

Web text information extraction method
A technology of information extraction and text, applied in the direction of website content management, instrumentation, and other database retrieval, etc., to achieve the effect of fast extraction speed, good performance, and small memory usage
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
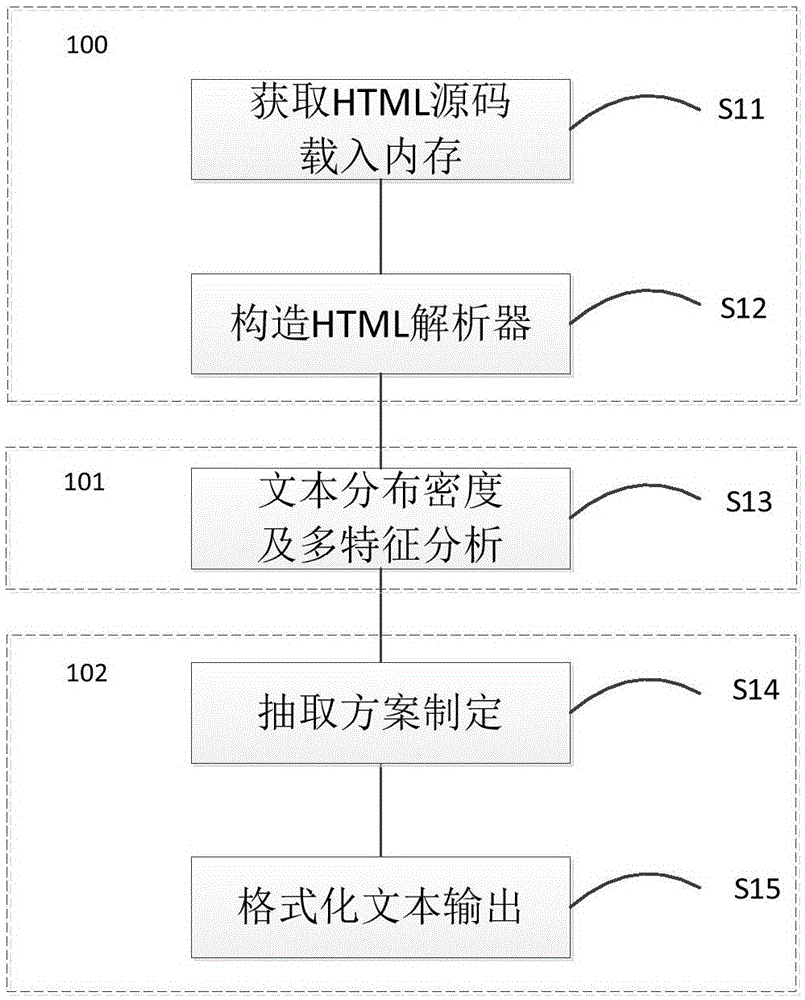
[0032] In order to further illustrate the technical means and effects that the present invention adopts to achieve the intended invention, the text extraction algorithm based on the text distribution density of the multi-featured webpage proposed by the present invention will be further described in detail below in conjunction with the accompanying drawings and specific implementation methods .
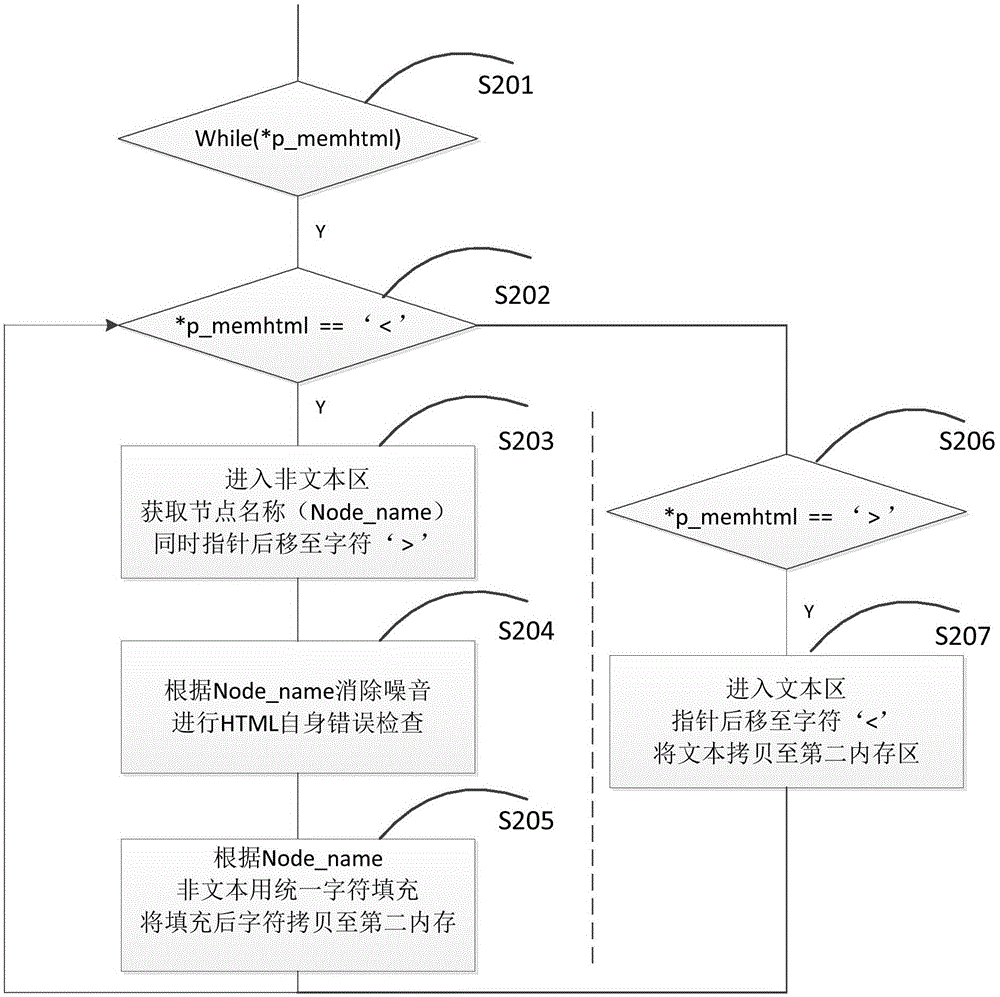
[0033] figure 1 Provided the overall frame diagram of the inventive method, press figure 1 As shown in the dotted box, the web information extraction algorithm includes three parts: an HTML source code pre-organization module 100 , a text density distribution algorithm application module 101 , and a follow-up text integration and output module 102 . The module 100 specifically includes an HTML source code capturing unit S11 and an HTML source code parsing unit S12; the module 101 relates to a specific algorithm example of the present invention; the module 102 includes a standard sele...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More