

Accelerator beam trajectory control method and system based on deep reinforcement learning
A technology of reinforcement learning and orbit control, applied in general control systems, control/regulation systems, adaptive control and other directions, it can solve problems such as labor-consuming and time-consuming, PID parameter adjustment dependent on engineering experience, and complex beam orbit control problems.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
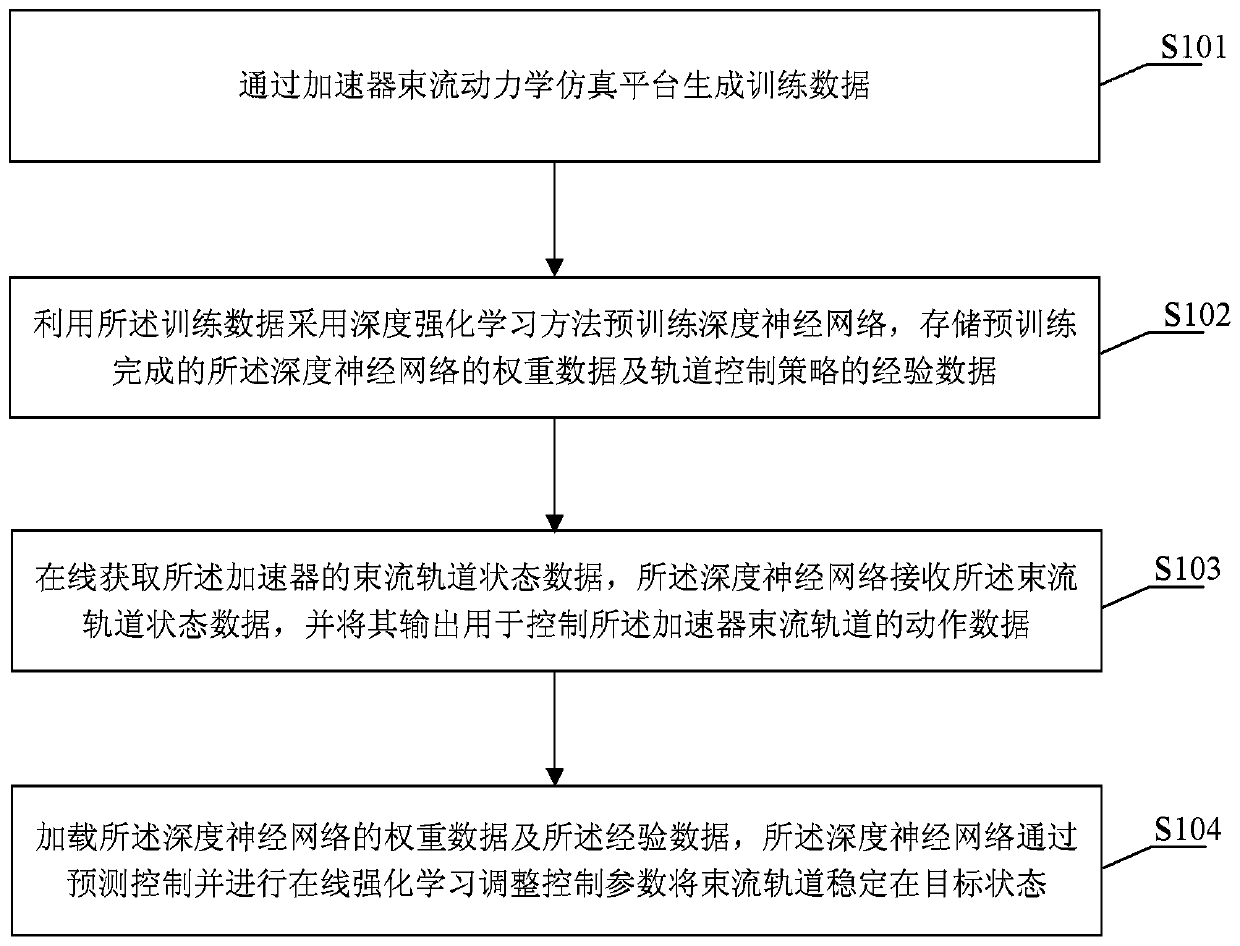
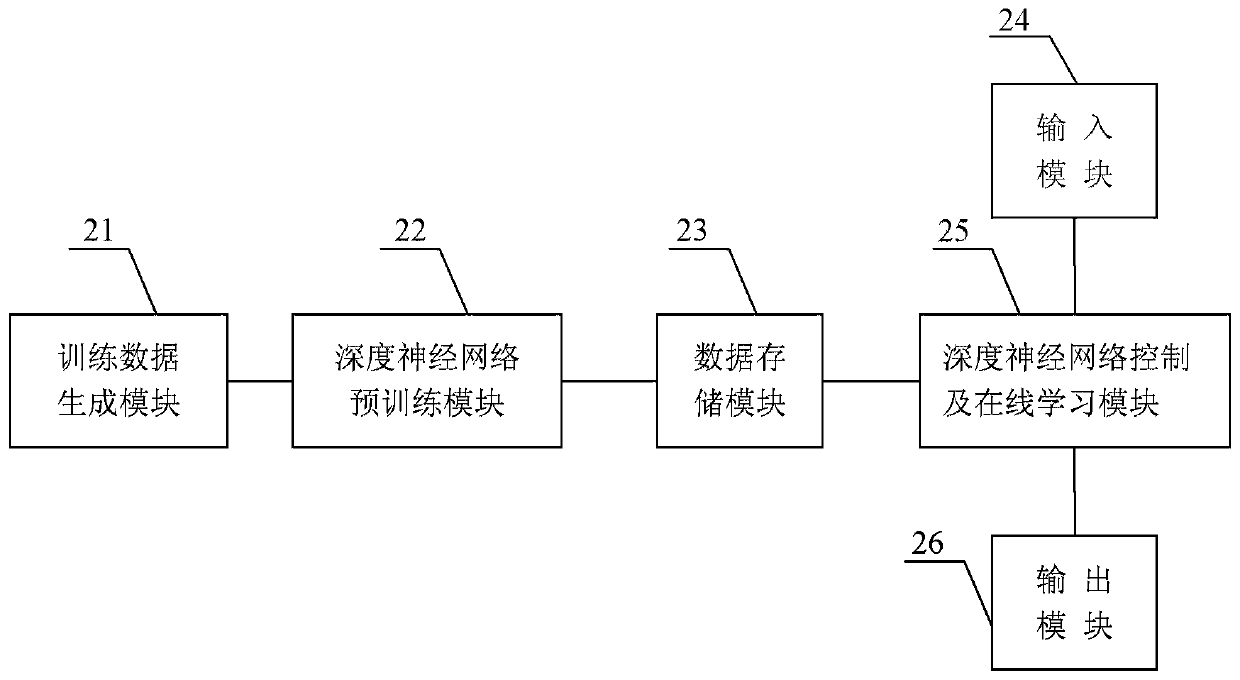
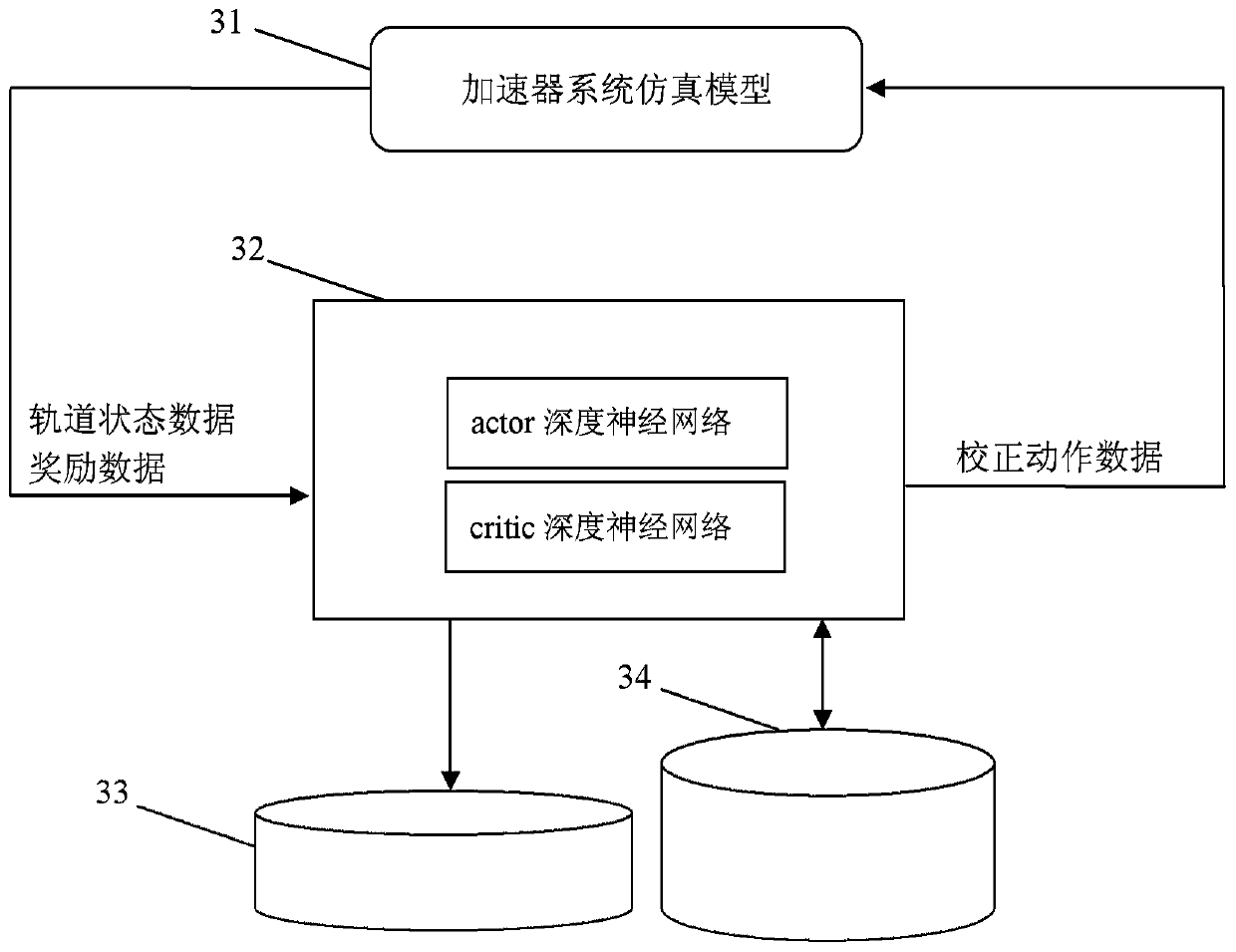
[0091] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with specific embodiments and with reference to the accompanying drawings.
[0092] The invention discloses a method and system for controlling the beam trajectory of an accelerator based on deep reinforcement learning, which is used to control the beam trajectory of the accelerator in a target state. The method utilizes training data and adopts a deep reinforcement learning method to perform a deep neural network Pre-training, store the weight parameters of the trained deep neural network and the empirical data of the orbit control strategy; use the beam position monitor to obtain the state data of the beam orbit online, feed it into the deep neural network, and The output of the deep neural network is coupled to the beam track corrector; the weight data of the trained deep neural network and the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More