

Webpage information processing method and device
An information processing method and webpage information technology, which are applied in the field of webpage information processing methods and devices, and can solve problems such as time-consuming
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
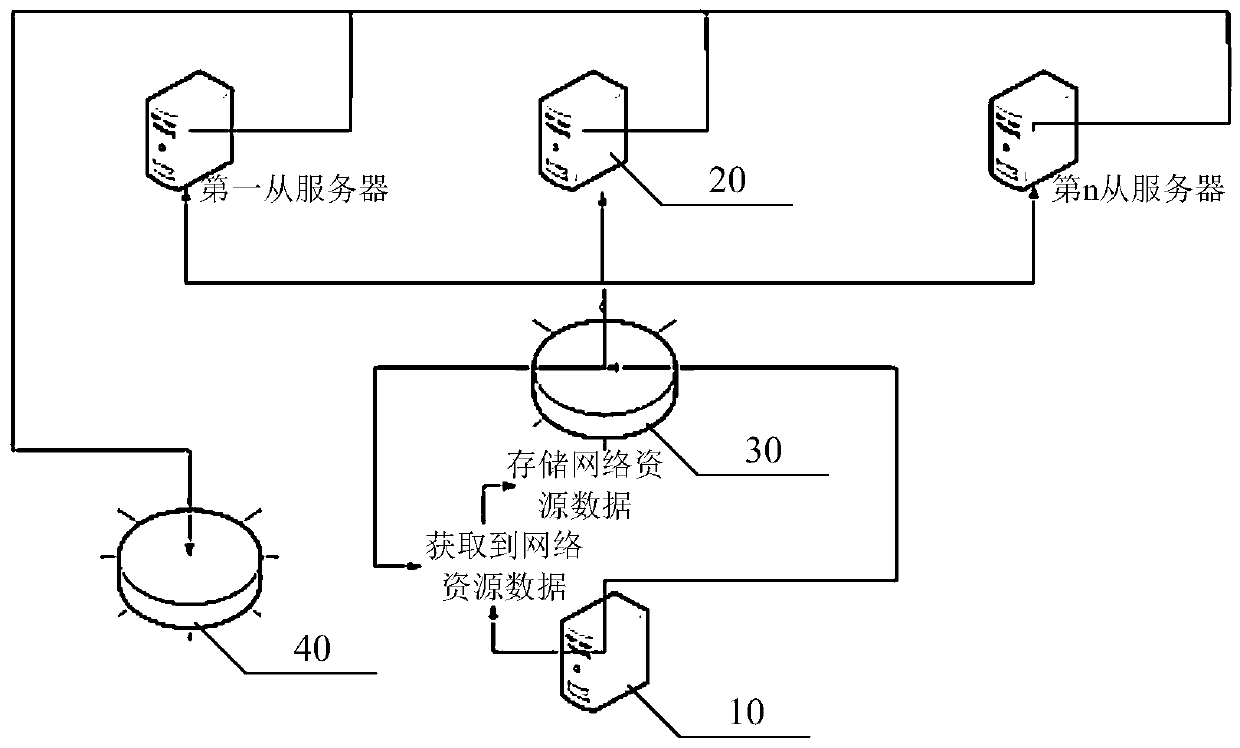
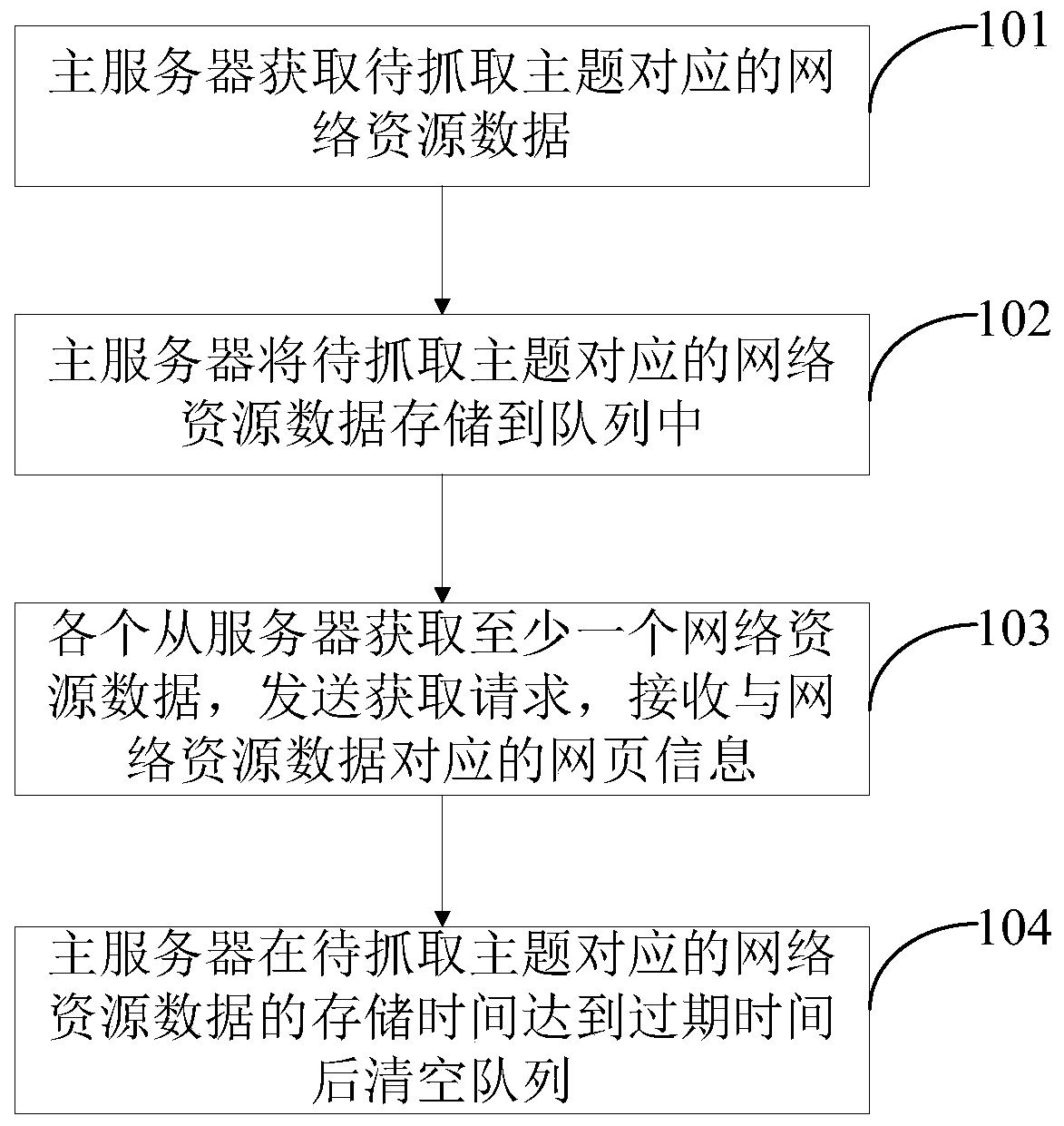
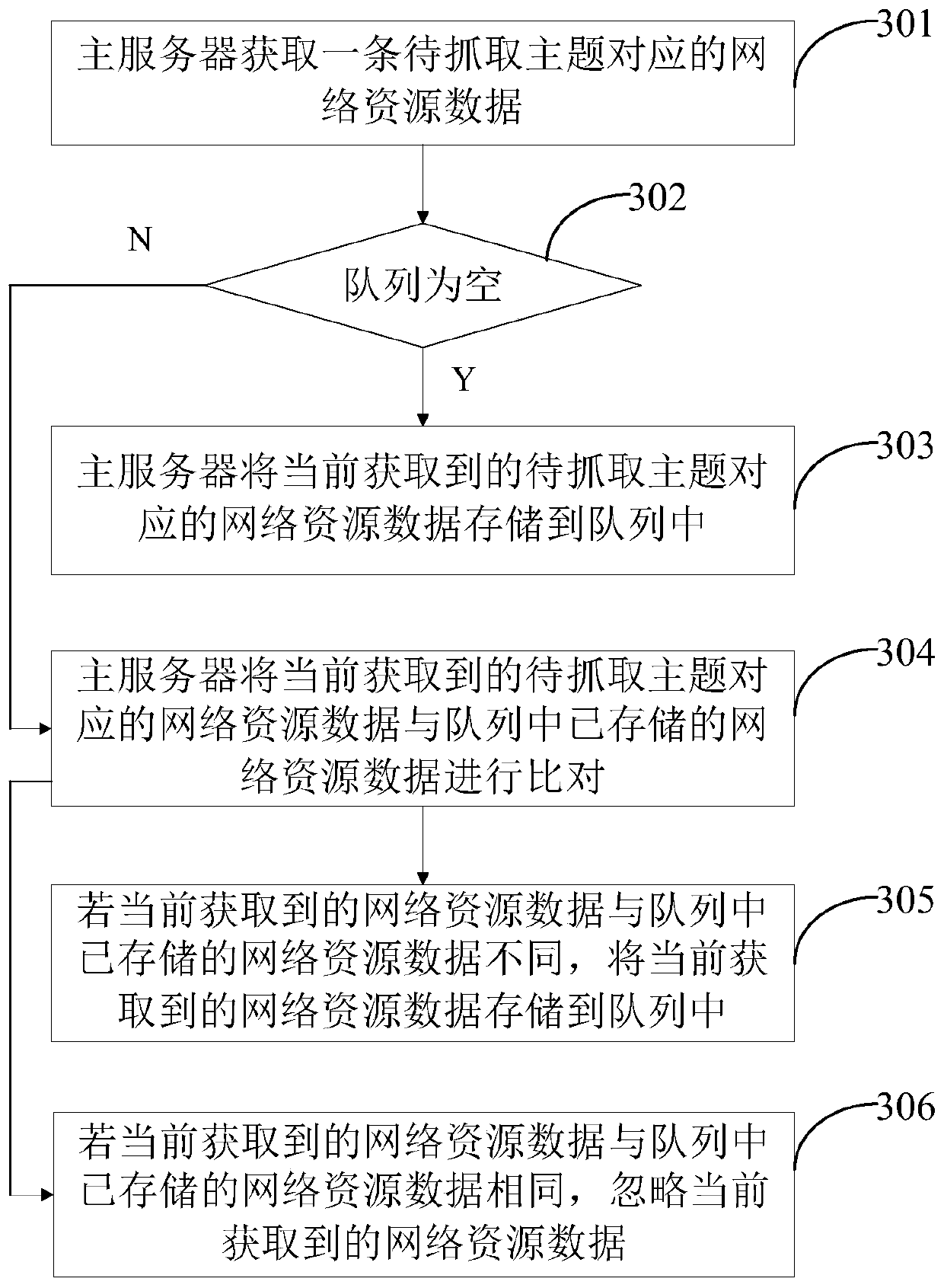
[0054]At present, webpage information can be grabbed based on network resource data (such as the above-mentioned URL) by a single server, but the amount of webpage information is huge, and it will take a lot of time to grab it by a single server. For this reason, this embodiment provides a distributed webpage information crawling system, the architecture of the distributed webpage information crawling system is as follows: figure 1 As shown, it may include: master server 10, each slave server 20 ( figure 1 Take the first slave server to the nth slave server as an example for illustration), the queue 30 and the database 40.
[0055] Wherein the master server 10 is used to determine the network resource data corresponding to the subject to be captured, the subject to be captured can be designated by the user, after the network resource data corresponding to the subject to be captured is stored in the queue 30, each slave server 20 starts from the standby state Change into the w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More