

Method and device for extracting page information
A technology of page information and extraction method, which is applied in special data processing applications, instruments, electrical digital data processing, etc., and can solve the problems of inability to meet the requirements of accuracy rate and information recall rate, inability to be applied on a large scale, and large labor costs.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
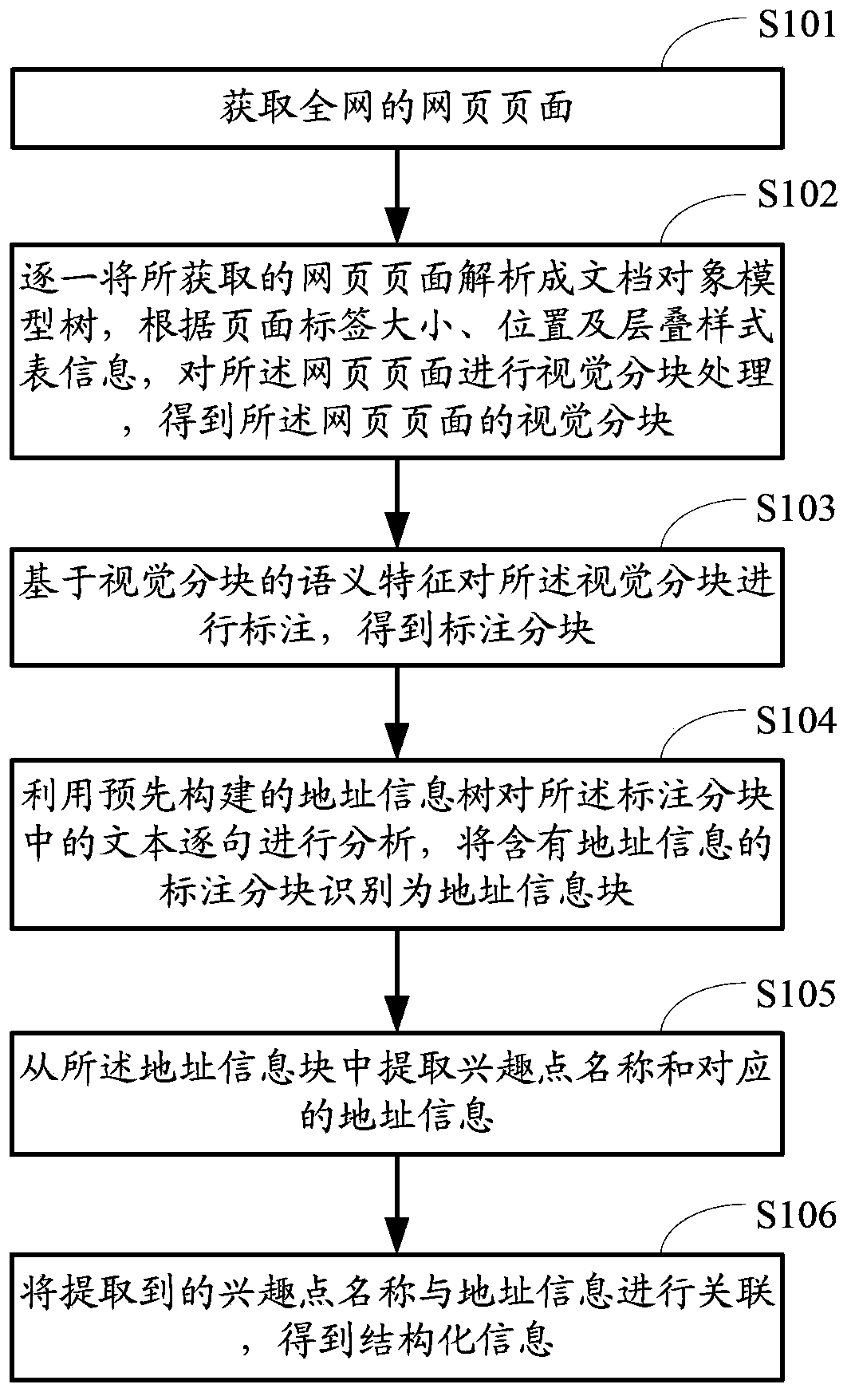
[0109] figure 1 It is a flow chart of the page information extraction method provided in this embodiment, such as figure 1 As shown, the method includes:
[0110] Step S101 , obtaining webpages of the whole network.
[0111] A web crawler is used to crawl webpages on the Internet, at least including URLs and source codes of the webpages. For example, the url address is "http: / / www.hdhospital.com / OverView.aspx", which is a page in the website of Beijing Haidian Hospital. Use a web crawler to grab the web page, record the corresponding url address, and obtain the web page The web page source code (such as HTML code) corresponding to the page.
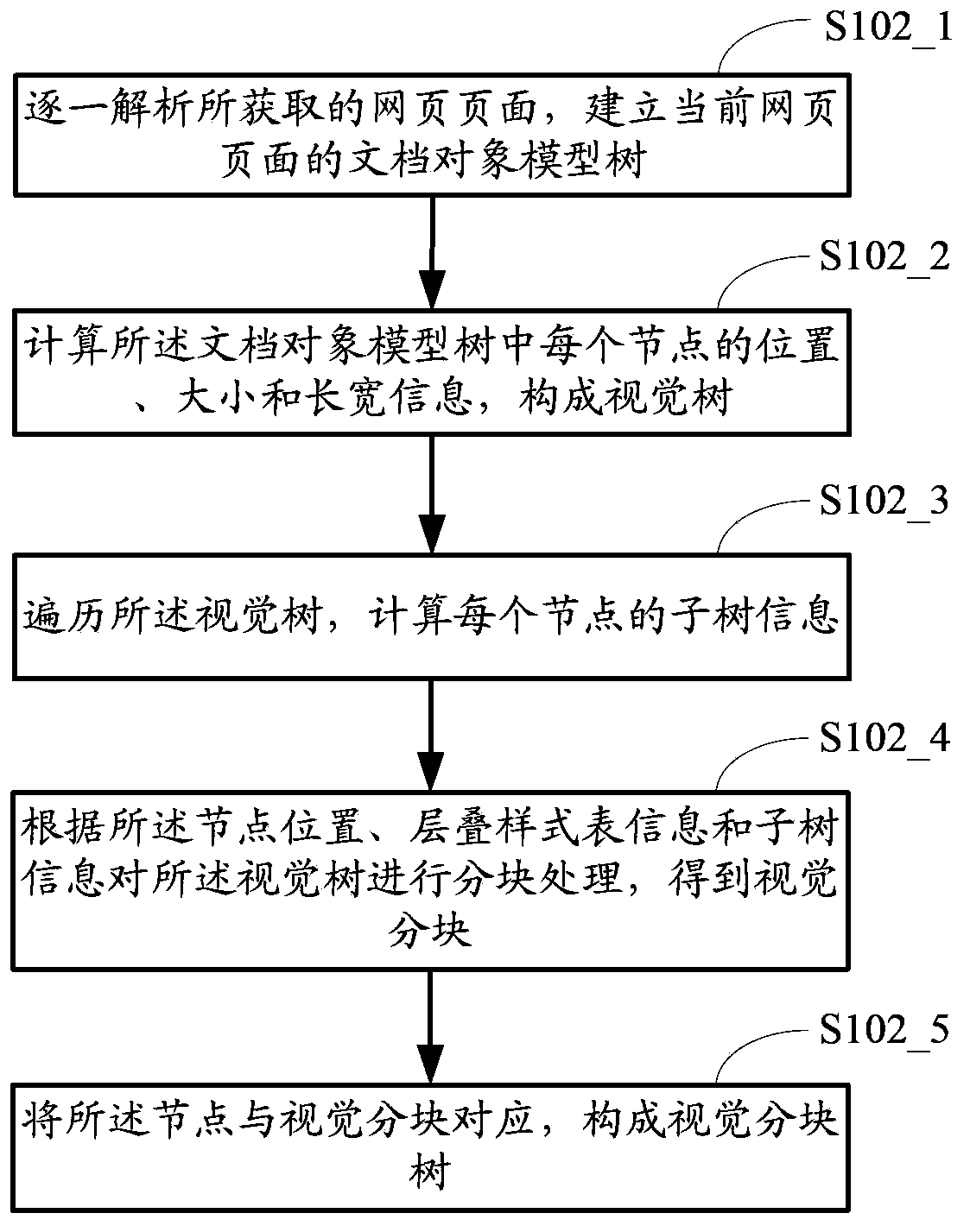
[0112] Step S102 , parse the acquired web pages one by one into a document object model tree, perform visual block processing on the web pages according to the size and position of the page tags and CSS information, and obtain the visual blocks of the web pages.
[0113] The web pages acquired in step S101 are divided into blocks base...
Embodiment 2
[0164] Figure 5 It is a flow chart of the page information extraction method provided in this embodiment, such as Figure 5 shown, including:
[0165] Step S501 , obtaining webpages of the whole network.
[0166] Step S502, analyzing the web pages one by one.
[0167] Analyze the webpages of the whole network obtained in step S501 one by one, and enter step S507 after executing steps S503 to S505, or enter step S507 after executing step S506.
[0168] Step S503 , parsing the web page into a document object model tree, performing visual block processing on the web page according to the size and position of the page tag and CSS information, and obtaining the visual block of the web page.
[0169] Step S504: Label the visual blocks based on the semantic features of the visual blocks to obtain marked blocks.
[0170] Step S505 , using the pre-built address information tree to analyze the text in the marked blocks sentence by sentence, and identify the marked blocks containing...
Embodiment 3
[0210] Image 6 is a schematic diagram of the page information extraction device provided in this embodiment. Such as Image 6 As shown, the device includes:
[0211] The web page acquisition module 601 is configured to acquire web pages of the entire network.
[0212] A web crawler is used to crawl webpages on the Internet, at least including URLs and source codes of the webpages.
[0213] For example, the url address is "http: / / www.hdhospital.com / OverView.aspx", which is a page in the website of Beijing Haidian Hospital. Use a web crawler to grab the web page, record the corresponding url address, and obtain the web page The web page source code (such as HTML code) corresponding to the page.
[0214] The visual block processing module 602 is configured to parse the obtained web pages into a document object model tree one by one, perform visual block processing on the web pages according to the size and position of the page tags and the cascading style sheet information, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More