

High-efficiency text data mining method
A text data, high-efficiency technology, applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve problems such as load imbalance, affecting overall efficiency, affecting computing efficiency, etc., to reduce data volume, avoid overhead, reduce Quantity effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
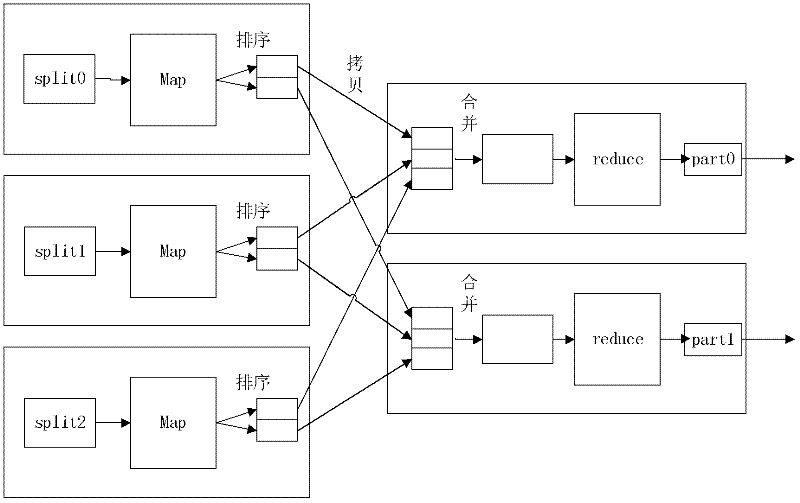
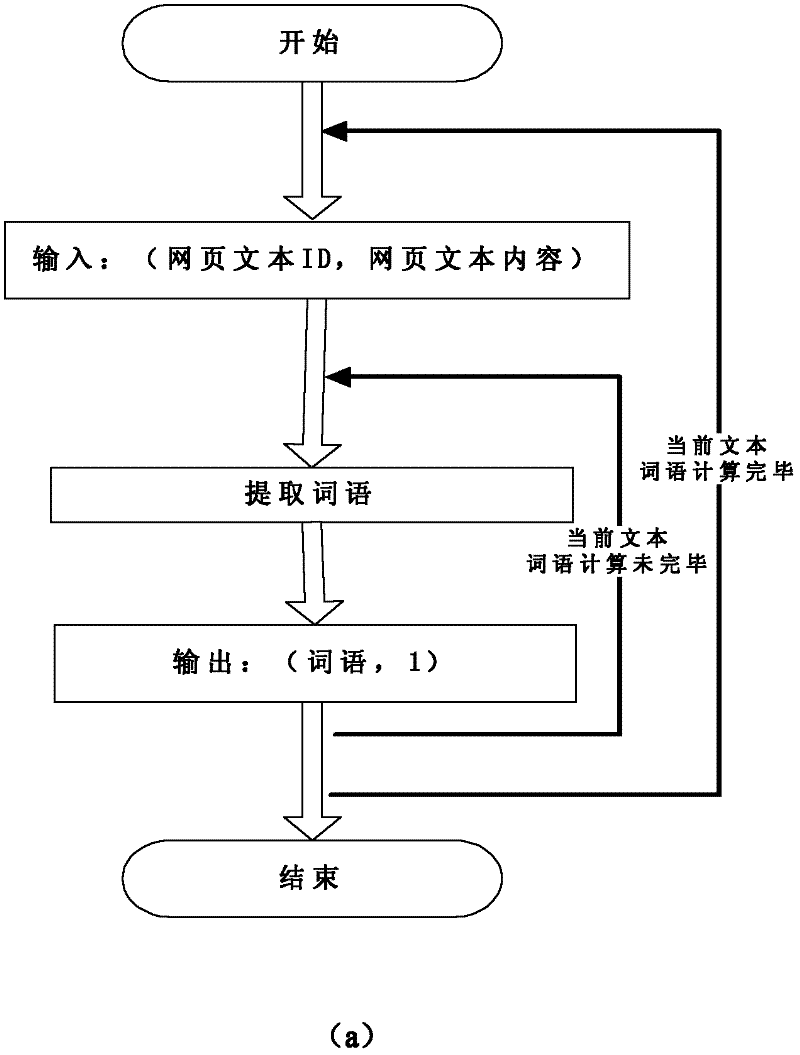
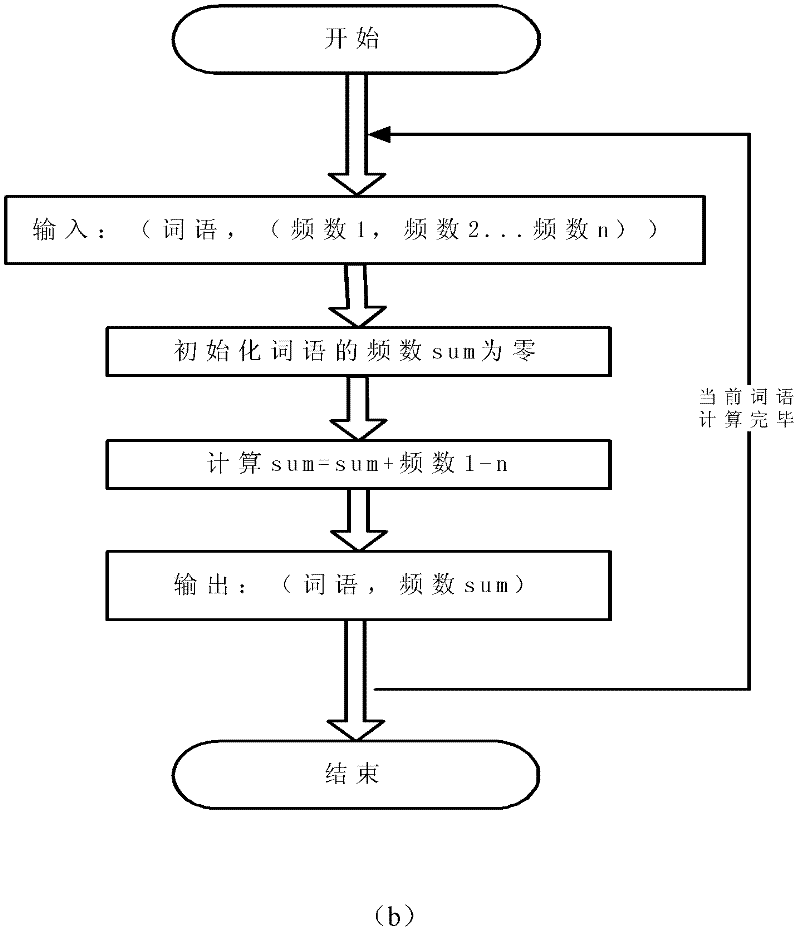
[0042] The specific implementation of the present invention will be further described below by taking the extraction of keywords based on the calculation of the frequency of words in the webpage text as an example. The concrete implementation of the present invention is based on above-mentioned Hadoop system.
[0043] 1. File preprocessing (Preprocess) (such as Figure 4 shown)
[0044] (1) The work at this stage is completed before the frequency calculation starts, and it is realized through custom modification based on the Archive tool in Hadoop.
[0045] (2) Suppose the number of webpage text files to be processed is n (each file has an id as a mark), the maximum number of Map tasks configured in the Hadoop system to run simultaneously is m, and the maximum number of Map tasks configured in the Hadoop system to run simultaneously is m. The number of Reduce tasks is r; at the same time, set the adjustment coefficient k1 to an integer between 5000 and 10000 (assuming that t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More