

File clustering method based on information bottleneck theory
An information bottleneck and document clustering technology, which is applied in electronic digital data processing, special data processing applications, instruments, etc., can solve the problems of difficulty in guaranteeing clustering accuracy and low time complexity, and achieves high accuracy and simple principle. , fast effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

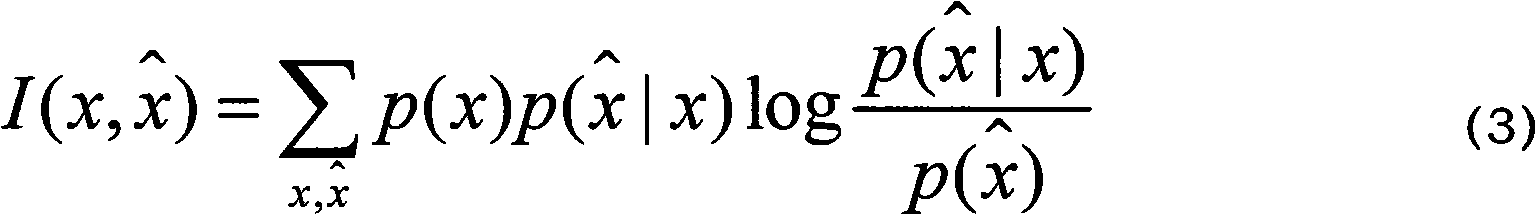
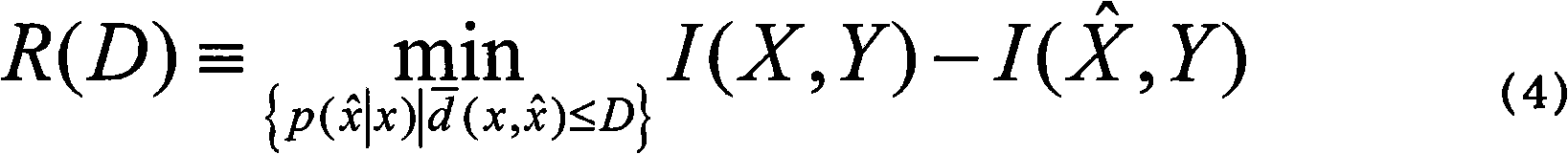
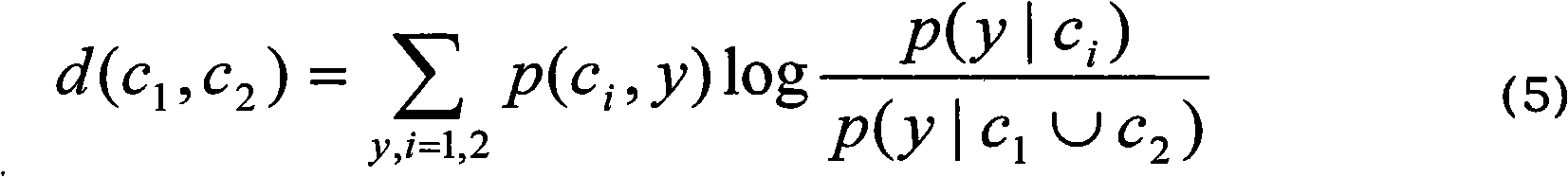
Examples
Embodiment Construction
[0020] The present invention uses the information bottleneck theory to calculate the "similarity" relationship between documents, and uses an incremental clustering algorithm to cluster the documents, which ensures that the method has a relatively low time complexity and is suitable for time performance For applications with higher requirements, at the same time, a sequence clustering algorithm is used to adjust the incremental clustering results to ensure that the clustering process can obtain high accuracy. A large number of experiments show that this method has better performance than classical clustering algorithms such as K-Means algorithm and AIB algorithm.
[0021] The present invention is a document clustering method based on the information bottleneck theory. On the one hand, the method utilizes the information bottleneck theory to calculate the similarity d between documents; The class result C; the processing steps in the clustering process are:
[0022] Step 1, us...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More