

Method and device for extracting contents of bodies of web pages
A text and webpage technology, applied in the field of webpage text content extraction, can solve the problems of low efficiency of webpage text content extraction, and achieve the effect of improving accuracy, improving efficiency, and strong versatility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] The specific embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings, but it should be understood that the protection scope of the present invention is not limited by the specific embodiments.
[0034] The basic principles of the technical solution of the present invention:
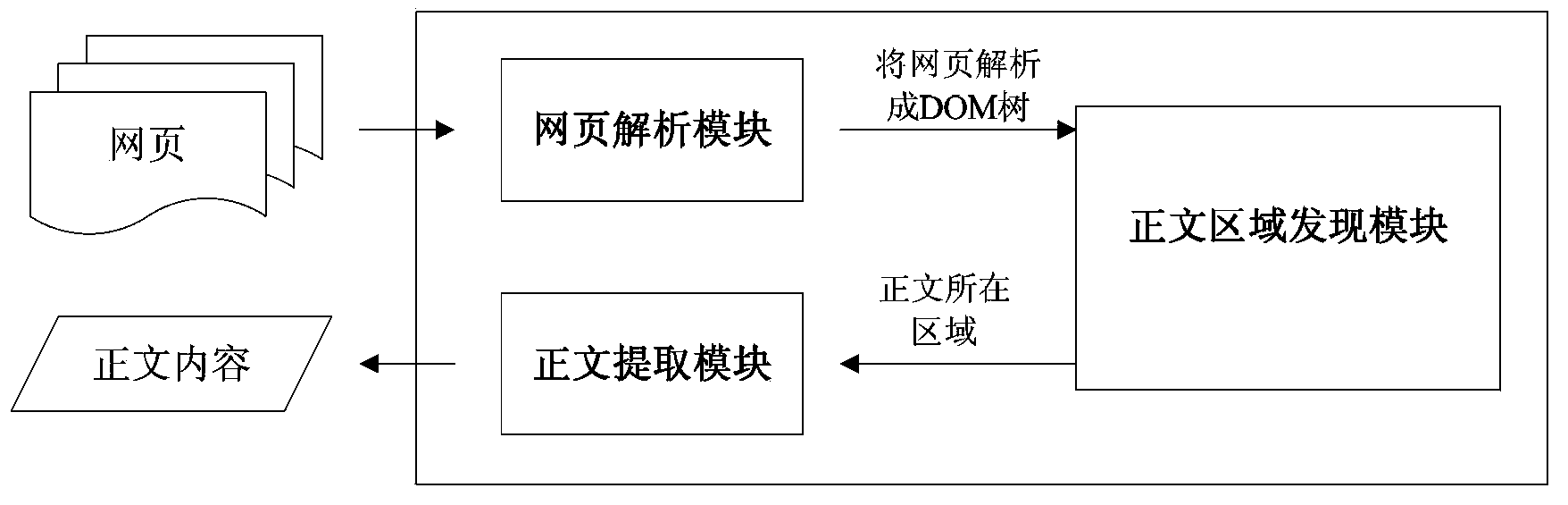
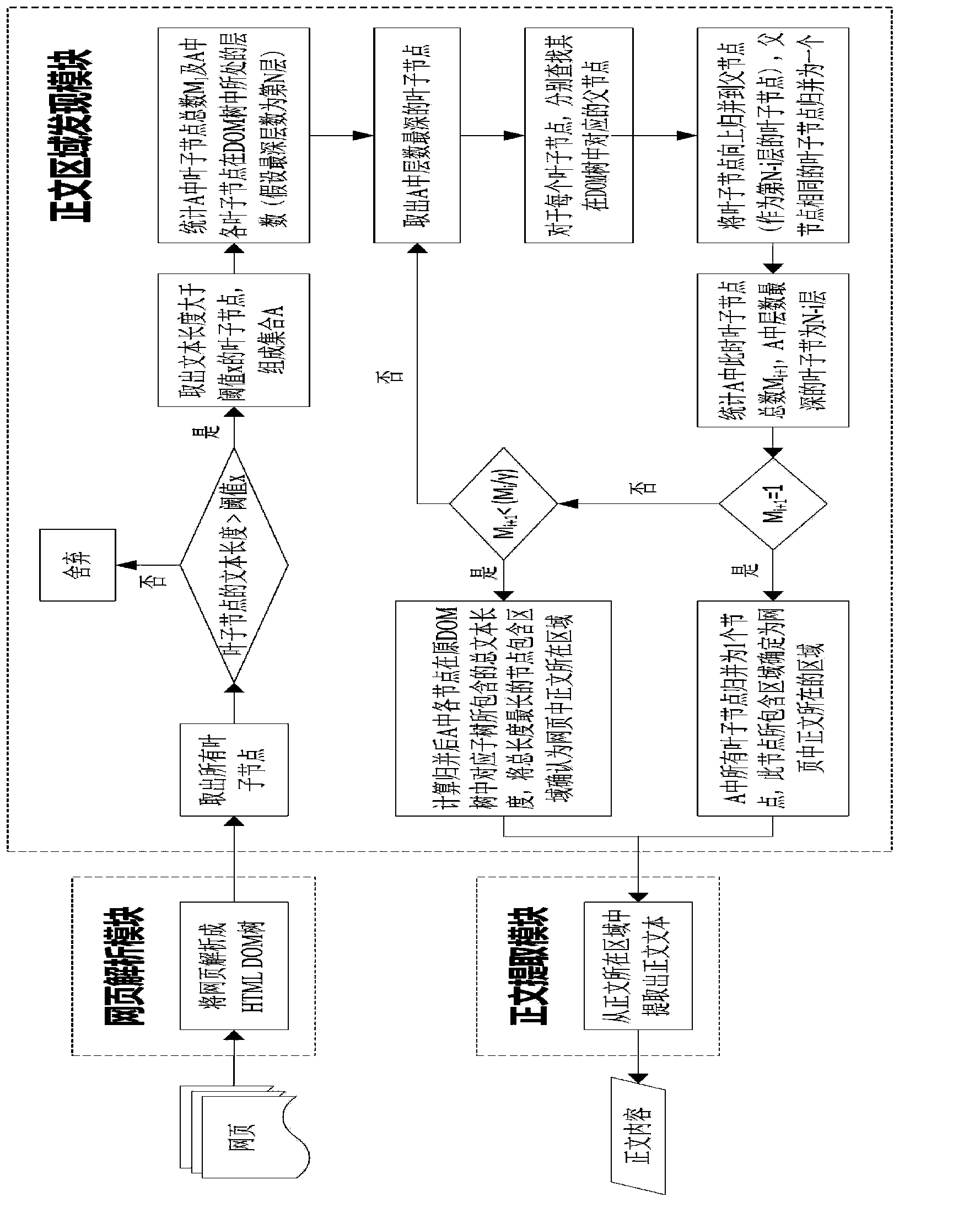
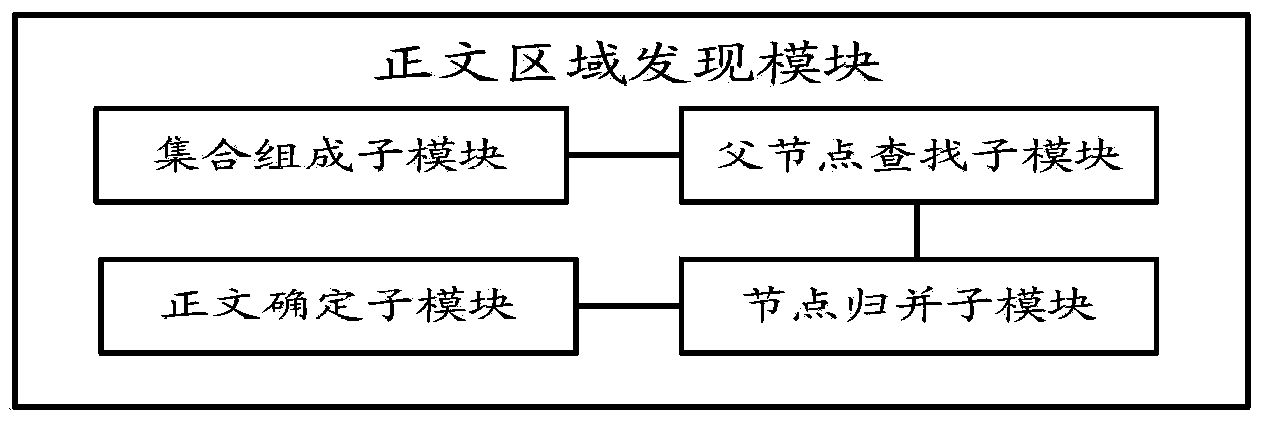
[0035] (1) The web page text content extraction method and device provided by the present invention are based on the HTML DOM tree, DOM is the abbreviation of Document Object Model (Document Object Model), and the analyzer based on DOM converts web page documents into a set of object models (in the form of nodes Tree form representation, called DOM tree).
[0036] (2) According to the characteristics of the DOM tree, it can be seen that the text must be distributed on the leaf nodes of the DOM tree, but not all leaf nodes contain the text; the area containing all the text of the web page must be a subtree in the DOM tree, and this The re...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More