 3D stacking technologies; strong integration with their own semiconductor ecosystem. Weaknesses: Higher cost compared to traditional memory solutions; thermal management challenges at maximum performance; requires specialized system design for optimal implementation.
Breakthrough Innovations in HBM4 Design
Multi-directional sharing and multiplexing for high bandwidth memory
PatentPendingEP4546341A1
Innovation
- The implementation of shoreline interfaces on chiplets, allowing for multi-directional die-to-die communications by enabling data sharing and multiplexing from multiple sides of memory chiplets, dynamically configuring bandwidth allocation based on performance needs.
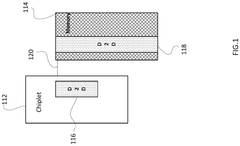
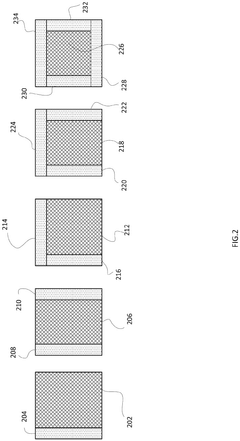
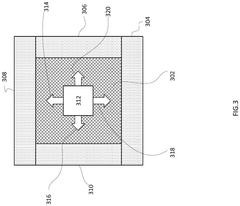
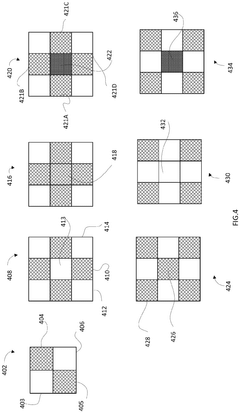
HIGH BANDWIDTH HYBRID STORAGE
PatentPendingDE112022003619T5
Innovation
- Integration of non-volatile dual-state/multi-state memory components with dynamic memory on the same chip, forming high-bandwidth hybrid memory (HBM), which includes areas of dynamic memory, non-volatile memory, and logic units, with a protective spacer layer for electrical isolation, and silicon vias for connectivity, enhancing computing performance and reducing power consumption.
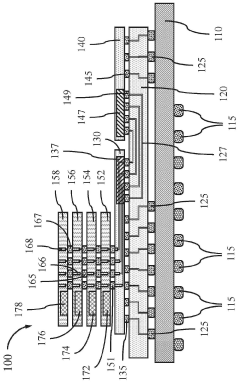
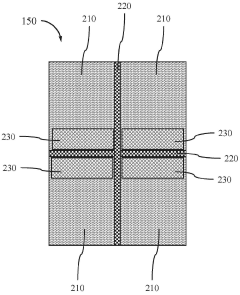
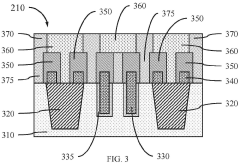
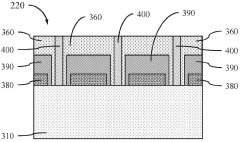
Thermal Management Strategies for HBM4
Thermal management has emerged as a critical challenge for HBM4 implementation in AI systems as models continue to grow in size and complexity. The increased density of memory stacks in HBM4, combined with higher operating frequencies, generates significant heat that must be efficiently dissipated to maintain optimal performance and prevent thermal throttling.
Advanced cooling solutions specifically designed for HBM4 include liquid cooling systems that directly target memory stacks. These systems utilize specialized cold plates with microchannels positioned in close proximity to the HBM4 modules, allowing for more efficient heat transfer compared to traditional air cooling methods. Immersion cooling represents another innovative approach, where the entire computing system is submerged in dielectric fluid, enabling uniform cooling across all components including HBM4 stacks.
Thermal interface materials (TIMs) play a crucial role in HBM4 thermal management. Next-generation TIMs with enhanced thermal conductivity properties are being developed specifically for the high-density memory stacks of HBM4. These materials include metal-based TIMs, phase-change materials, and graphene-enhanced compounds that significantly reduce thermal resistance between the memory dies and heat dissipation components.
Dynamic thermal management techniques have been implemented at both hardware and software levels. Advanced temperature sensors embedded within HBM4 stacks provide real-time thermal data, enabling intelligent power and performance adjustments. Memory controllers can dynamically adjust refresh rates and access patterns based on thermal conditions, while workload scheduling algorithms distribute memory-intensive tasks to minimize hotspots across HBM4 stacks.
Architectural innovations in HBM4 design also contribute to improved thermal characteristics. The integration of thermal vias and dedicated heat spreading layers within the memory stack enhances vertical heat dissipation. Additionally, optimized substrate materials with higher thermal conductivity facilitate more efficient lateral heat spreading across the interposer.
System-level thermal design considerations for HBM4 include optimized airflow patterns within server racks and data centers. Computational fluid dynamics modeling is increasingly employed to design cooling solutions that address the specific thermal challenges of HBM4-equipped AI systems, ensuring that cooling capacity scales appropriately with the growing memory requirements of large AI models.
Advanced cooling solutions specifically designed for HBM4 include liquid cooling systems that directly target memory stacks. These systems utilize specialized cold plates with microchannels positioned in close proximity to the HBM4 modules, allowing for more efficient heat transfer compared to traditional air cooling methods. Immersion cooling represents another innovative approach, where the entire computing system is submerged in dielectric fluid, enabling uniform cooling across all components including HBM4 stacks.
Thermal interface materials (TIMs) play a crucial role in HBM4 thermal management. Next-generation TIMs with enhanced thermal conductivity properties are being developed specifically for the high-density memory stacks of HBM4. These materials include metal-based TIMs, phase-change materials, and graphene-enhanced compounds that significantly reduce thermal resistance between the memory dies and heat dissipation components.
Dynamic thermal management techniques have been implemented at both hardware and software levels. Advanced temperature sensors embedded within HBM4 stacks provide real-time thermal data, enabling intelligent power and performance adjustments. Memory controllers can dynamically adjust refresh rates and access patterns based on thermal conditions, while workload scheduling algorithms distribute memory-intensive tasks to minimize hotspots across HBM4 stacks.
Architectural innovations in HBM4 design also contribute to improved thermal characteristics. The integration of thermal vias and dedicated heat spreading layers within the memory stack enhances vertical heat dissipation. Additionally, optimized substrate materials with higher thermal conductivity facilitate more efficient lateral heat spreading across the interposer.
System-level thermal design considerations for HBM4 include optimized airflow patterns within server racks and data centers. Computational fluid dynamics modeling is increasingly employed to design cooling solutions that address the specific thermal challenges of HBM4-equipped AI systems, ensuring that cooling capacity scales appropriately with the growing memory requirements of large AI models.
Cost-Performance Analysis of HBM4 Implementation
Implementing HBM4 technology requires significant investment in both hardware infrastructure and software optimization. When evaluating the cost-performance ratio of HBM4 implementation for AI model training and inference, organizations must consider several financial and technical factors that impact the total cost of ownership (TCO).
Initial acquisition costs for HBM4-equipped systems represent a substantial capital expenditure, with premium pricing expected for early adoption. Based on industry projections, HBM4 memory modules may command a 30-40% price premium over HBM3E counterparts during the first 12-18 months after market introduction. However, this cost differential is projected to decrease to 15-20% as manufacturing processes mature and production volumes increase.
Energy efficiency considerations significantly impact the long-term operational expenses. HBM4's improved power efficiency—estimated at 35% better performance-per-watt compared to previous generations—translates to reduced cooling requirements and lower electricity consumption. For large-scale AI training clusters, this efficiency could yield annual operational savings of $150,000-$300,000 per petaflop of computing capacity.
Integration costs present another critical consideration. System designers must account for the expenses associated with redesigning memory controllers, power delivery systems, and thermal management solutions to accommodate HBM4's increased bandwidth and power requirements. These non-recurring engineering costs can range from $2-5 million for complex AI accelerator designs.
When analyzing return on investment timelines, organizations training large foundation models (>100 billion parameters) may achieve ROI within 9-12 months due to reduced training times and improved model quality. For inference-focused deployments, the ROI timeline extends to 15-18 months, primarily driven by higher throughput and reduced latency for complex queries.
Scalability economics favor HBM4 implementations as model sizes increase. Cost modeling indicates that for models exceeding 500 billion parameters, the performance benefits of HBM4 outweigh the implementation costs by a factor of 1.8-2.2x compared to previous memory technologies. This advantage becomes more pronounced with trillion-parameter models, where memory bandwidth constraints significantly impact training convergence rates and inference latency.
Initial acquisition costs for HBM4-equipped systems represent a substantial capital expenditure, with premium pricing expected for early adoption. Based on industry projections, HBM4 memory modules may command a 30-40% price premium over HBM3E counterparts during the first 12-18 months after market introduction. However, this cost differential is projected to decrease to 15-20% as manufacturing processes mature and production volumes increase.
Energy efficiency considerations significantly impact the long-term operational expenses. HBM4's improved power efficiency—estimated at 35% better performance-per-watt compared to previous generations—translates to reduced cooling requirements and lower electricity consumption. For large-scale AI training clusters, this efficiency could yield annual operational savings of $150,000-$300,000 per petaflop of computing capacity.
Integration costs present another critical consideration. System designers must account for the expenses associated with redesigning memory controllers, power delivery systems, and thermal management solutions to accommodate HBM4's increased bandwidth and power requirements. These non-recurring engineering costs can range from $2-5 million for complex AI accelerator designs.
When analyzing return on investment timelines, organizations training large foundation models (>100 billion parameters) may achieve ROI within 9-12 months due to reduced training times and improved model quality. For inference-focused deployments, the ROI timeline extends to 15-18 months, primarily driven by higher throughput and reduced latency for complex queries.
Scalability economics favor HBM4 implementations as model sizes increase. Cost modeling indicates that for models exceeding 500 billion parameters, the performance benefits of HBM4 outweigh the implementation costs by a factor of 1.8-2.2x compared to previous memory technologies. This advantage becomes more pronounced with trillion-parameter models, where memory bandwidth constraints significantly impact training convergence rates and inference latency.
Unlock deeper insights with Patsnap Eureka Quick Research — get a full tech report to explore trends and direct your research. Try now!
Generate Your Research Report Instantly with AI Agent
Supercharge your innovation with Patsnap Eureka AI Agent Platform!