Speech Synthesis Method and System
A technology of speech synthesis and speech playback, which is applied in speech synthesis, speech analysis, instruments, etc. It can solve the problems of difficult correspondence between acoustic feature sequences and long time delays, and achieve the effect of shortening synthesis time and improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

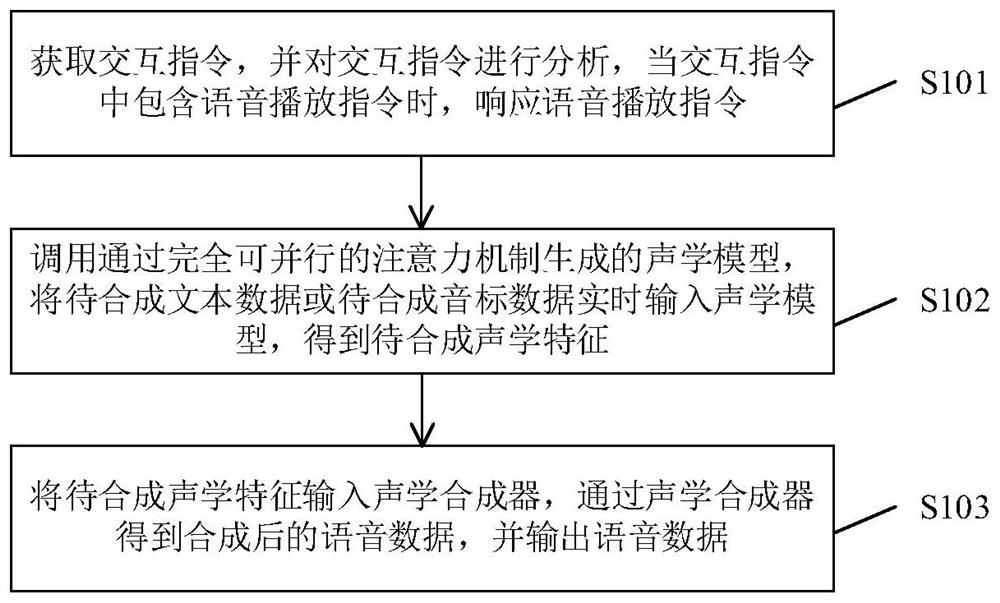
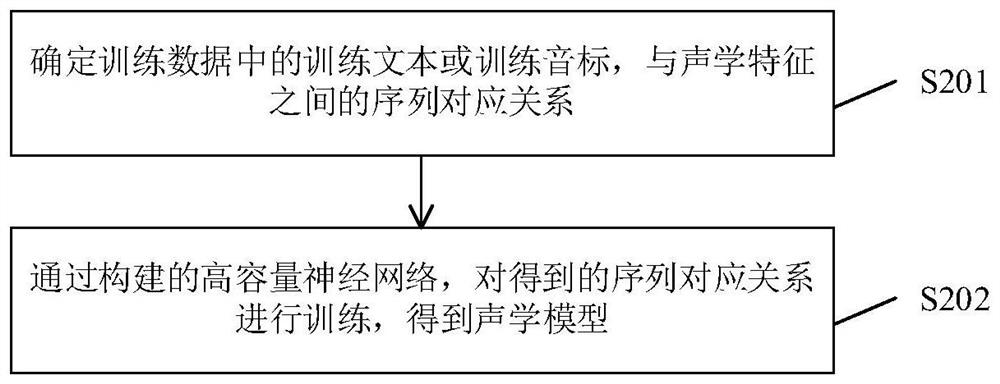
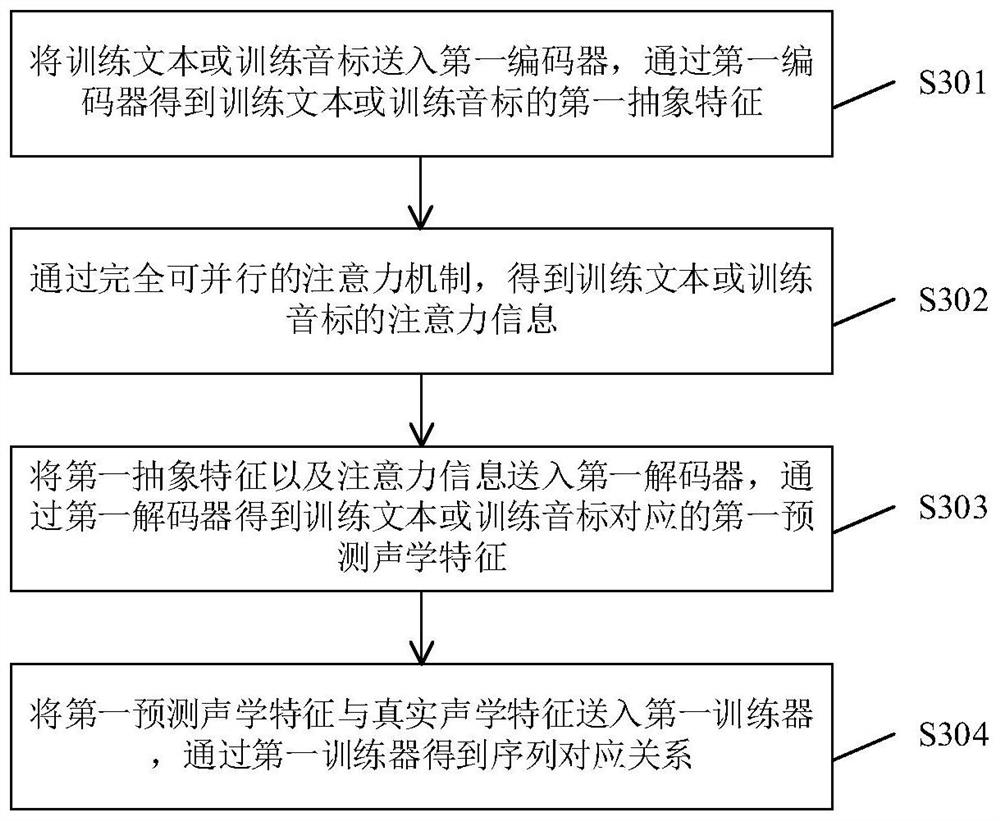
Examples
Embodiment Construction
[0051] In order to make the object, technical solution and advantages of the present invention clearer, the embodiments of the present invention will be further described in detail below in conjunction with the accompanying drawings.
[0052] For clarity of expression, need to carry out following explanation before embodiment:
[0053] The smart device mentioned in the present invention supports multi-modal human-computer interaction, and has AI capabilities such as natural language understanding, visual perception, language and voice output, and emotional expression and action output; it can be configured with social attributes, personality attributes, character skills, etc., so that users can enjoy Intelligent and personalized smooth experience. In a specific embodiment, the smart device may be a story machine, a tablet, a watch, a picture book robot, a humanoid intelligent robot, and the like.
[0054] The smart device obtains the user's multi-modal data, and the server pe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More