A Text Classification Method Based on Few Samples
A text classification and sample technology, applied in text database clustering/classification, unstructured text data retrieval, instruments, etc., can solve the problems of a large number of manual annotations in the training set, inaccurate training classification with few samples, etc., and achieve training classification Inaccurate, avoiding manpower and time effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 2
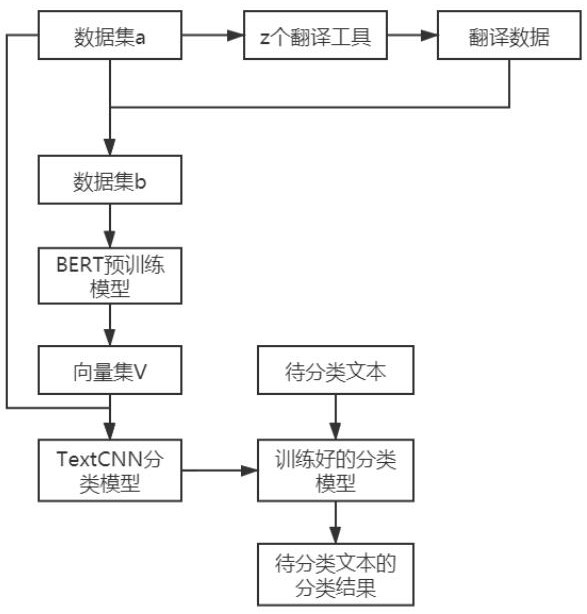
[0055] On the basis of embodiment 1, this embodiment provides a schematic case:
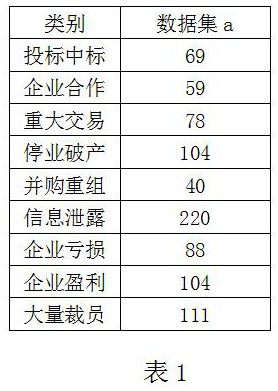
[0056] At present, there are marked financial-related data as data set a, and the categories included in data set a can be known, that is, there are 9 categories in Table 1 (m=9), and there are a total of 873 data items (n=879 / 9 =97). In actual use, the amount of data included in each type of data is not equal, so n is the average number of data pieces included in each type of data.
[0057]
[0058] Use Chinese-English, Chinese-Japanese, and Chinese-Korean translation tools to translate data set a in Table 1, and obtain data set b=9*97*(3+1)=3492 data, as shown in Table 2 Shown:
[0059]
[0060] After encoding the data set b using the BERT pre-training model corresponding to each translation tool, the vector set V is obtained, and then the vector set V is input into the TextCNN classification model for new connection until the model converges, and the trained model can be used for class...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com