

A D2D user resource allocation method based on a deep reinforcement learning DDPG algorithm
A technology of reinforcement learning and allocation method, applied in the field of D2D user resource allocation based on deep reinforcement learning DDPG algorithm, can solve problems affecting user performance, user interference, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
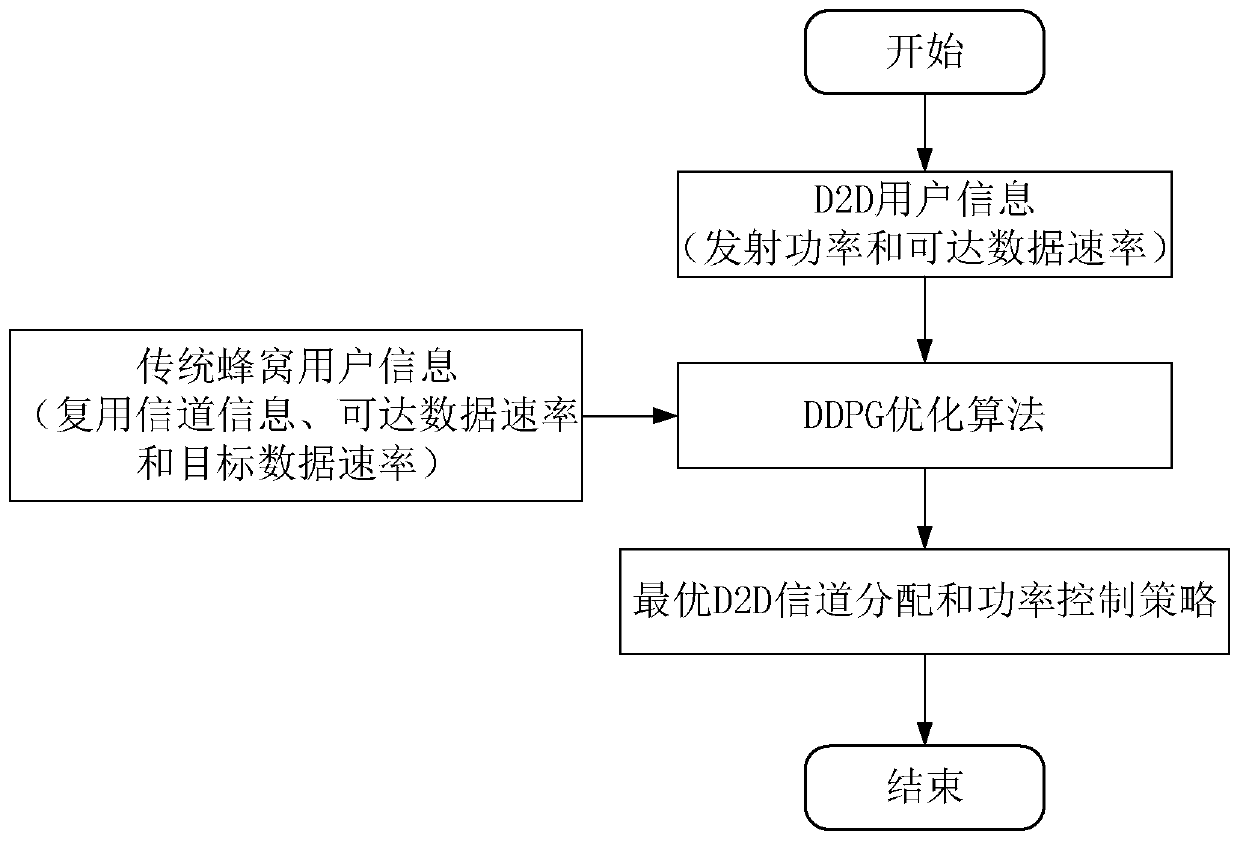
[0062] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
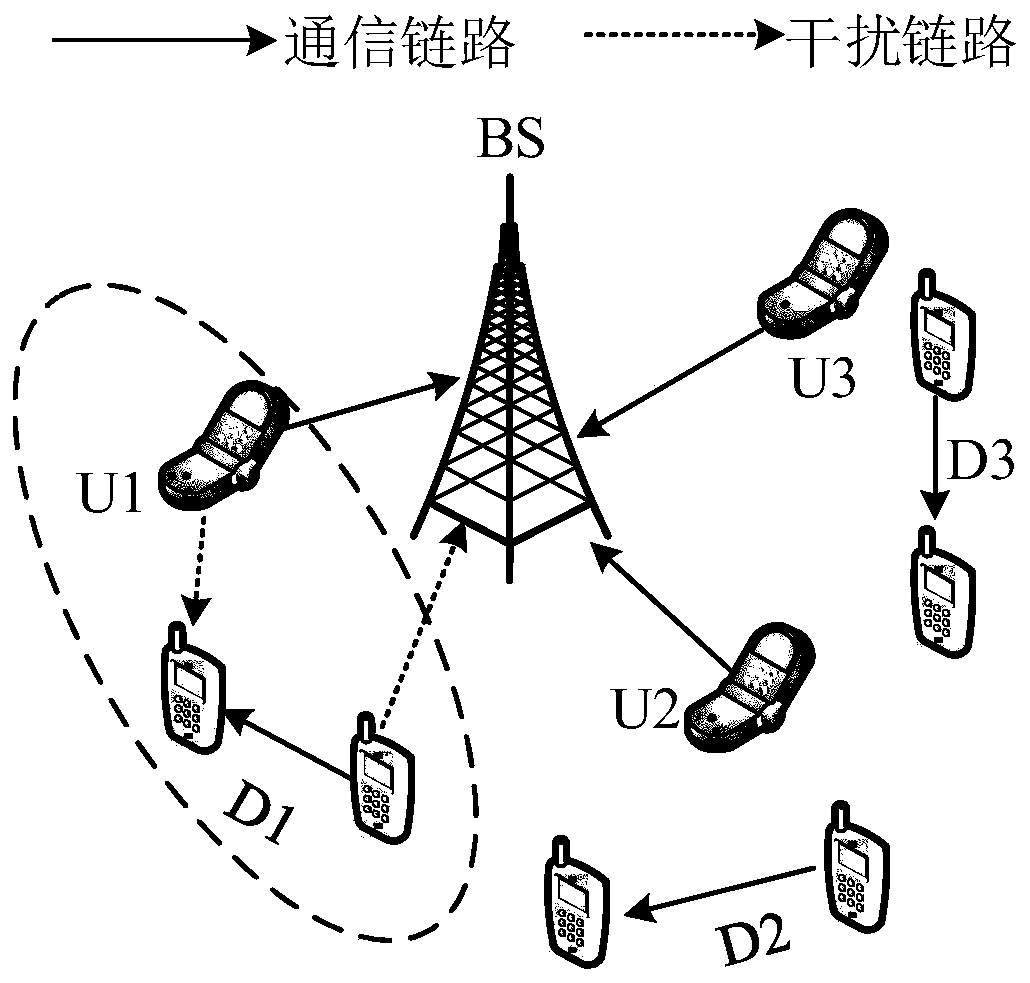
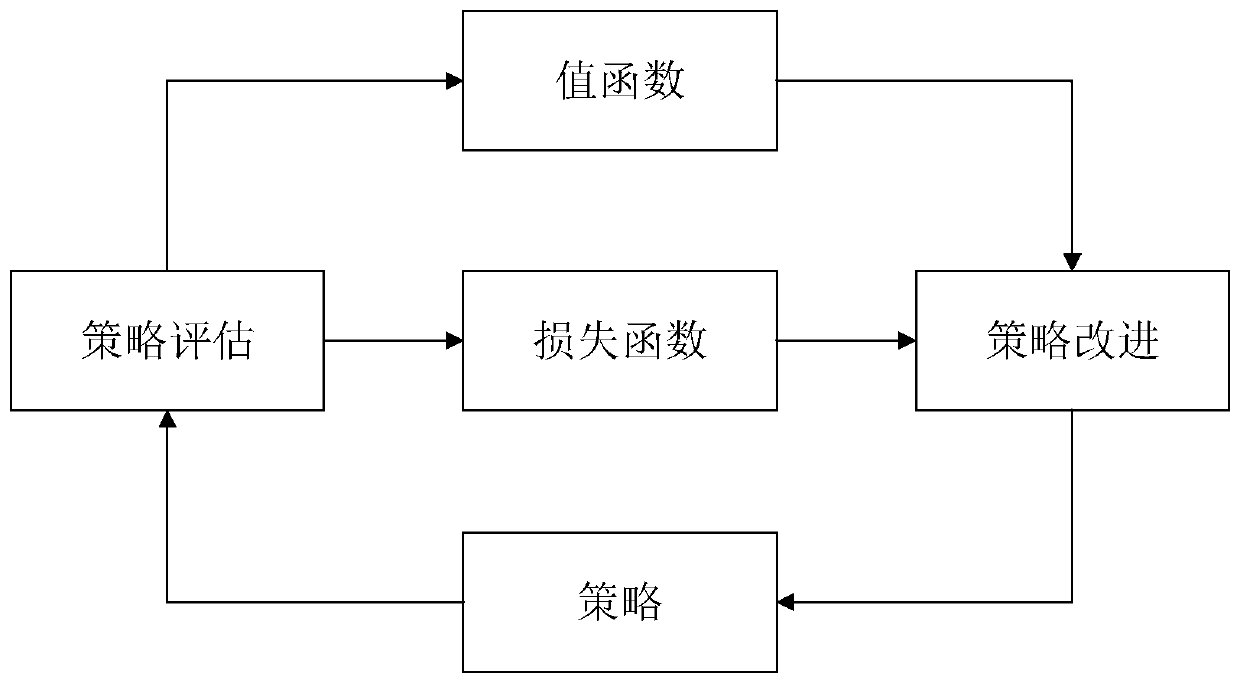
[0063] The object of the present invention is to maximize the information rate of D2D users and improve spectrum utilization without affecting the service quality of cellular users by jointly optimizing the transmission power and channel allocation strategy of D2D users. Using the deep learning method to apply the AC-based DDPG algorithm framework to the system model, the optimal D2D user power control and channel allocation strategy can be obtained, that is, in the cellular network, a set of optimal D2D user pairs can be obtained. Optimal transmit power and shared channel information make it possi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More