

Method for classifying documents in mass document library
A document classification and document library technology, applied in the computer field, can solve problems such as time-consuming and complex document classification, and achieve the effects of improving efficiency, reducing the number of matching times, and simplifying the matching process
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
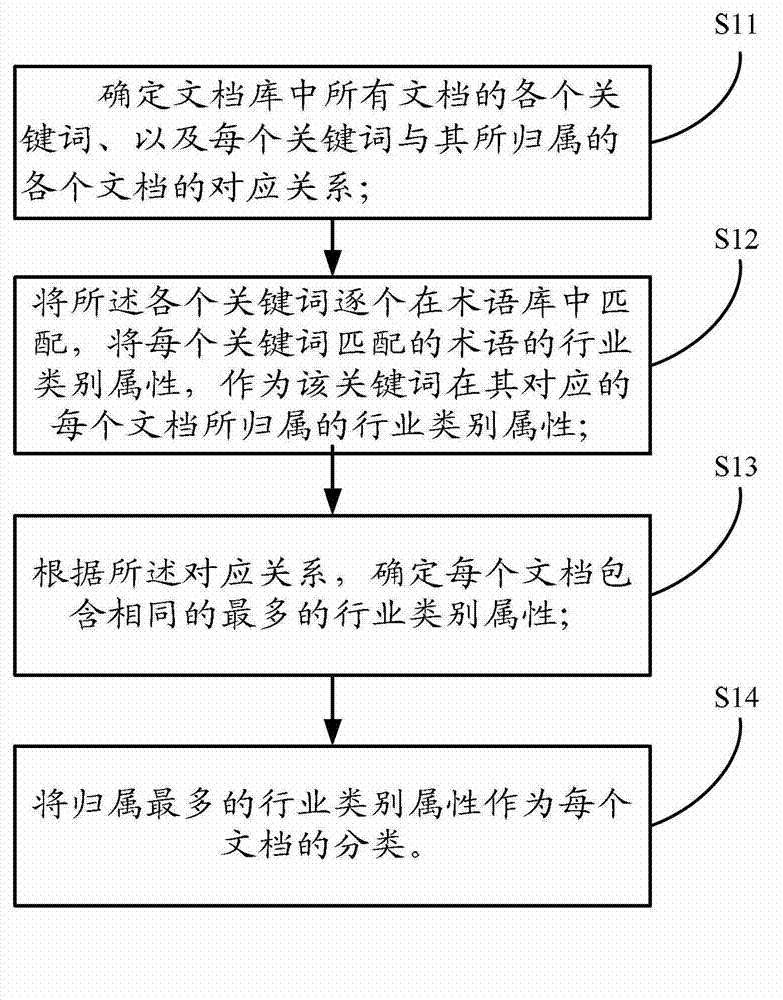
[0017] Hereinafter, the present invention will be described in detail with reference to the accompanying drawings and the embodiments. See figure 1 , The steps of the embodiment include:
[0018] S11: Determine each keyword of all documents in the document library and the correspondence between each keyword and each document to which it belongs;
[0019] S12: Match the keywords one by one in the term database, and use the industry category attribute of the term matched by each keyword as the industry category attribute to which the keyword belongs in each document corresponding to it;
[0020] S13: Determine the same maximum industry category attributes contained in each document according to the corresponding relationship;
[0021] S14: The most industry category attribute is used as the classification of each document.
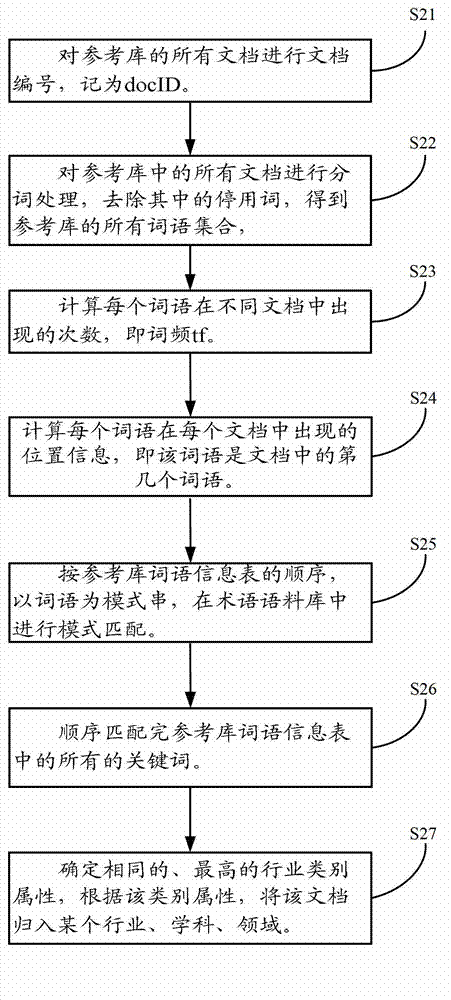
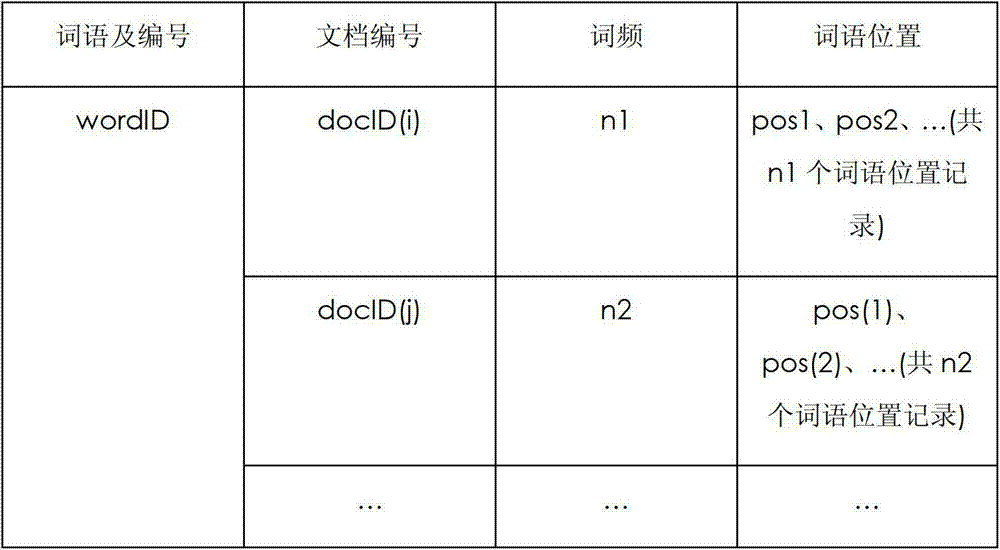
[0022] The present invention adopts a reverse matching idea to perform term search on documents in a reference library, that is, use all words in the reference libra...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More