

Tibetan historical document text line segmentation method based on baseline estimation
A technology of historical documents and baseline estimation, applied in the field of image processing, can solve the problems of inaccurate positioning and segmentation, inability to handle curved text lines, and only estimate the approximate position, etc., to achieve high segmentation accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
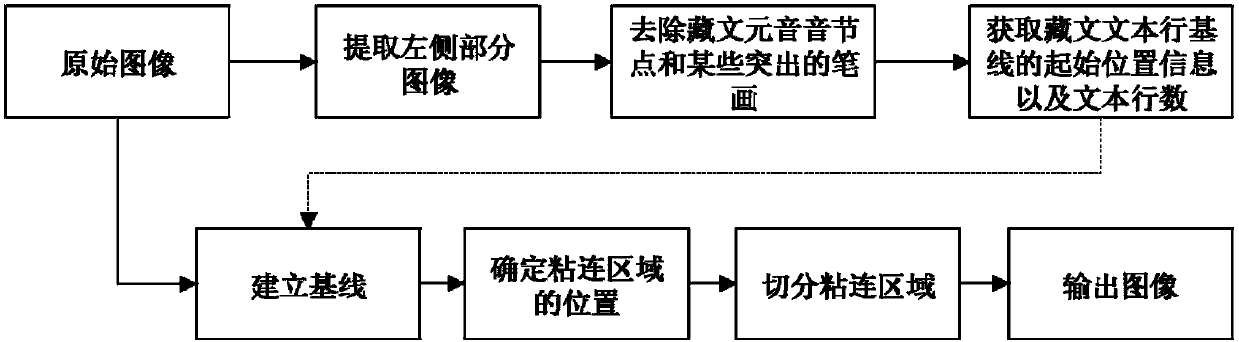
[0048] The flowchart of the method involved in the present invention is as figure 1 shown, including the following steps:
[0049] Step 1, extract the left partial image of the input image.
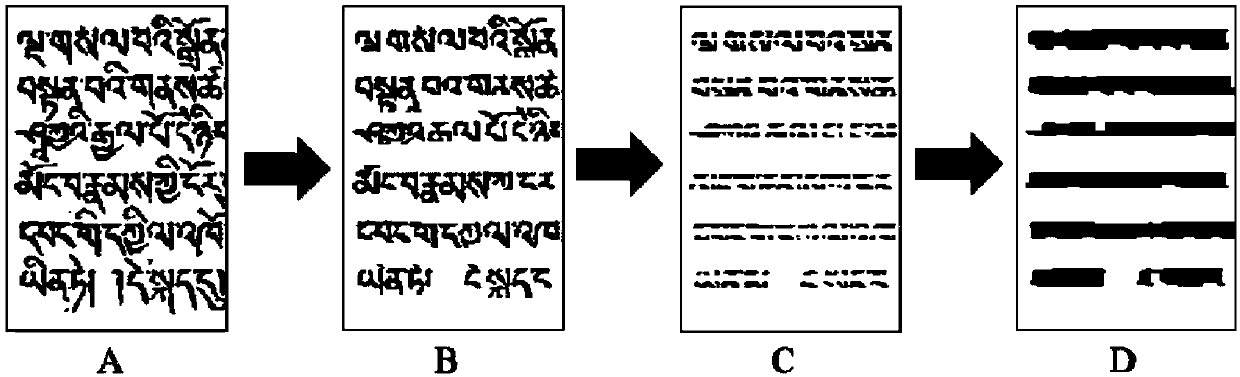
[0050] Extract the left 1 / 4 part of the image from the input Tibetan historical document image to analyze and extract the baseline position and line number of the text line, and name the image as image A.
[0051] Step 2, remove Tibetan vowel nodes and some prominent strokes.
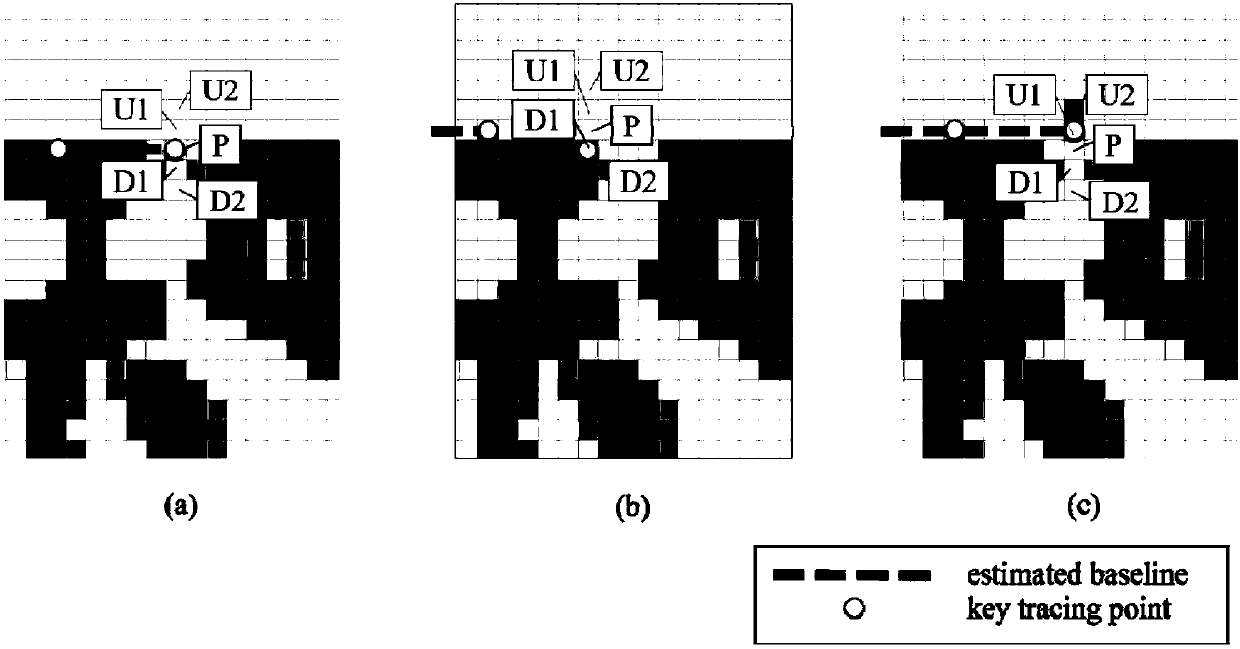
[0052] Divide the input image into image blocks through a sliding window of size N*M, where the width N is the width of the Tibetan character D in the image, and the length M is twice the width N. like figure 2 As shown in , select 80 image blocks with baselines at the top as templates, and use the principal component analysis (PCA) method to obtain their 13-dimensional feature...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More