

A method and device for web page information update discovery and statistics
A web page information, web page technology, applied in computing, special data processing applications, instruments, etc., can solve the problems of inability to track statistics of news sources, inability to obtain new news sources, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
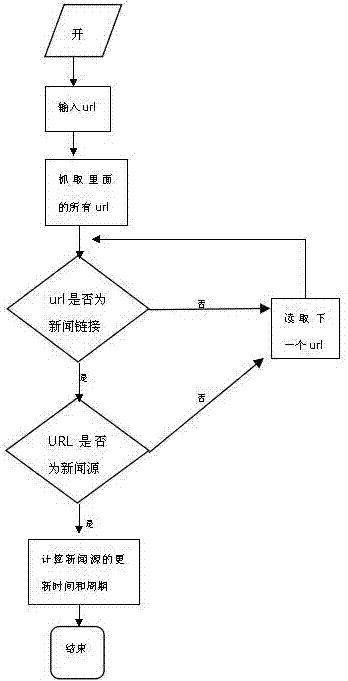
[0034] Referring to the accompanying drawings, a method for web page information update discovery and statistics, the steps are as follows:
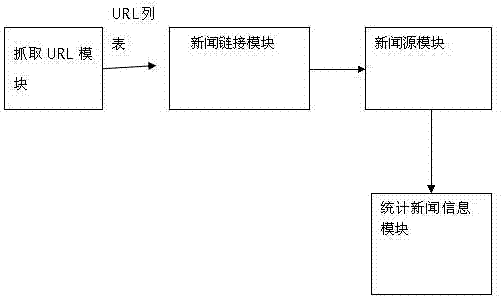
[0035] (1) Grab and input the total domain name to be searched by grabbing the URL module, such as: the steps of www.news.baidu.com;
[0036] (2) The news link module determines whether the webpage link is the step of the news link, if it is then proceeds to step (3), otherwise proceeds to the step (1), the step of judging whether the URL is the news link is as follows:
[0037] (21) Judge whether the captured web page link address string (www.news.baidu.com) contains the "news" keyword by regular expression matching, if so, go to step (22), otherwise continue to judge and record number of links;
[0038] (22) Grab the webpage interface it points to through the webpage link, and judge whether all the ch...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More