

Text information extraction method and device, server and storage medium
A technology for text information and extraction methods, applied in instruments, special data processing applications, electrical digital data processing, etc., can solve problems such as low processing efficiency, incomplete and accurate keyword or abstract acquisition, and achieve the effect of improving processing efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
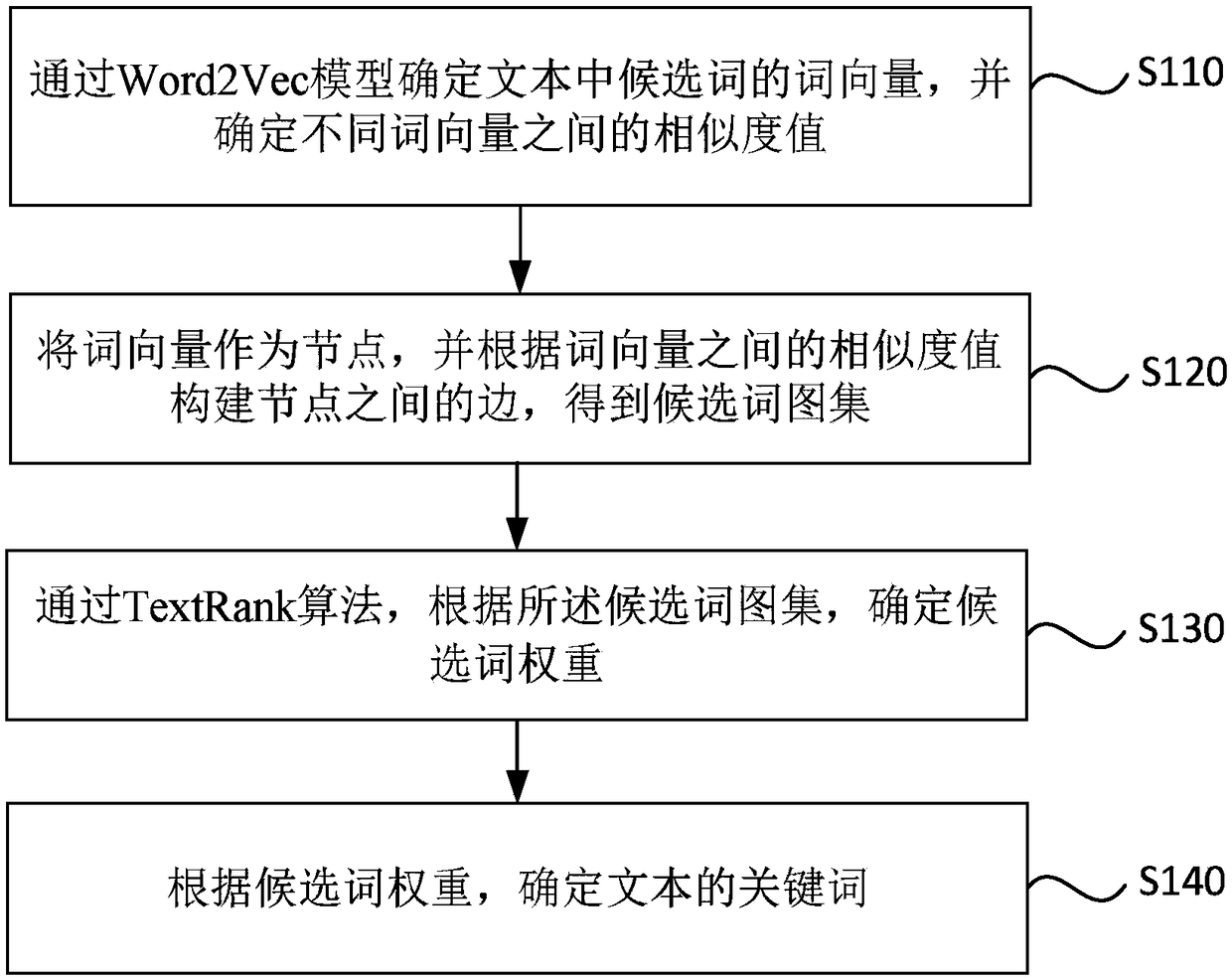
[0031] figure 1 It is a flowchart of a method for extracting text information provided in Embodiment 1 of the present invention. The technical solution of this embodiment can be applied to the situation of extracting key information such as keywords in text. The method can be executed by a device for extracting text information, which can be realized by software and / or hardware, and integrated into a server. The method specifically includes the following operations:
[0032] S110. Determine word vectors of candidate words in the text through the Word2Vec model, and determine similarity values between different word vectors.
[0033] Specifically, the text to be processed is crawled by a web crawler, where the text may be news text in different fields. Perform data cleaning on the text to be processed, remove non-text information in the text to be processed, such as punctuation marks, obtain plain text, and split the plain text into complete sentences. Use the word segmen...
Embodiment 2
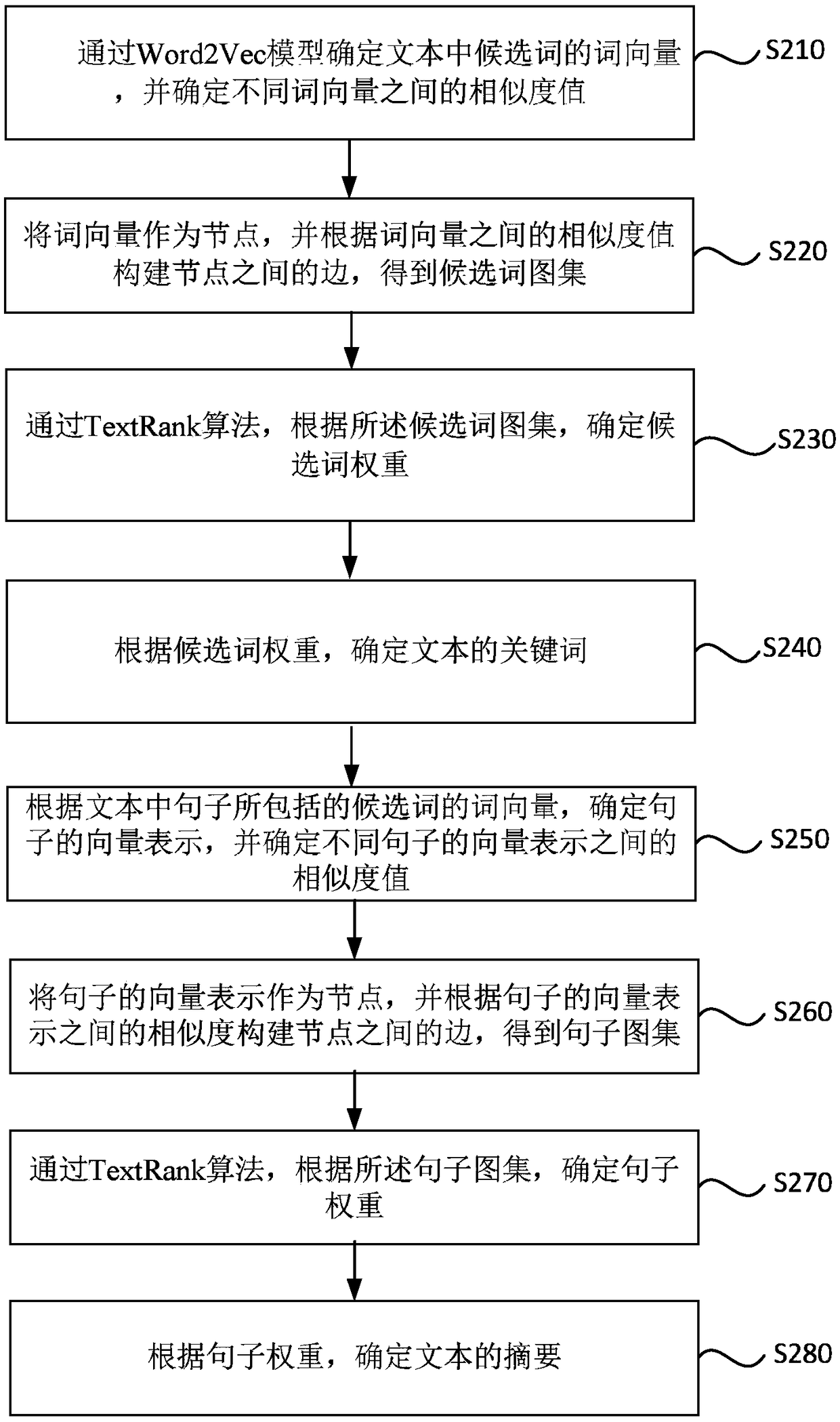
[0053] figure 2 It is a flowchart of a method for extracting text information provided by Embodiment 2 of the present invention. This embodiment is further optimized on the basis of the foregoing embodiments, and details not described in detail in this embodiment can be found in Embodiment 1. Such as figure 2 As shown, a text information extraction method provided in Embodiment 2 of the present invention specifically includes the following steps:
[0054] S210. Determine word vectors of candidate words in the text through the Word2Vec model, and determine similarity values between different word vectors.
[0055] S220, using word vectors as nodes, and constructing edges between nodes according to similarity values between word vectors, to obtain a candidate word atlas.
[0056] S230. Determine the weight of the candidate words according to the candidate word atlas through the TextRank algorithm.
[0057] S240. Determine the keywords of the text according to the candi...
Embodiment 3
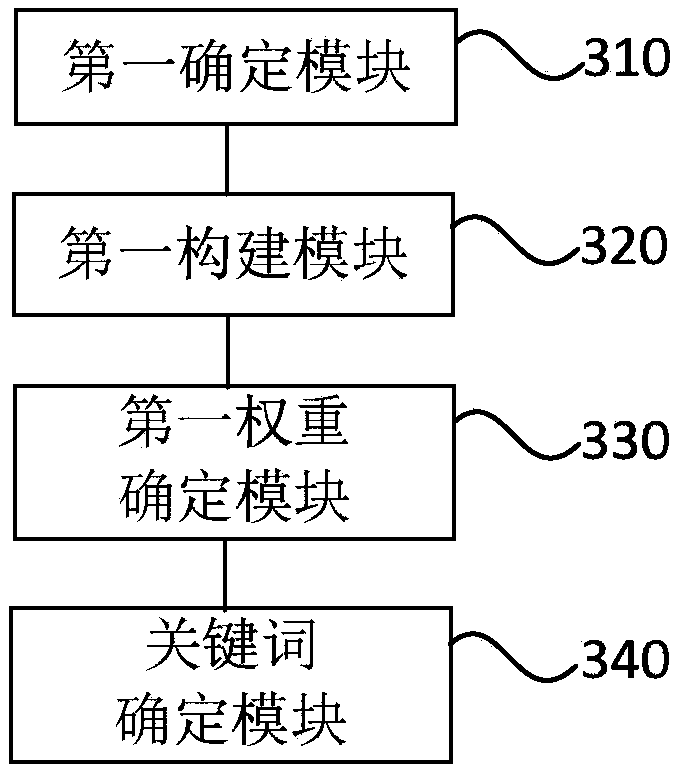
[0071] image 3 It is a schematic structural diagram of a device for providing text information provided by Embodiment 3 of the present invention. Such as image 3 As shown, the device includes:
[0072] The first determination module 310 is used to determine the word vector of the candidate word in the text by the Word2Vec model, and determine the similarity value between different word vectors;
[0073] The first building module 320 is used to use word vectors as nodes, and construct edges between nodes according to similarity values between word vectors, to obtain candidate word atlases;
[0074] The first weight determination module 330 is used to determine the candidate word weight according to the candidate word atlas through the TextRank algorithm;
[0075] The keyword determination module 340 is configured to determine the keywords of the text according to the candidate word weights.
[0076] Optionally, the first building block 320 is specifically used for:
[...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More