

Coordinated training-based dual-language named entity identification method
A technology for named entity recognition and named entity, applied in the field of natural language processing (NLP), which can solve the problems of performance degradation, unsatisfactory performance, and discomfort of supervised learning methods, and achieves reduction of domain dependence, improvement of consistency, and strong generalization. The effect of the ability to
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

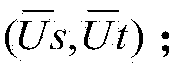
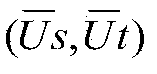
Examples
Embodiment Construction
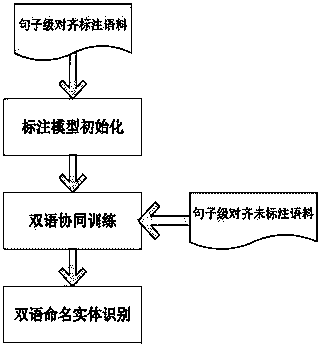
[0019] The specific implementation manner of the present invention will be described in further detail below in conjunction with the accompanying drawings.
[0020] A bilingual named entity recognition method based on collaborative training, comprising the following steps:
[0021] Step 1. Initialize the bilingual sequence tagging model, and train the Chinese-English sequence tagging models: Cmodel(s) and Cmodel(t) respectively on the tagged corpus sets Ls and Lt aligned at the Chinese-English sentence level. There are three named entities marked in the annotation corpus, namely PER (person name), LOC (place name) and ORG (organization name). The BIO annotation set is selected, and there are 7 types of annotations for all words: B-PER, I-PER, B-LOC, I-LOC, B-ORG, I-ORG, and O. Chinese uses single character features, single word features, 2-3 characters or word combination features; English uses word, part of speech, initial letter case feature combination templates.
[0022]...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More