

Approximate repetition detection method, system and terminal for large-scale long text data
A technology of approximate repetition and detection method, applied in the field of data processing, can solve problems such as difficult large-scale data cleaning, and achieve the effect of reducing the cost of communication reading and writing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



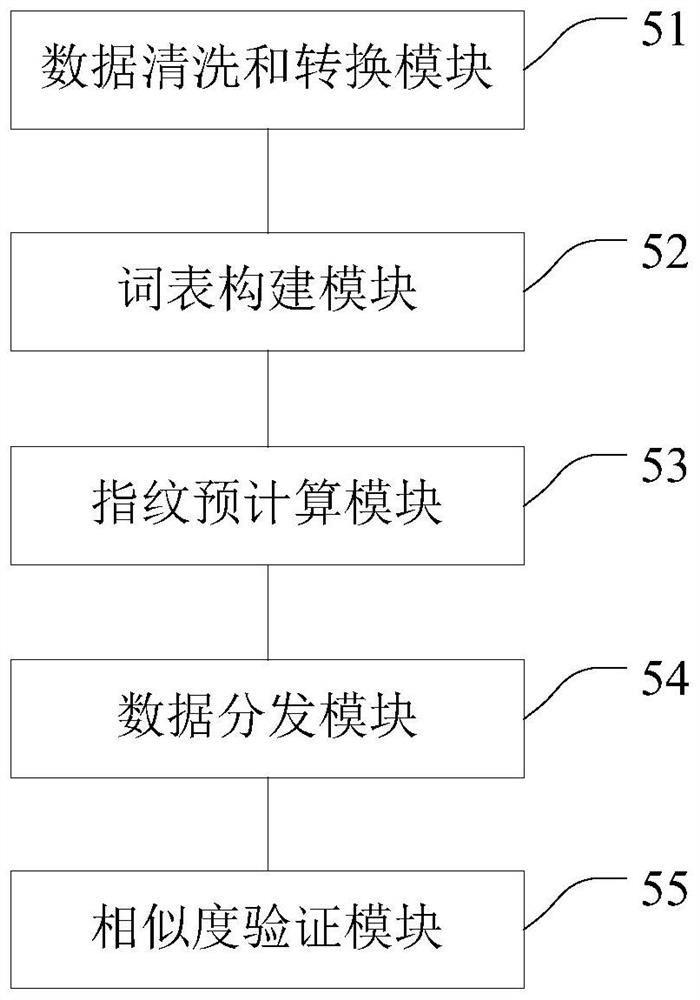
Examples
Embodiment Construction
[0057] In order to make the object, technical solution and advantages of the present invention more clear and definite, the present invention will be further described in detail below with reference to the accompanying drawings and examples. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
[0058] The approximate repetition detection method of large-scale long text data described in the preferred embodiment of the present invention, such as figure 1 and figure 2 As shown, the approximate repetition detection method of the large-scale long text data comprises the following steps:
[0059] Step S10, read the corpus data as the original input document, process the original input document to obtain the first processed document including the document global number, divide the original input document into word sets to obtain the second processed document, and The second proces...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More