

A webpage text extraction method based on a logic link block
A technology of logical links and texts, applied in the computer field, can solve the problems of high HTML normative requirements and inability to handle the text of web pages well, and achieve the effect of high recall rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

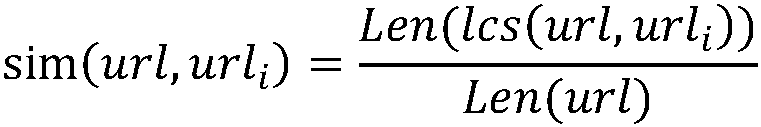
Examples
Embodiment Construction
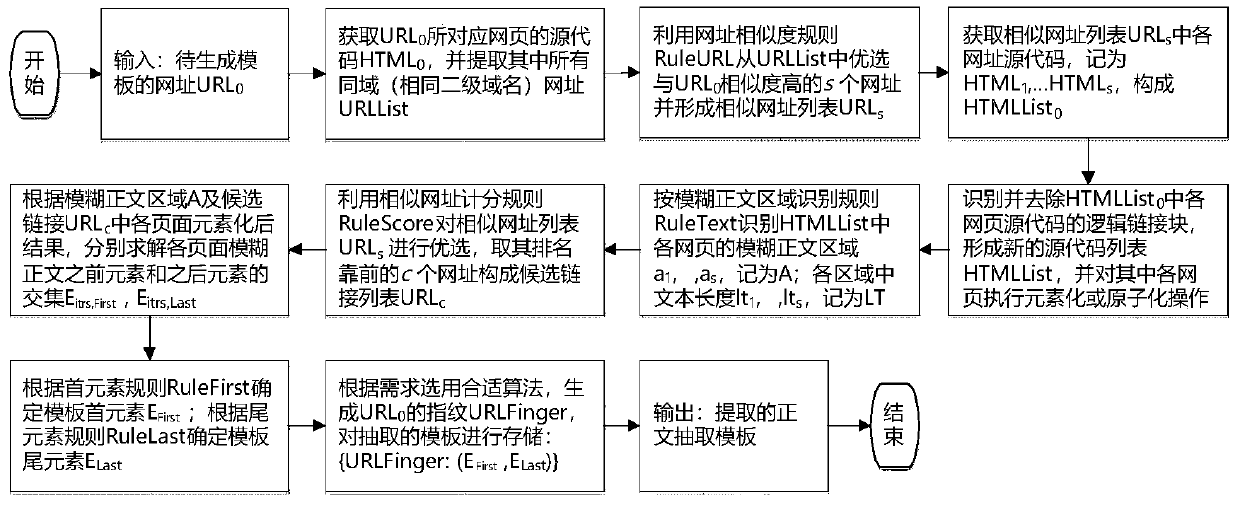
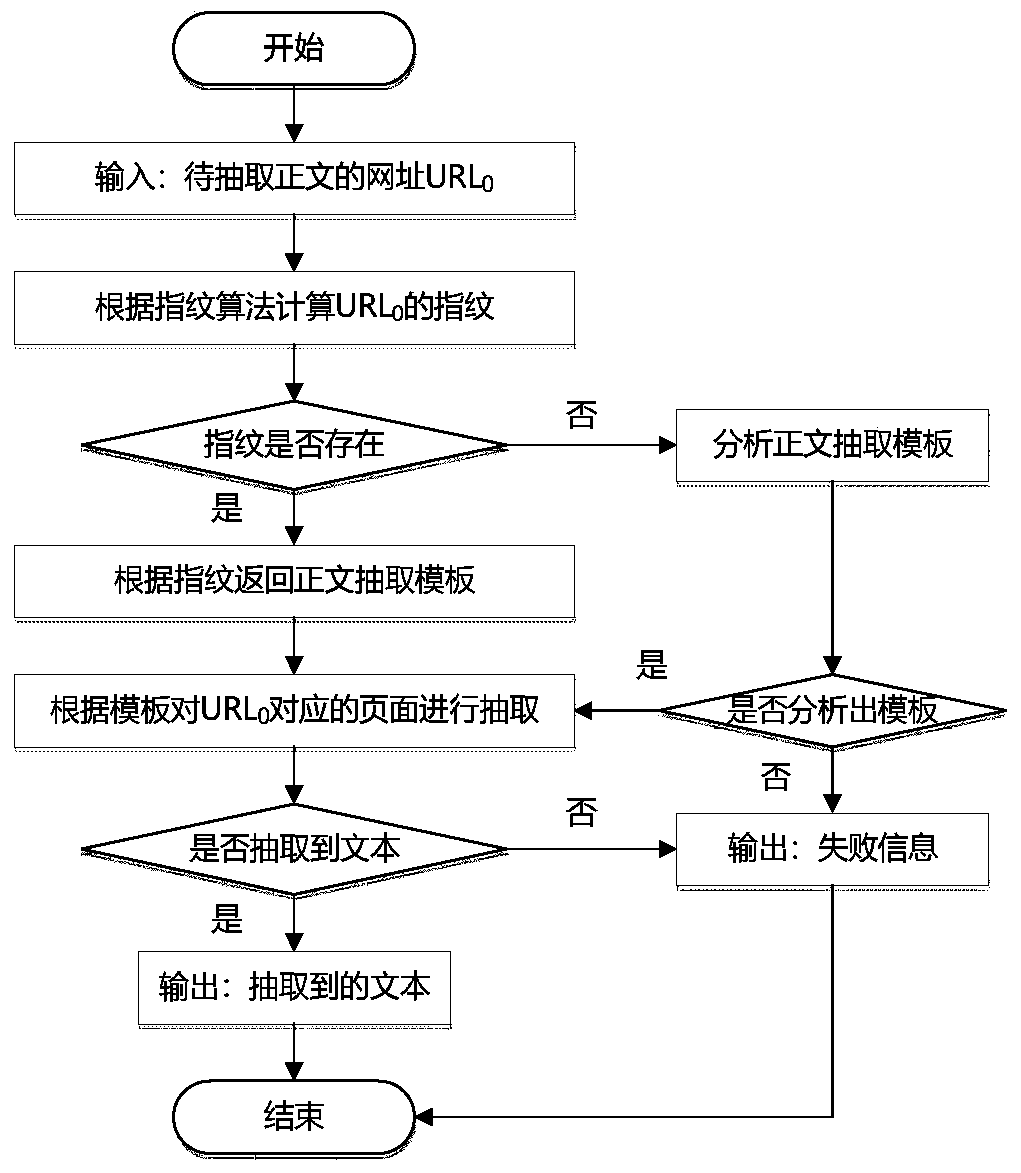
[0071] In order to facilitate those of ordinary skill in the art to understand and implement the present invention, the present invention will be described in further detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the implementation examples described here are only used to illustrate and explain the present invention, and are not intended to limit this invention.
[0072] Generally speaking, almost most websites, such as news, blogs and other types of websites, in their specific content details pages, except for the middle part of the webpage, which is mainly used to display the main content of the page, around the main content (usually in the main content The lower or right side of the website), there will also be a large number of related links, these related links are related page links matched by the website recommendation system or automatic matching program (for example, it may be called "related news", "recommende...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More