

A Method of Webpage Incremental Crawling for Effective Link Acquisition
A web page and incremental technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems affecting efficiency, etc., to achieve the effect of avoiding repeated crawling, avoiding crawling, and increasing the frequency of crawling
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0046] In order to better understand the technical content of the present invention, the present invention will be described in detail below in conjunction with the accompanying drawings.
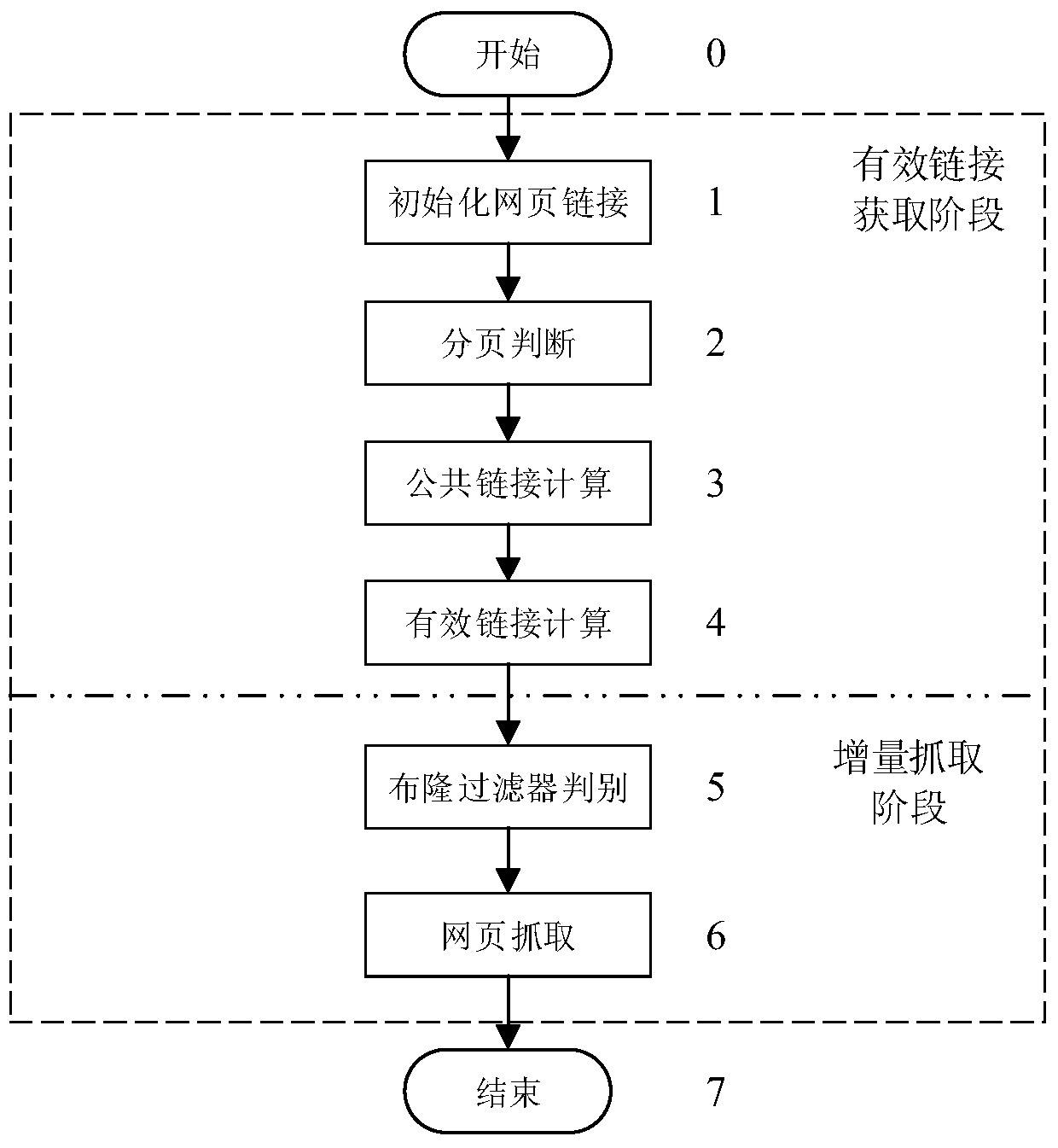
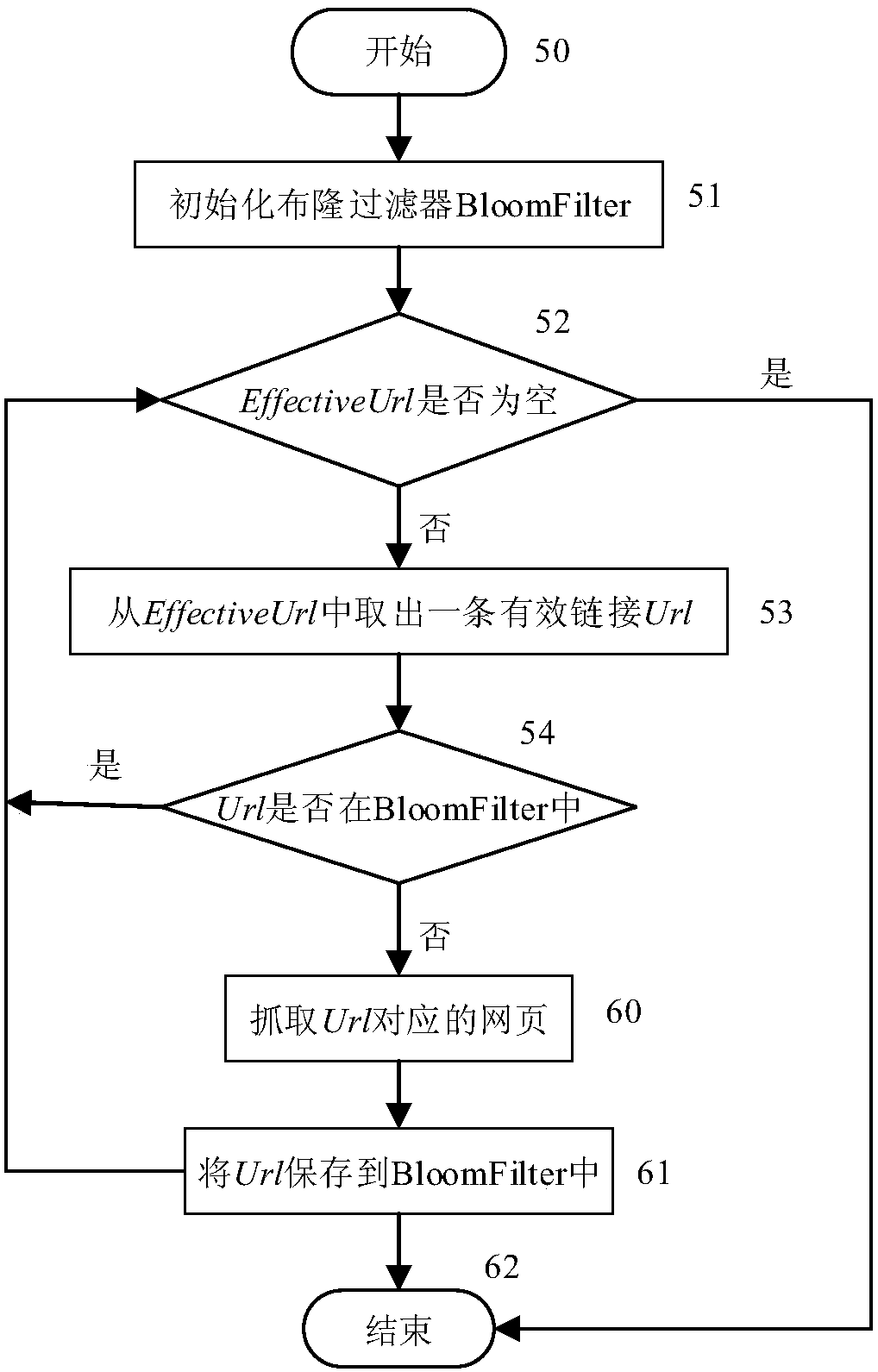
[0047] figure 1 It is a flow chart of an incremental web crawling method for effective link acquisition according to an embodiment of the present invention, which includes two stages: an effective link acquisition stage and an incremental crawling stage.
[0048] Step 0 is the initial state of the present invention;
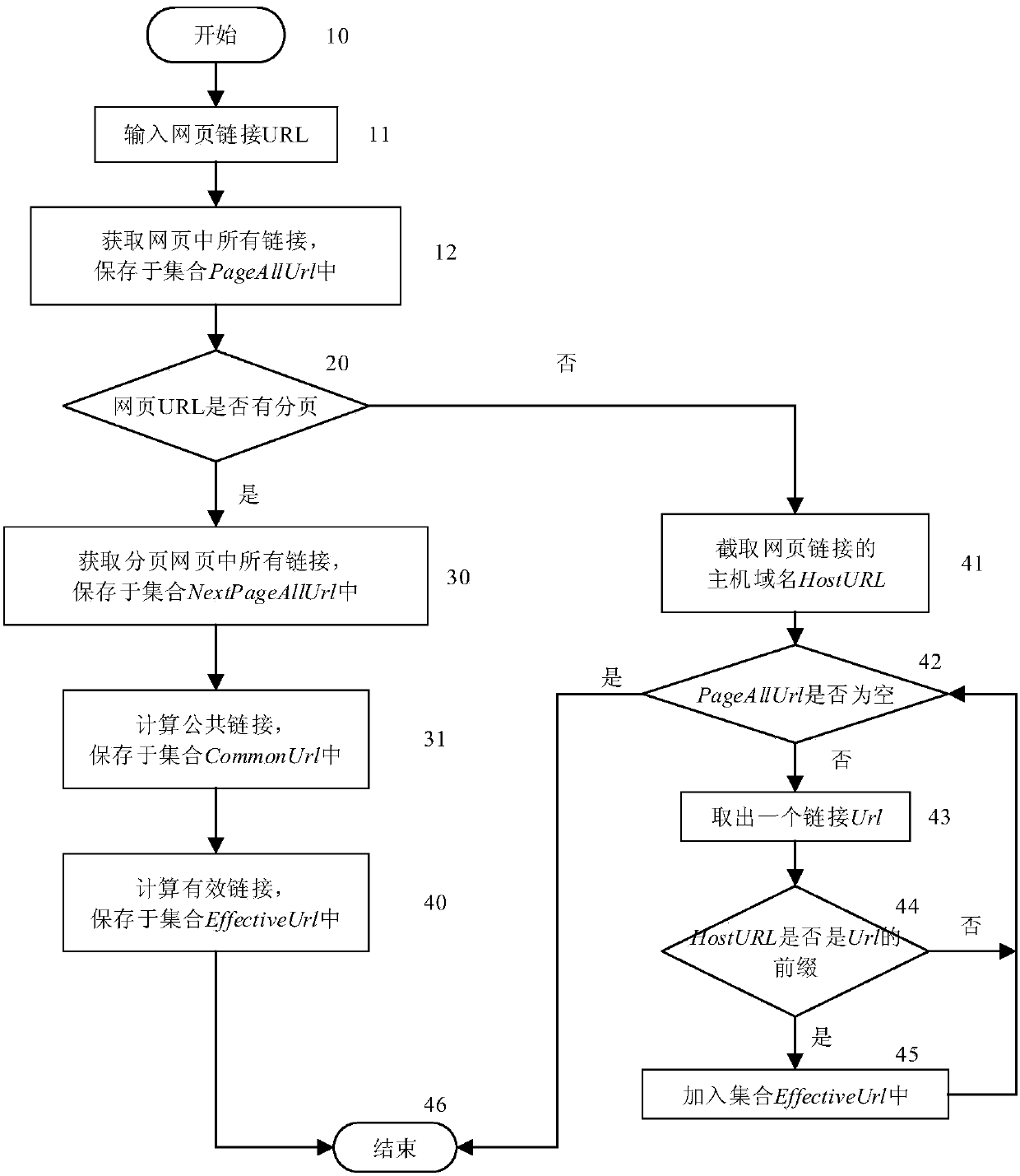
[0049] In the effective link acquisition stage (steps 1-4), step 1 is to initialize the capture of the entry URL link, and the capture program will capture layer by layer from then on;
[0050] Step 2 judges whether there is pagination in each URL link text in the entry URL webpage by matching whether there are paging signs such as "next page" or "next page";
[0051] Step 3 finds out its public link by comparing the link in the entry URL web page with the link in its paging...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More