

Method and system for acquiring voice data
A voice data and voice technology, applied in the field of voice data acquisition, can solve problems such as no solutions have been proposed, achieve the effect of enhancing specificity and security, reducing training burden, and wide application range
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

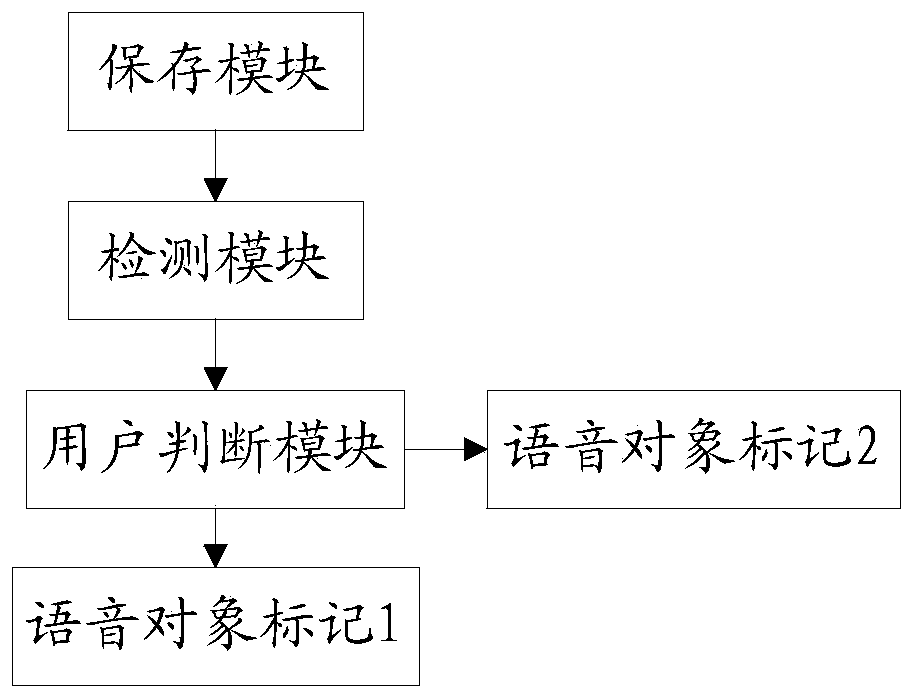
Examples
Embodiment Construction
[0029] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
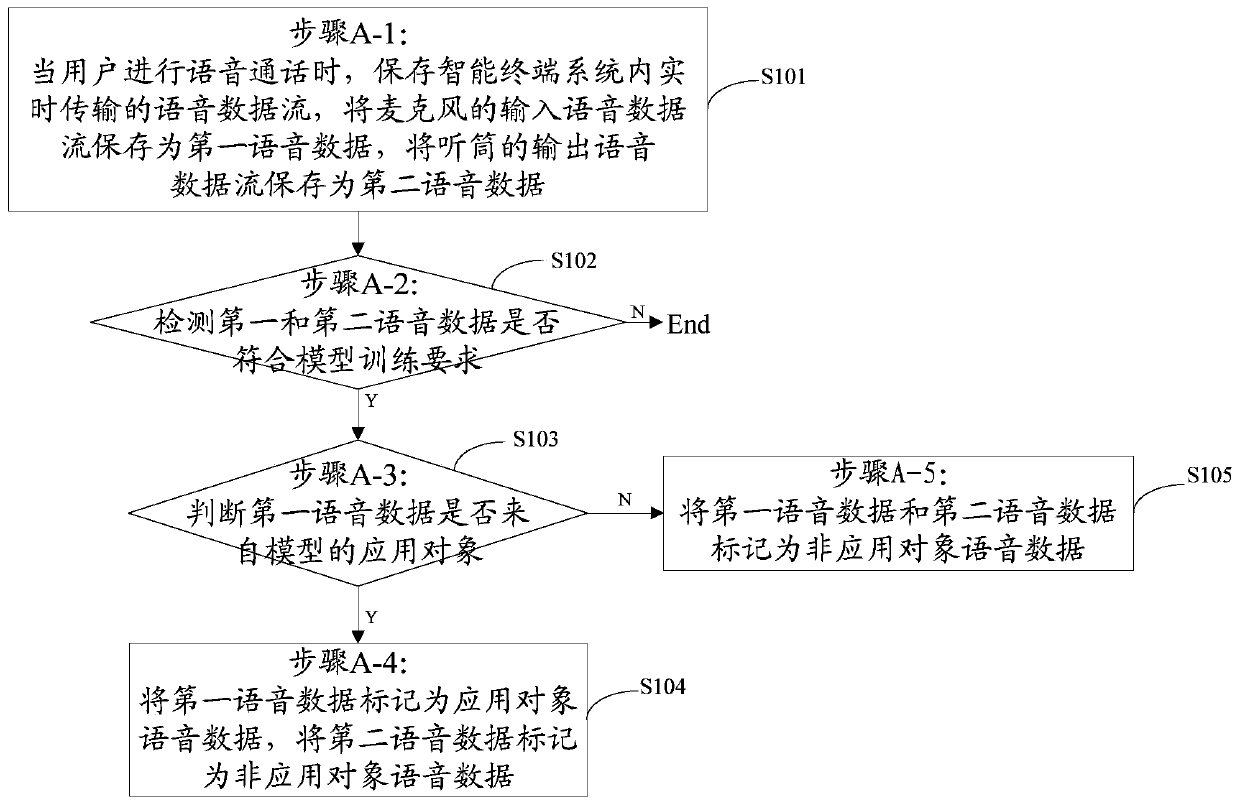
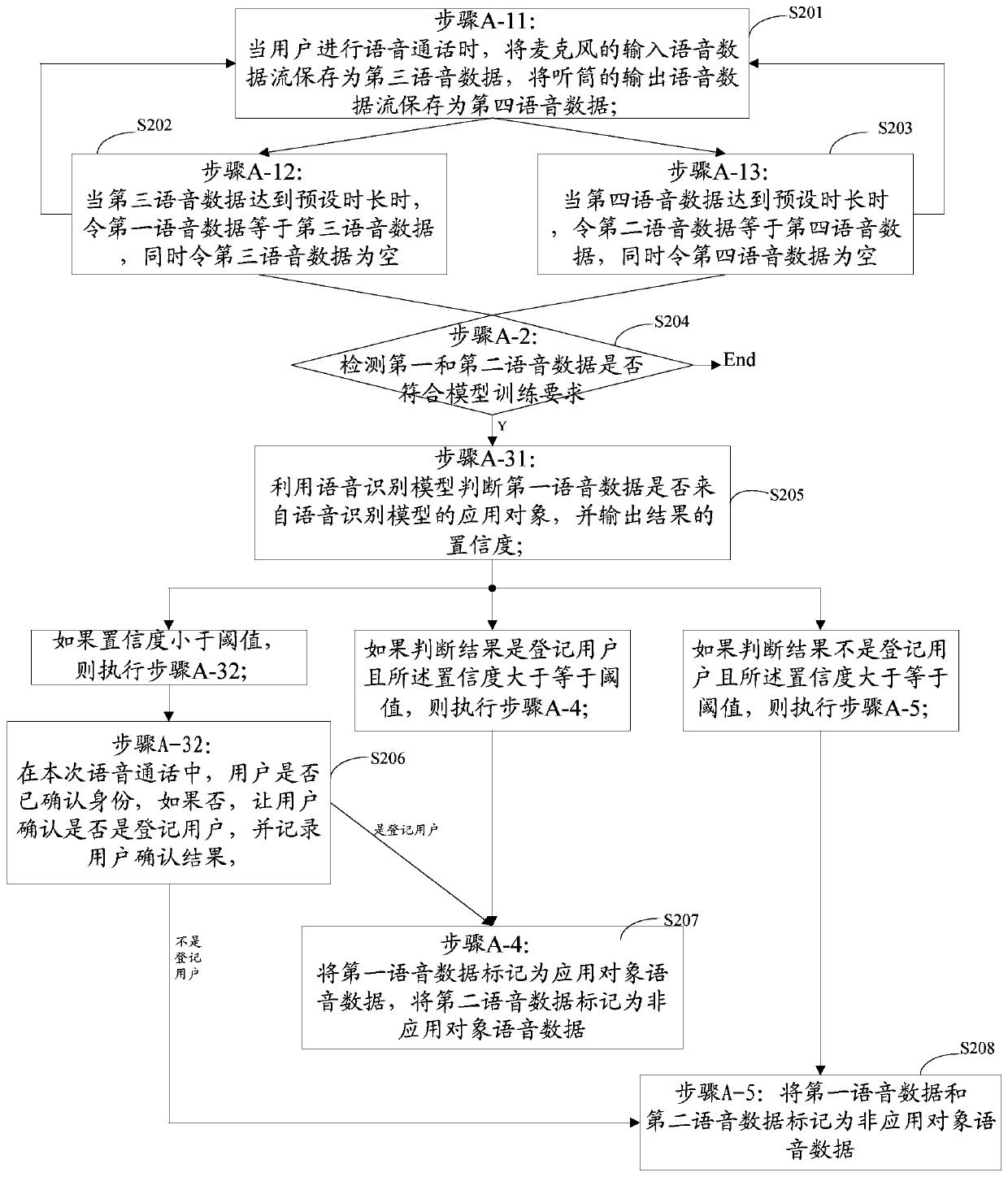
[0030] figure 1 It is a flow chart of the method for obtaining voice data of the present invention, comprising the following steps:
[0031] Step A-1 (S101): When the user makes a voice call, save the voice data stream transmitted in real time in the smart terminal system, save the input voice data stream of the microphone as the first voice data, and save the output voice data stream of the handset as second voice data;
[0032] Step A-2 (S102): Detect whether the first speech data and the second speech data meet the speech recognition model training requirements, if so, perform step A-3;
[0033] Step A-3 (S103): judging whether the first speech data is from the application object of the speech recognition model, if yes, execute step A-4, if n...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More