

Volume radio direction finde (RDF) data distribution type query processing method based on Hadoop
A distributed query and processing method technology, applied in the field of distributed query processing, can solve the problem of low query efficiency of massive RDF data, achieve the effect of alleviating pressure and improving query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

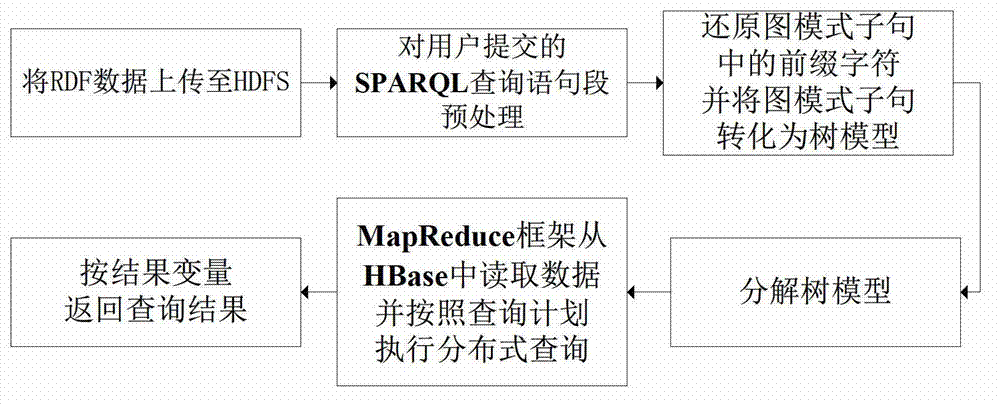
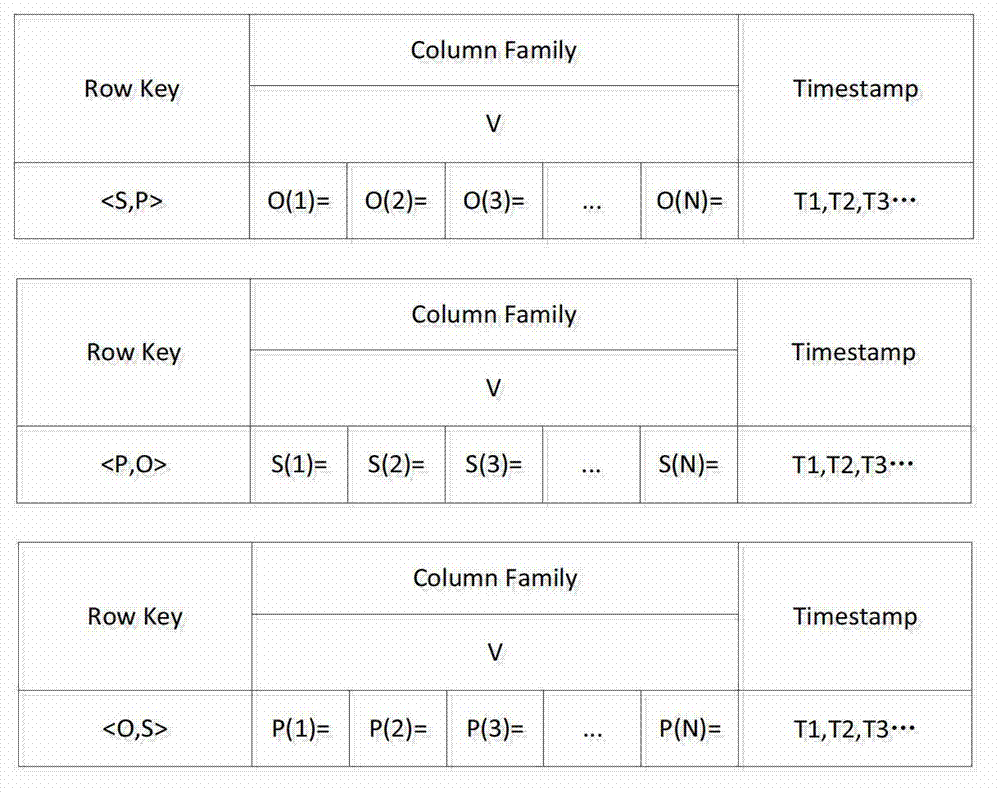
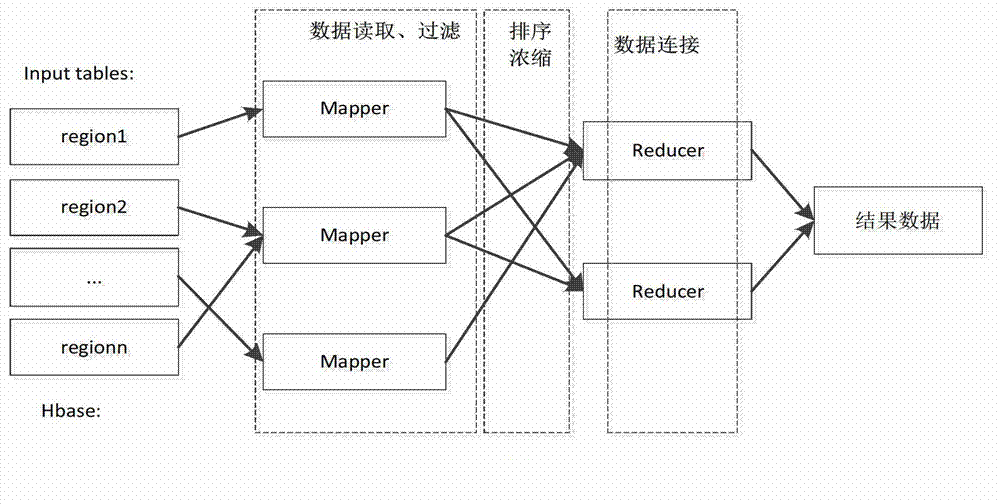
Examples
Embodiment
[0049] The RDF data set used in this embodiment is the standard data set provided by SP2Bench and the standard SPARQL query statement. SP2Bench is an open source public testing platform for SPARQL queries. It provides an RDF standard dataset generator and multiple complex SPARQL standard statements. The standard dataset generator provided by SP2Bench can generate datasets of any size, and the generated data is stored in N3 format files. The SPARQL statement provided by the SP2Bench platform is more comprehensive, including various operators such as Optional and Union.
[0050] 2 master nodes and 8 slave nodes are used to build the Hadoop platform. The two master nodes are respectively used as namenode / jobtracker nodes, configured as 2-core Intel Pentium4CPU, 2GB memory, and 80GB hard disk; 8 slave nodes are used as datanode / tasktracker nodes, and the configuration It is 2-core Intel Pentium4CPU, 1.5GB memory, 80GB hard disk. Comparing the currently popular Semantic Web fram...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More