

Webpage data capturing and filtering method
A web page data and filtering method technology, which is applied in the fields of electronic digital data processing, special data processing applications, instruments, etc., can solve the problems of unrealistic update speed, huge daily data update volume, and unpredictable massive website crawling, etc. Accurate data capture and filtering, avoiding the effect of production and post-maintenance work
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0040] The present invention will be further described below in conjunction with the accompanying drawings and embodiments.
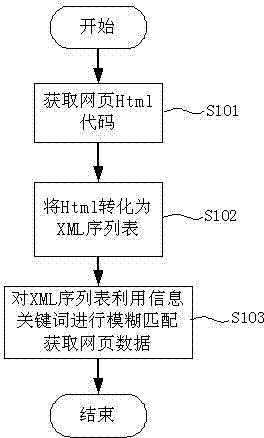
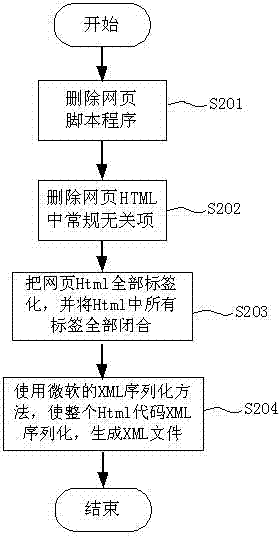
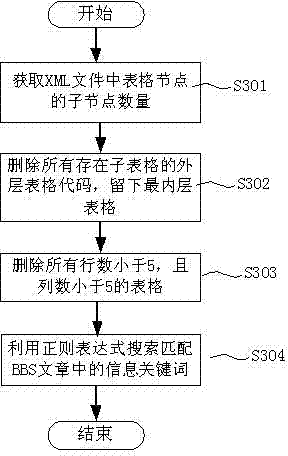
[0041] figure 1 It is a schematic flow chart of the webpage data grabbing and filtering method of the present invention; figure 2 For the present invention, Html is converted into a schematic flow diagram of an XML sequence listing; image 3 Obtain a schematic diagram of the data flow in the BBS article for the present invention.
[0042] See figure 1 , the implementation process of the present invention is described in detail below with grabbing the web page data in the BBS article as an example:
[0043] Step S101: Obtaining the Html code of the webpage
[0044] First use the OpenRead (+URL) method of WebClient in C#.NET to read all the Html codes of a forum article list.
[0045] Step S102: Serialize Html to XML
[0046] Please continue to see figure 2 , as shown in step S201, first delete all the basic irrelevant codes in the overall Html c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More