

A method and device for extracting information from pdf files
An information extraction and file technology, applied in the computer field, can solve problems such as the inability to filter out interference information such as catalogs and notes, and the inability to determine the attribution relationship of titles at all levels, so as to achieve automatic extraction, improve information extraction performance, and high extraction efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

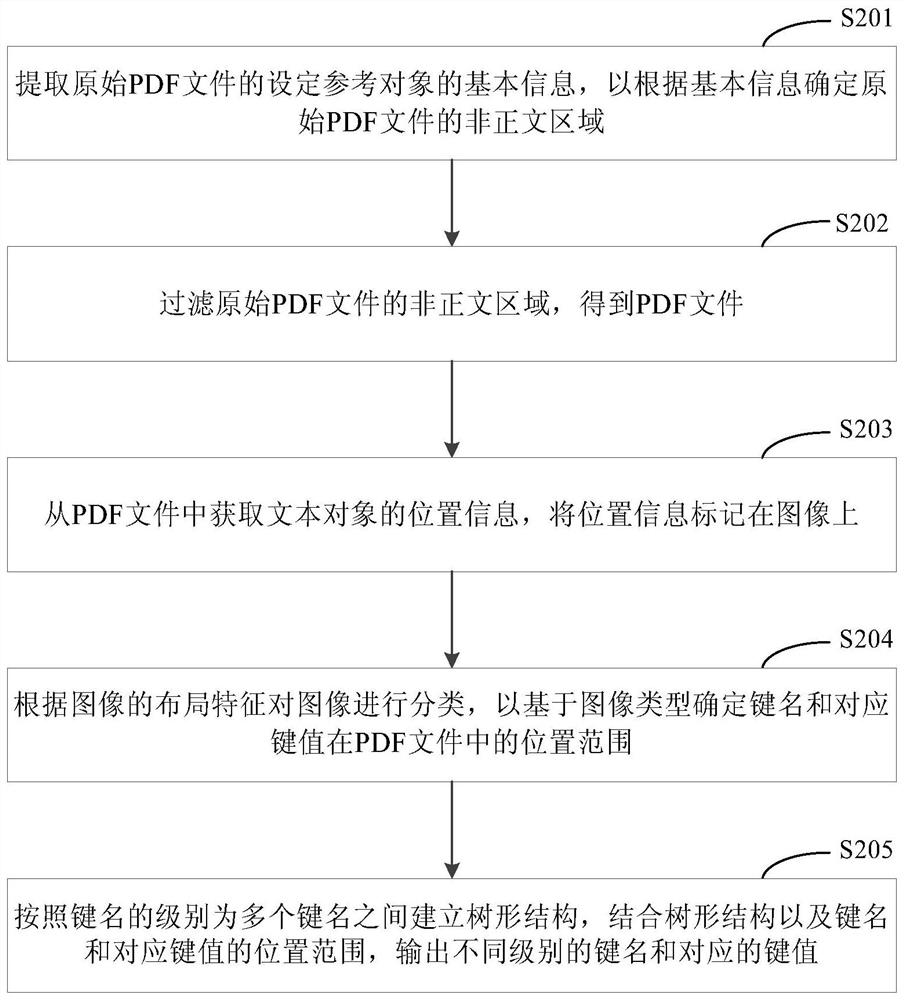

Examples
Embodiment Construction
[0040] Exemplary embodiments of the present invention are described below in conjunction with the accompanying drawings, which include various details of the embodiments of the present invention to facilitate understanding, and they should be regarded as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the invention. Also, descriptions of well-known functions and constructions are omitted in the following description for clarity and conciseness.
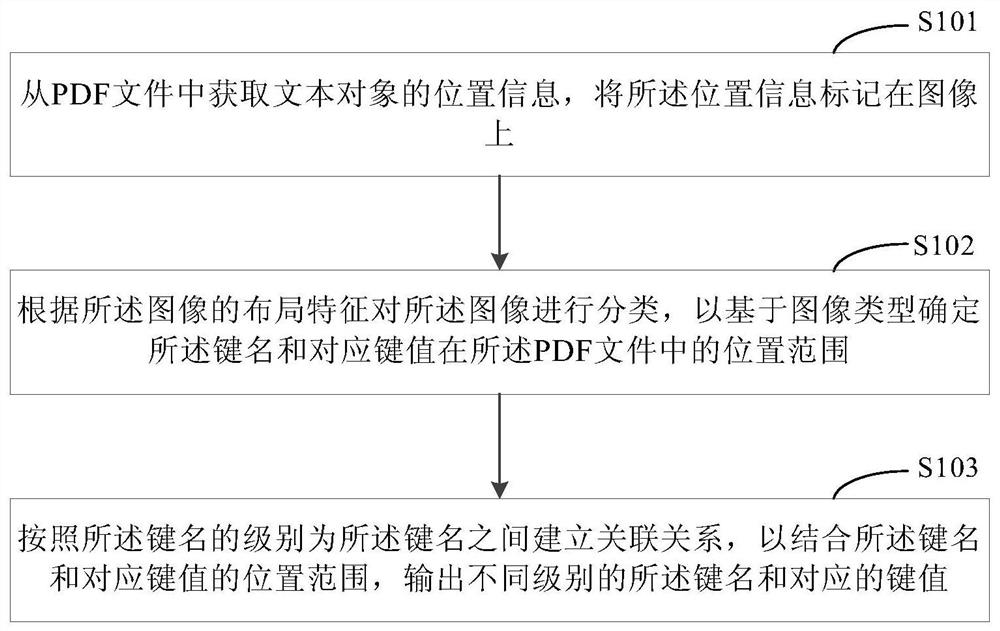
[0041] figure 1 is a schematic diagram of main steps of a method for extracting information from a PDF file according to an embodiment of the present invention. Such as figure 1 As shown, the information extraction method of the PDF file of the embodiment of the present invention mainly comprises the following steps:
[0042] Step S101: Obtain location information of a ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More