

Webpage information extraction method
A technology of webpage information and implementation methods, which is applied in the directions of instruments, computing, and electrical digital data processing, etc., and can solve problems such as poor quality, rough granularity of candidate attributes, and low accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
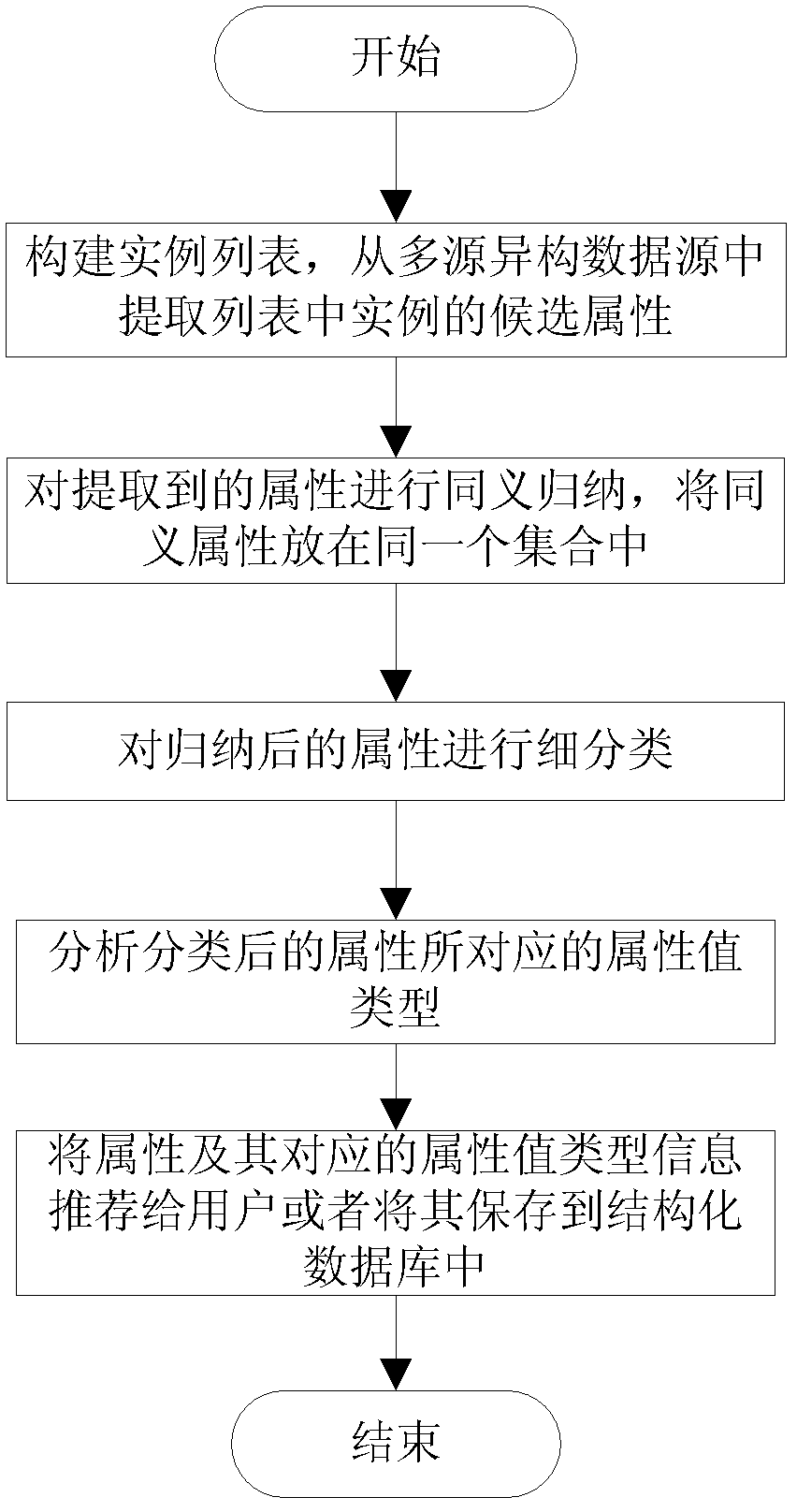
[0041] Assume that all attributes of the concept "star" need to be extracted, and the input is a list of target instances of the concept "star", that is, a collection of stars such as Andy Lau and Zhang Ziyi. First, extract the candidate attributes corresponding to the concept instance list from various network encyclopedia data sources, and the attribute values corresponding to these attributes; then use these attribute value information to conduct synonymous induction on candidate attributes, find out attributes with similar meanings and Merge them together; then use web resources to evaluate the candidate attributes, and select the attributes that are closely related to the target concept; finally, analyze the attribute values of the attributes and predict the type of attribute value corresponding to each attribute. The following is a detailed description of each specific step (for the process, see figure 1 ).
[0042] A. Build an instance list and extract candidate at...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More