

Data collecting method and system based on HTML stream processing
A data acquisition and HTML document technology, applied in transmission systems, electrical digital data processing, special data processing applications, etc., can solve the problems of unable to determine the download range and format storage of information that users need, low efficiency, etc., to achieve operating costs Inexpensive, easy to maintain, and captures a wide range and type of effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
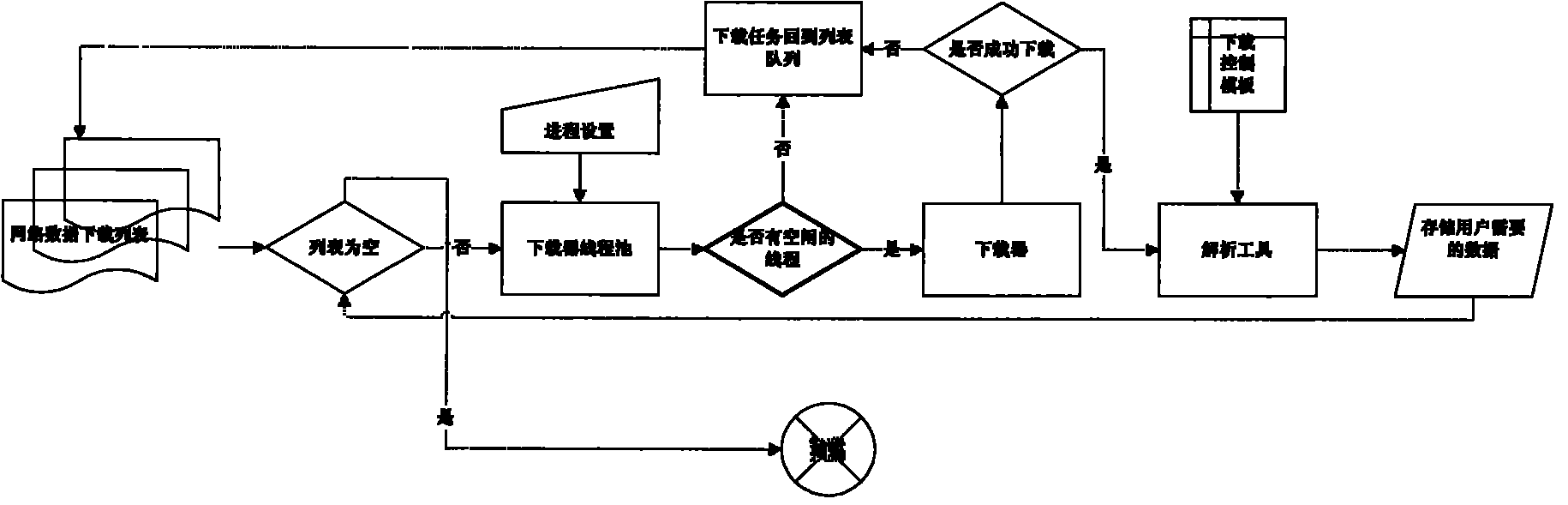
[0039] Take "http:www.youku.com / v" as an example to test the source entry of the collected pages, first configure the root entry of the download control template (see figure 2 Shown), set in the fixed-format xml document.
[0040] The user downloads the control template according to the storage data he needs to set. This template indicates which data needs to be stored by the system. The content that the user needs to store is the title of each video, the link of the page, the description and the publication. time as an example, configure the download control template for stored data (see image 3 , this figure is a part of the configured template, which is an instance of the nodes introduced in Table 1).
[0041] The parser works by reading the HTML stream and image 3 Download the content of the stored data in the control template, analyze the data required by the user, and store it in the data storage system. Figure 4 is the result stored in the database.
[0042] The...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More