

A Book Retrieval Method Based on Feature Extraction
A feature extraction and book technology, applied in the field of network communication, can solve the problems of inability to meet the reading needs of users, large time cost and manpower investment, and unfavorable selection of readers, so as to increase the reading experience, save frequent queries, and facilitate reading. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

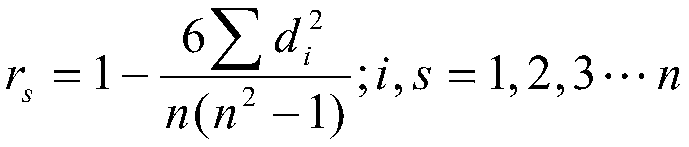
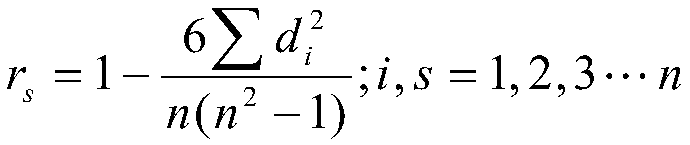
Examples
Embodiment 1
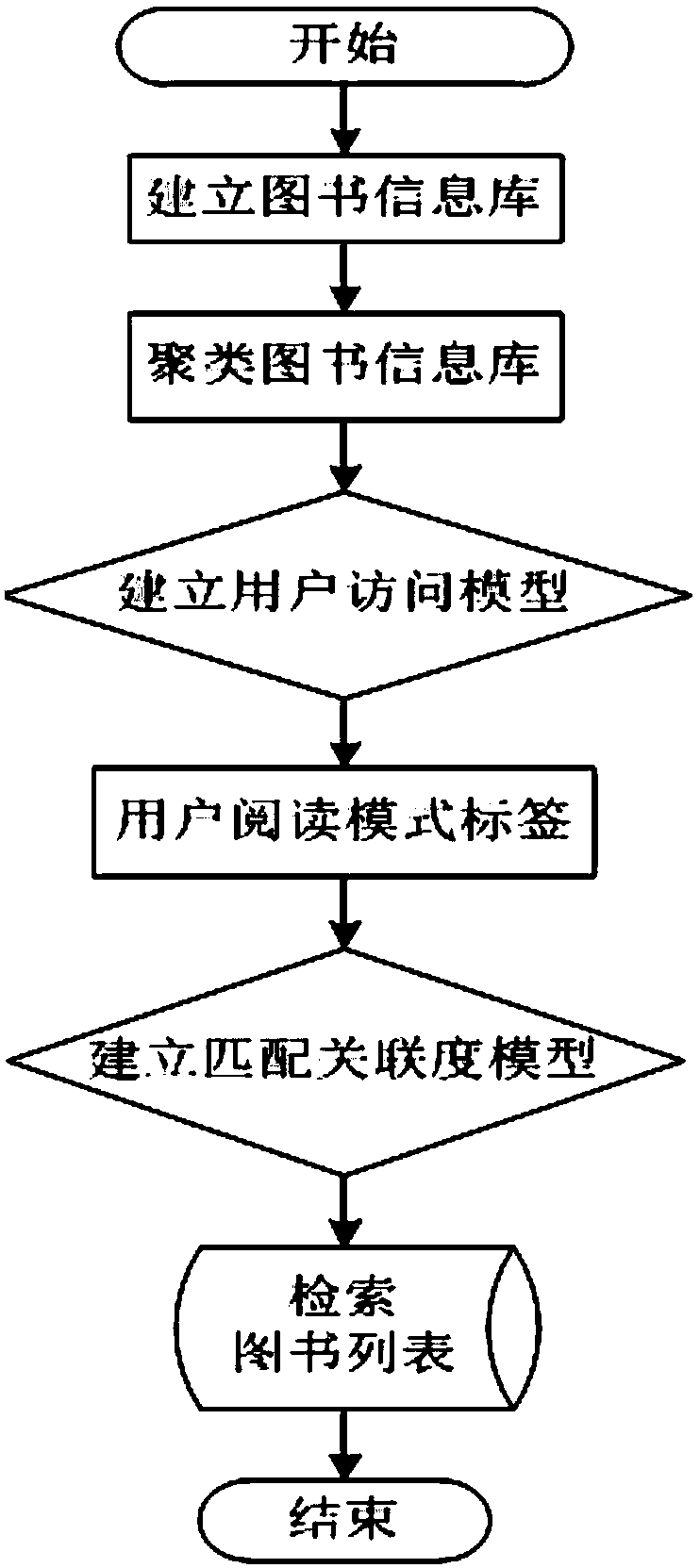
[0026] Embodiment 1: as figure 1 Shown:
[0027] Step1: Establish a book information library: collect data on the book information in the library, extract book label information, including book title, book field and book publishing information, and code and identify the collected books according to [field-name-publishing] Store in the form of Publishing House-Publication Date], such as [Economic Management-Crazy Economics-Nanhai Publishing House-September 2013].
[0028] Step2: Establish a clustered book information library:
[0029] Step2.1: Bookmark clustering:
[0030] 1. First, integrate the bookmark information stored in sequence according to the code, and use the Spearman rank correlation coefficient method to establish the correlation coefficient between the book label sequence information, and define the calculation formula of the clustering reference coefficient as:
[0031]
[0032] Among them, r s is Spearman's correlation coefficient value, n is the sample s...
Embodiment 2
[0042] Embodiment 2: as figure 1 As shown in the figure, a book retrieval method based on feature extraction, first collects data for book information in the library, extracts book label information, performs code identification, establishes a book information database, and stores book information; secondly, collects books based on book label information elements. category, classify the clustered books as the original library source for retrieving books, and combine the original book tags to reorganize the book features, extract new feature phrases of each category of books, and use them as the clustered book information library; then, extract the user The frequency of accessing books falling into a certain category in the clustered book information base is used to establish a user access model to form a user reading pattern label as a user feature label value; finally, a matching correlation model is established to provide a list of retrieved books for successful matching user...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More