

Chinese text parallel data mining method based on hierarchy
A data mining and text technology, applied in the field of information processing, can solve the problems of low mining efficiency and large amount of original data, and achieve the effects of improving calculation speed, high word segmentation accuracy, and high efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

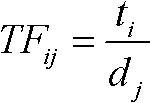
Examples
Embodiment Construction
[0013] The present invention will be further described below in conjunction with the drawings and specific implementations.
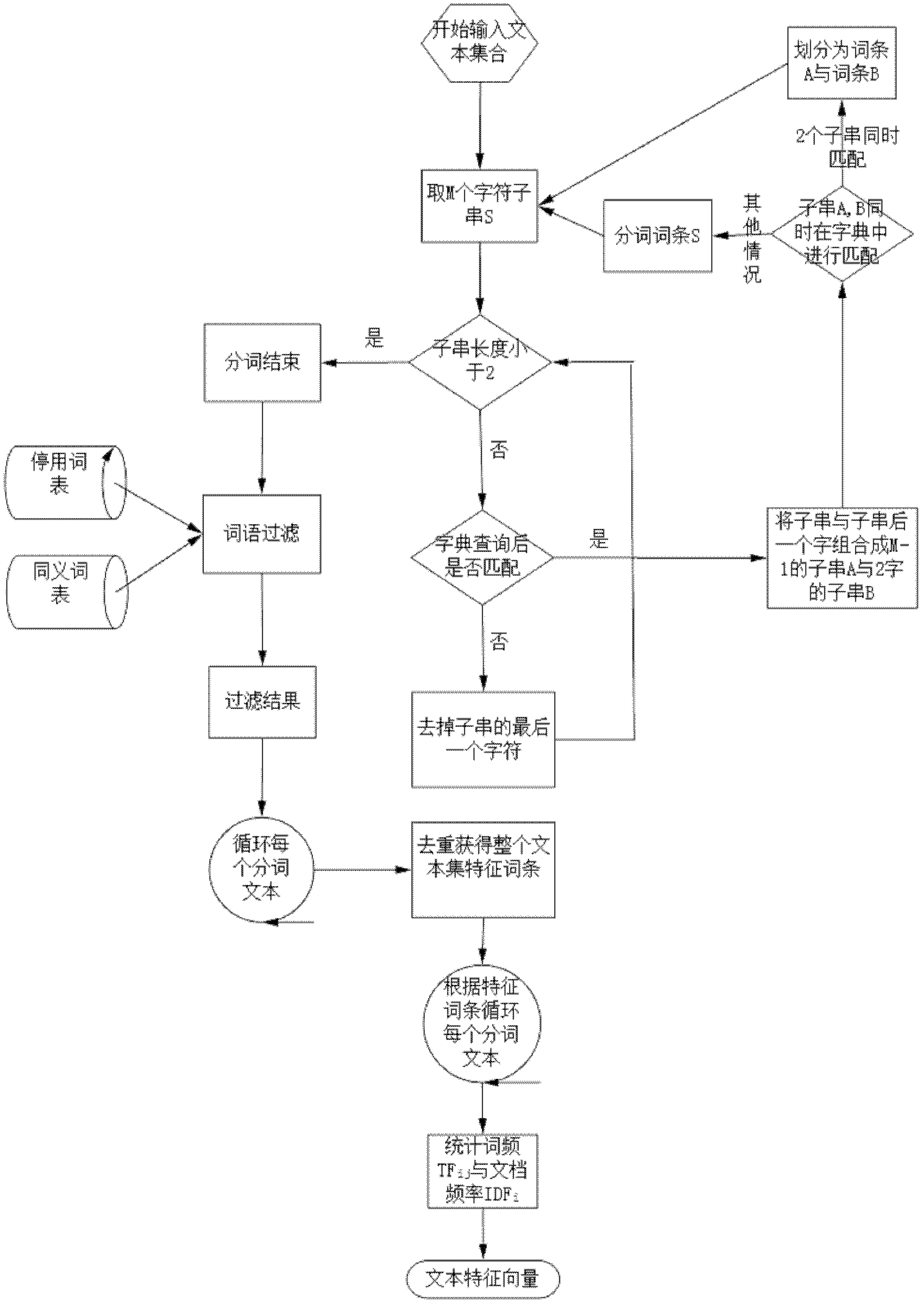
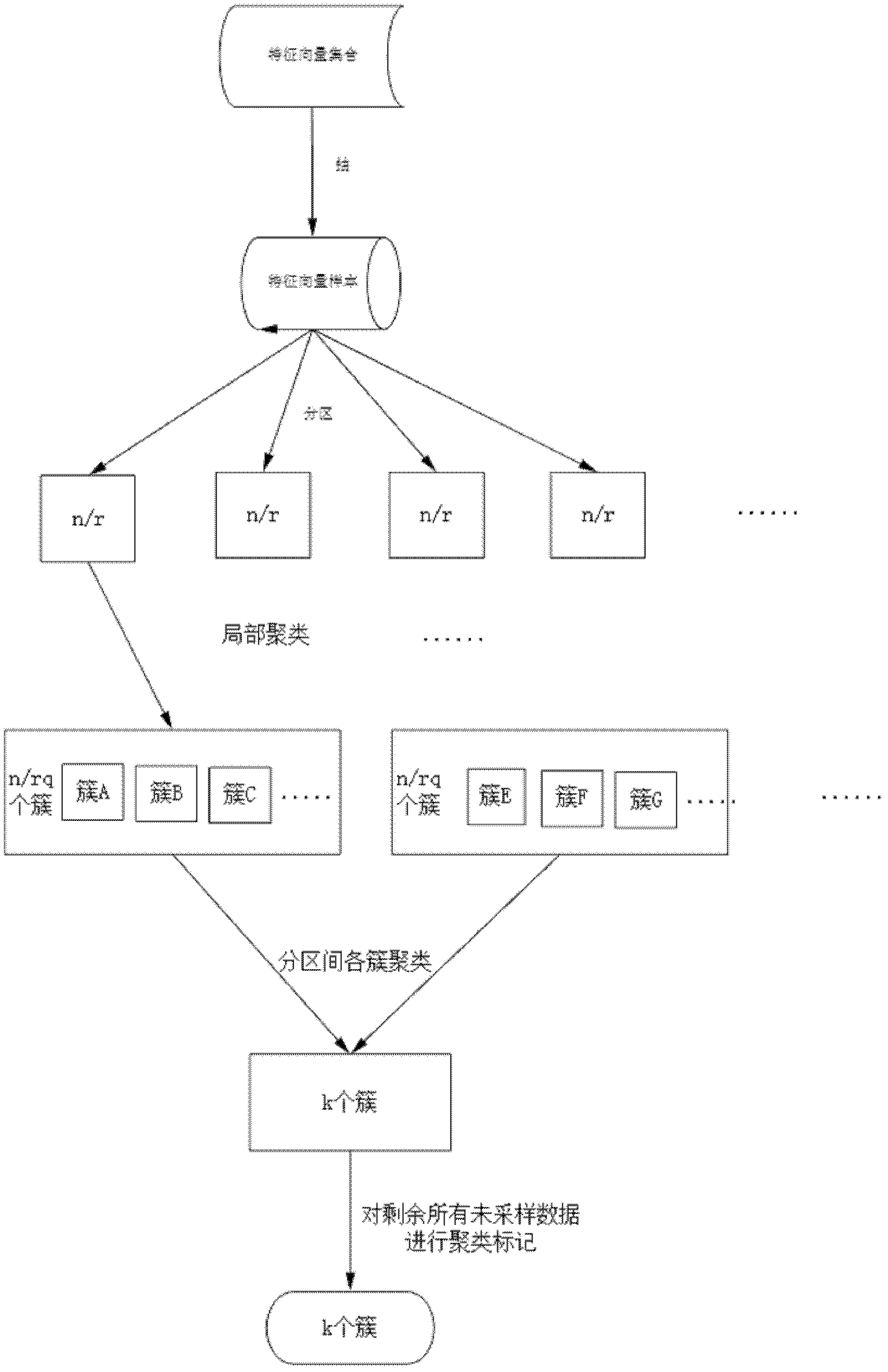
[0014] A hierarchical-based parallel data mining method for Chinese text. Its characteristic is that it includes the following steps:
[0015] Step 1: Establishment of the Chinese text vector space model: By segmenting the entire Chinese text set, the word segmentation form of each text and the feature entry set containing all the deduplication entries in the text set are obtained, and then each feature entry set is used to count each The term frequency inverse document frequery (TFIDF) of the text is used to establish a text vector space model based on the term frequency inverse document frequency (TFIDF).
[0016] The definition of term frequency inverse document frequency (TFIDF): it refers to an index that a term represents the amount of text information that contains the term. The calculation formula is: TFIDF ij =TF ij *IDF i
[0017] TF ij Refers ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More