

Method of PDF file information extraction system based on XML
A technology for extracting system and document information, which is applied in the field of information transformation, can solve the problems of not seeing the document reports of the PDF document information extraction system, and achieve the effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0013] The workflow of PDF document information extraction system design:
[0014] Design of DTD (Document Type Definition)
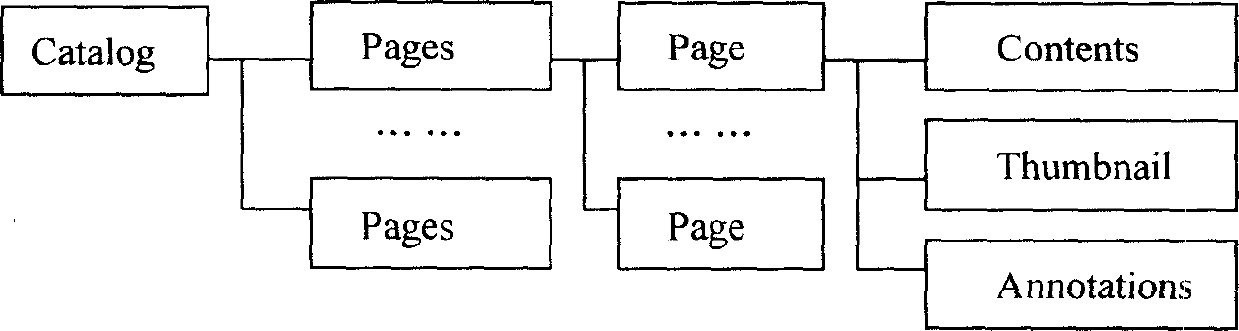
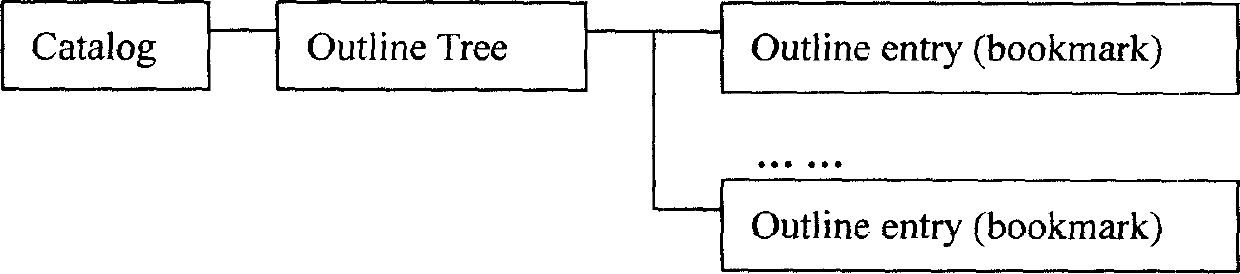
[0015] To better display the semantic information in the PDF document, the first step is to formulate the DTD document that regulates the rules and interrelationships of the elements and symbols in the XML document. We refer to Simplified DocBook, a subset of popular DocBook elements, and analyze and select the following two types of basic information according to the characteristics of chapter structure and terminology of scientific papers:
[0016] (1) External information metadata (Articleinfo): Metadata describing the external characteristics of scientific and technological papers, including author (author), address (author address), edition (publishing), bibliography (references), etc. External information metadata is an important basis for users to conduct information retrieval.
[0017]
[0018]
[0019]
[0020]
[0021]
[0022]
...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More